ディシジョンツリー(でぃしじょんつりー):情報マネジメント用語辞典
decision tree / DT / 決定木 / 意思決定ツリー / デシジョンツリー
意思決定の“決定”や命題判定の“選択”、物事の“分類”などを多段階で繰り返し行う場合、その「分岐の繰り返し」を階層化して樹形図(tree diagram)に描き表したグラフ表現、あるいはその構造モデル。
統計的決定理論、人工知能、機械学習、データマイニングなどの分野で、予測モデル構築、意思決定分析・最適化、分類問題の解決、概念・知識の記述、ルールの抽出・生成などに利用される。
意思決定理論の分野においては、意思決定と不確定条件によって分岐を繰り返す多重決定問題モデルを示したもので、プロセスと予測される結果を示す。決定理論(決定分析)の主要分析ツールである。
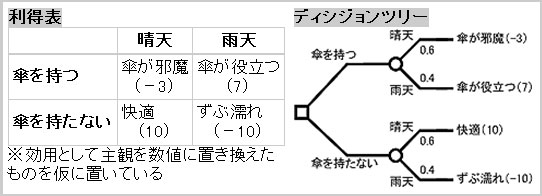 “傘を持つか持たないか”という決定問題を示す利得表(左)と、ディシジョンツリー(右)。事象が発生する確率(降水確率など)と、最終価値(この例では主観効用)が入手できれば期待値を算出し、最適経路を選択できる
“傘を持つか持たないか”という決定問題を示す利得表(左)と、ディシジョンツリー(右)。事象が発生する確率(降水確率など)と、最終価値(この例では主観効用)が入手できれば期待値を算出し、最適経路を選択できる知識工学や人工知能の分野においては、命題判定の繰り返しによる知識表現方法であり、エキスパートシステム構築の際などに使われる。データマイニングの分野においては与えられたサンプルデータ群をその属性変数の値から分類し、その繰り返しによってデータ全体を樹形モデルで表現する手法をいう。
ディシジョンツリーの原形は、ゲーム理論の「ゲームの木」だと見なされている。1950年代、数学者のエイブラハム・ワルド(Abraham Wald)博士がベイズ統計学にゲーム理論を統合して統計的決定理論(決定理論)を体系化したが、ゲームの木は2人のプレーヤー(意思決定者)による交互ゲームを表すツールである。これに対して、ディシジョンツリーは1人の意思決定者がもう1人のプレーヤーである“不確実性”と対峙するゲームを表すものと見なすことができる。
決定理論におけるディシジョンツリーは、意思決定者が取り得る選択行動と、相手(不確実性)の発生確率(主観確率)の分岐が多段にわたる際、これら分岐点を階層化して描いたもので、起こり得るすべての結論とそれぞれの期待値を算出し、期待効用が最大となる選択の経路(戦略という)を求める。
決定理論におけるディシジョンツリーは、一般のツリー(樹木図)と同様、根(root)から葉(leaf:分岐節・分岐点とも)が分岐する形で描かれる。分岐節には決定ノード、確率ノード、結果ノードがある。


確率ノード(chance node)
意思決定者がコントロールできず、他者・自然・偶然などによって決まる事象を示す。一般に円形で描かれる。シミュレーションを行う場合は、事前確率・主観確率によって表現する。機会事象ノード、偶然ノード、事象分岐ノードともいう。

最適経路選択には、ゲーム理論(ゲームの木)と同じく後ろ向き帰納(backward induction)が用いられる。これはすでに描かれたディシジョンツリー(問題構造)を結果ノードから分析していくもので、後述の人工知能分野でいう帰納推論とは異なる。また、理論決定の分野ではディシジョンツリーを使った意思決定分析の手法を「ディシジョンツリー分析」というが、後述のデータマイニングでいうディシジョンツリー分析とも異なる。
ディシジョンツリーはすべての結果を漏れなく書き出す(不要な枝を省略することも多いが)ので、より一般的には正事例を包含する概念記述と見なすことができる。利用範囲は意思決定・行動選択に限定されずに人工知能の分野では知識表現の方式として用いられた。
その人工知能の分野では、1980年代になってエキスパートシステムが実用化されるようになる。エキスパートシステムは知識ベース(その知識モデルはディシジョンツリーで表現される)に基づいて演繹推論を行うシステムだが、知識ベースにエキスパート(各分野の専門家)の知識を入力する作業は人手で行われていた。
この知識ベース構築の手間を削減するため、機械学習の分野で研究されていたディシジョンツリー学習の導入が提案された※。知識から結果を推論するのではなく、結果(未分類のデータ)から知識(ルール)を導き出す??帰納推論である。1983年には最初のディシジョンツリー生成アルゴリズムCARTが登場する。この分野はやがて巨大データを探索的に分析・分類する手法として、データマイニングの主要な方法の1つに数えられるようになった。
※ディシジョンツリー自動生成の指摘そのものは1960年代からあった。また今日、主要なディシジョンツリーアルゴリズムに数えられるCHAIDの基となったAIDの登場は1963年だが、これはもともと変数間の関連を統計的に検出することを目的とするものだった
機械学習、データマイニングにおけるディシジョンツリー分析は、一定の規則(アルゴリズム)によって自動的にデータを分類していくものである。簡単に説明すると、対象データ全体を最もよく分類できる属性変数を探索し、それに従った分類されたデータ群にもそれぞれまた最も分類効率の高い属性変数を探索するという作業を繰り返し、分類できなくなるまで分岐を行う。分類の仕方はアルゴリズムによって異なる。著名なアルゴリズムにCARTやCHAID、ID3/C4.5/C5.0などがある。
データマイニングでは、目的変数が質的変数(カテゴリ変数)の場合は分類木、量的変数(連続変数)の場合は回帰木ともいう。
ディシジョンツリーの形状は、決定分析では右に向かって、データマイニングでは下に向かって成長する形に描かれることが多い。分岐がイエス/ノーの2つである2分決定木(binary decision tree)が基本形だが、用途によっては分岐が3つ以上ある決定木や分岐数や深さがさまざまな混合木などが使われる。ツリー図なのでループは含まない。
ディシジョンツリーの利点は、if-thenルールとして透過的に表現されるので意思決定や学習の過程が分かりやすく、分析結果の評価・解釈がしやすいことが挙げられる。
ただし、命題数が増えるごとに結果の数が等比級数的に増大するので、問題が複雑だと巨大で複雑なツリーが生成されることになる。これを補うためインフルエンス・ダイアグラムが提唱されている。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 爆売れだった「ノートPC」が早くも旧世代の現実
- VPNやSSHを狙ったブルートフォース攻撃が増加中 対象となる製品は?
- 生成AIは検索エンジンではない 当たり前のようで、意識すると変わること
- HOYAに1000万ドル要求か サイバー犯罪グループの関与を仏メディアが報道
- ランサムウェアに通用しない“名ばかりバックアップ”になっていませんか?
- 大田区役所、2023年に発生したシステム障害の全貌を報告 NECとの和解の経緯
- 「Gemini」でBigQuery、Lookerはどう変わる? 新機能の詳細と利用方法
- PHPやRust、Node.jsなどで引数処理の脆弱性を確認 急ぎ対応を
- 標的型メール訓練あるある「全然定着しない」をHENNGEはどう解消するのか?
- 攻撃者が日本で最も悪用しているアプリは何か? 最新調査から見えた傾向
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。