Unicodeでも発生する文字化けの危機と回避:XMLを学ぼう(6)
漢字やひらがななど、数多くの文字を持つ日本において、文字化けはいまだに避けて通れない問題だ。XMLでは、こうした文字化けを防止するための仕組みが備わっているが、それでもなお完全に封じ込めることはできていない。その理由について解説しよう。
文字化け防止ルールを持つXML
XMLは、安全かつ安定した情報交換の手段として利用できることを目的にした、よく考えられたメタ言語である。XMLより以前のSGMLなどと比較して、格段の進歩が見られる。例えばSGMLでは、SGML文書を記述するためにどんな文字コード系を使用するか、標準的な規定が何もなかった。そのため、あるSGML文書が、ほかのシステムで正常に読めるかどうか、何の保証もなかったと言ってよい。これに対して、XMLでは文字コード系に関しても明確なルールを導入することで、交換性を保証するようになっている。これは、不特定多数の利用者が相互に情報を交換する時代には不可欠な条件といえる。
ところが、このような進歩にも関わらず、XMLを用いた情報交換には文字化けの危険が存在するのである。今回は、XMLが従来の情報交換言語に対して、いかに文字化けを防止するために進化したのか。そして、それにも関わらずどんな危険が存在するのか。それを回避するにはどうしたらよいかを解説する。
文字化け問題の歴史
パソコン業界で文字化け現象なるものが最初に大きな問題として認識されたのは、1983年の「JIS X 0208」改正の後のことだと思われる。これは筆者も直接体験したことがある。当時人気の高かったNEC製のパソコンと、やはり当時人気の高かったエプソン製のプリンタを接続したときに、画面上に表示されている文字が印刷できない、あるいは、違う文字が印刷されてしまうという現象に遭遇した。この現象そのものは、エプソン製プリンタに、NEC製プリンタをエミュレートするROMカートリッジオプションを入れることで収まった。だが、なぜ、こんな問題が起きたのだろうか?
■文字化け問題の出現
JIS X 0208というJIS規格は、第1水準、第2水準と呼ばれる主要な日本語文字を規定する規格だが、1983年の改正において、いくつかの文字の追加と、既存の文字表内の文字の位置の交換が行われている。この結果、1983年以降の規格に準拠した製品と、それ以前の規格に準拠した製品では、同じコードが同じ文字を指し示していない状況が発生した。上記の例では、パソコン本体は1978年規格、プリンタは1983年規格のそれぞれ準拠したために、文字化けが生じていたのである。
もう1つ、ここで発生した文字化けには、機種依存文字という問題も含まれる。パソコン本体で表示できるのに、印刷はできない文字が発生したというのは、パソコン本体にメーカー独自に定義した文字が含まれているのに、別メーカー製のプリンタにはそれが含まれていなかったという事実によるものだ。
この時点で、機種依存文字が文字化けを引き起こす、という問題はそれほど重要なことだとは思われていなかった。要するに、プリンタに、パソコン本体と同じメーカーのプリンタをエミュレートするオプションを追加すれば解消されるのである。幸運というべきか、不幸というべきか、この当時の日本人は、パソコンをネットワークするという発想を知らず、モデムすらパソコンショップでは販売されていなかったのである。そのため、パソコンとプリンタは1対1で接続され、ネットワーク経由で他のパソコンから受け取ったデータを打ち出すこともなかった。そのため、自分の使っているパソコンとプリンタの仕様さえ一致させれば、それで問題は解決できたのである。
■ネットワーク化による相違の顕在化
ところが、ある出来事をきっかけに、これらの文字化け問題は再び燃え上がる。それは、通信回線に関する規制緩和によって起こった。いわゆるパソコン通信ブームである。パソコン通信によって不特定多数の利用者がメッセージを交換するようになると、否応なしに、「我々は同じ文字を共有していない」という事実を痛感させられることになる。この結果として、パソコン通信では、交換性に問題のある文字を使わないというマナーが確立されていく。
パソコン通信で噴出した文字化け問題はこれだけではない。まず、日本には、多くの互換性のない文字コード系が存在するという事実が明らかになった。要するにメーカごと、OSごとに互いに互換性のない文字コード系を使用しているということである。それぞれ、JIS X 0208という共通の文字集合を使っているにも関わらず、具体的なビットの並べ方のルールに互換性がなかったのである。これまでパソコンをネットワークするという発想がなかった日本では、当然の成り行きといえば、その通りであった。もし、文字コード系に互換性がないパソコン間で通信を行うと、まったく意味不明のでたらめな文字列が受信されてしまうことになる。しかし、ネットワークするという甘い蜜を知ってしまった利用者は、もう後戻りはできない。パソコン通信用の通信ソフトでは、何種類もの文字コード系を切り替えて利用可能にするのが一般的であり、サービス提供側が複数の文字コード系を選択可能とすることもあった。
■文字コード選択を間違うと…
以下は実際に、秀丸エディタで「わざと」文字コード系の選択を誤ってファイルを読み込んでみた。互換性のないシステム間で何も工夫せず情報交換を行うと、こういう事態が起きるという一例である。
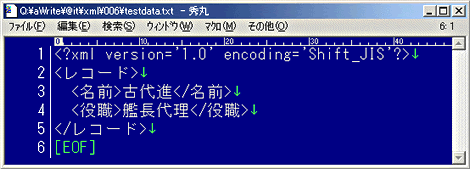 上記はシフトJISのファイルを読み込んだ場合。正常に表示されている。
上記はシフトJISのファイルを読み込んだ場合。正常に表示されている。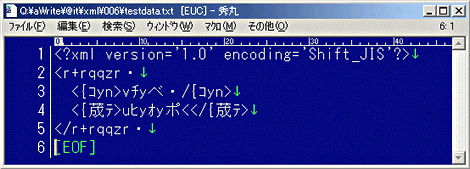 上記は、同じファイルを日本語EUCとして読み込んだ場合。
上記は、同じファイルを日本語EUCとして読み込んだ場合。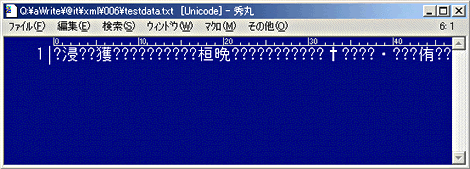 上記は、Unicode(UTF-16)として読み込んだ場合。
上記は、Unicode(UTF-16)として読み込んだ場合。このような文字化けが起きる根本的な理由は、特定メーカー内で閉じた技術体系を利用して、不特定多数の通信を行おうとしているためだと言える。しかし、インターネットブーム以後、ネットワークが社会基盤として位置づけられている今、特定メーカーの製品でしか機能しないようなハードやソフトは、時代にそぐわない。
■文字化け問題を解決する?Unicodeの誕生
この問題に対処する1つの「正義」は、「世の中で使用されている文字コード系はすべて利用可能とすべき」というものだ。しかしながら、このような正義が現実のソフトウェアとして結実しているとは言い難い。実際に、どんな文字コード系でも読み書きできるソフトウェアなど、限りなく皆無に近い状況と言える。そのようなソフトウェアは開発するためにとてつもなく多くの工数を必要とし、その上、利用者にも高度な使いこなしの技術を要求する。文字コード系の範囲を日本だけでなく世界に広げるなら、本当に正しく処理できているかをチェックするために、全世界で使われる言語を理解している人材を揃える必要もあるが、これは現実的とは言えない。
現実的な解決策は、すべての文字コード系を利用可能にすることではなく、世界で1つしか存在しない標準コード系に統一していくことである。この方法は、すべての利用者が使用する文字コード系を変更することになり、一見現実的ではないように見える。しかし、すべての文字コード系を理解するようにすべてのソフトウェアを変更することに比べると、はるかに手間やコストは小さくて済むのである。この目的のために作られた文字コード系を、「Unicode」という。UnicodeはUnicodeコンソーシアムという私的な団体が作っているものだが、これと同等のものを国際標準団体であるISOとIECが規格化したものがあり、これを「ISO/IEC-10646」という。これは日本においては、「JIS X 0221」というJIS規格として翻訳成立している。
Unicodeの成立を受けて、近年の最新標準の多くは、Unicodeを採用している。例えば、プログラミング言語のJavaやWindows NT/CEのような新しい世代のOSなどがUnicodeを扱うことを前提に設計されている。これらは、Unicode以外の文字コード系はすべて一度Unicodeに変換した上で扱うという方針を取っており、入口と出口を除けば内部はすべてUnicodeで処理される。XMLも、まさにこのような流れの中に位置する技術であり、これらと同様に、Unicodeを前提に設計されている。
XMLにおける文字化け回避のメカニズム
XMLには、いくつかの段階の文字化け回避メカニズムが存在する。
■Unicodeサポートの義務化
最初に特筆すべきことは、Unicodeの採用と、そのサポートの義務化である。人は皆、メーカーも利用者もこれまでの慣習の継続を無意識に望むものである。そのため、いくらUnicodeに統一しようと言ったところで、現実には「総論賛成各論反対」ということに陥りやすい。そこで、情報交換用の標準規格の現場でも、きちんとポリシーを持って取りかからねば、なかなかUnicodeの利用を認めるところまでは行けても、Unicodeのサポートを義務とするところまでは行けない。
もちろん、XMLがUnicodeを義務としたことに、反発がないわけではない。しかし、XMLが一種のすがすがしさを持つのは、一切の特例を認めなかった点である。米国を中心に世界の標準とも言えるUS-ASCIIコードすら、XMLでは標準の一部として認められていない。US-ASCIIが認められていない以上、それよりも国際的利用頻度の低い各国のコード系が、標準と認めろとは言い出せない雰囲気がある。これにより、米国にだけ有利ということはない、国際的に平等な情報交換用のメタ言語に、XMLはなることができたのである。
より具体的に言えば、XMLを処理するソフトウェアは、Unicodeの情報交換用のフォーマットである「UTF-8」と「UTF-16」を必ずサポートしなければならないと決められている。その結果、UTF-8とUTF-16のどちらかを使用すれば、文字コード系の食い違いによる文字化けを起こさずに処理できるのである。この偉大な一歩によって、UTF-8とUTF-16のどちらかを採用することができれば、ほとんどの難しい問題と別れを告げることができるのである。どんなXMLソフトウェアでも、この2つは出力でき、そして、入力もできるのである。いちいち、相手がどんなソフトを使っているか確認する必要もない。唯一の懸念事項は、UTF-8とUTF-16を取り違えて処理することによる文字化けである。しかし、このような間違いは、テキストの先頭にBOM(Byte Order Mark)と呼ばれる印を付けることで判断ミスを自動チェックすることができる。また、万一間違った場合でも、この2つは大きく異なるため、一部の文字は正しく読めるというような事態は起こらず全ての文字が化ける。そのため、間違ったことに気付かずに作業を進めると言うことは、少なくとも人間が目で見てチェックするとしたら、あり得ない事態と言える。
■使用文字コードの明示
さて、「すべてUTF-8またはUTF-16を使用すれば」という前提は、まだUnicode時代への過渡期にある現在では実行するのが辛いという現実もある。既存のソフトのうち、Unicodeに対応していないものも多い。使い慣れたテキストエディタでXML文書を作成しようと思ったけれど、UTF-8にもUTF-16にも対応していない、というケースもあるだろう。こういったさまざまな事情に対応するため、XMLではUnicode以外の文字コード系(例えばシフトJISや日本語EUC)の使用も認めている。ただし、これは「認めている」のであって、「保証」しているわけではない。保証されるのはUTF-8かUTF-16だけである。つまり、世の中にあるXMLアプリケーションソフトの中には、UTF-8とUTF-16以外の文字コード系を処理するものがあってもよいが、すべてのXMLアプリケーションソフトが、これ以外の文字コード系を扱う義務はないということである。そのため、UTF-8とUTF-16以外の文字コード系でXML文書を扱いたい場合は、あらかじめ使いたいXMLアプリケーションソフトが、その文字コード系をサポートするかどうかを確認をする必要がある。もちろん、確認がとれない場合は、使うべきではない。
ここで問題になるのは、いったいどんな文字コード系でXML文書を書いたのか、それを判定する方法である。これが簡単な手段で判定できないと、文字化けの悪夢が容易に再来してしまう。HTTPを用いた通信(URL/URIで「http:」で始まるもの)では、本来、本文に先立って送信されるhttpヘッダーと呼ばれる箇所で、文字コード系を明示するのが正しいやり方である。この話題は、W3Cの XMLワーキンググループのメンバーである村田真氏や、国際化の専門家である慶 應大学のMartin J. Durst氏などによる労作である「charsetパラメタの勧め: HTMLにおける文字符号化スキームの明示方法」で詳述されている。しかし、HTTPを使わない場合、例えばローカルのハードディスク上でXML文書を扱う場合などは、この方法は使えない。そこで、XML文書の最初の1行に記述できるXML宣言の中に、文字コード系の名前を記述するという方法を採ることができる。
例えば、シフトJISで記述されていることを明示して文字化けを回避するには、以下のように記述する。
<?xml version='1.0' encoding='Shift_JIS'?>
encoding=の後に書かれたものが、文字コード系の名前である。シフトJISはShift_JISと記述する。日本語EUCはEUC-JPと記述する。名前をくくる記号は、ダブルクオート(")でもシングルクオート(')でも、どちらを使っても構わない。
ここに記述することが許されている文字コード系の名称は、IANA (Internet Assigned Numbers Authority)で管理されているCHARACTER SETSという文書に登録されているものか、あるいは、「x-」の2文字で始まる名前に限られる。IANAに登録されている名前は、基本的に、それをサポートしたXMLアプリケーションソフト間では情報交換に利用できると考えてよいだろう。「x-」の2文字で始まる名前は、誰でも自由に名前を付けることができるが、交換性はまったく期待できない。その上、それをサポートしたXMLアプリケーションもほとんど存在しない。「x-」の2文字で始まる名前は、よほど特殊な状況でもなければ出番がないと思って間違いないだろう。
■文字コード指定の限界と注意点
このような方法で、Unicode以外の文字コード系を使用する場合に注意すべき点が2つある。1つは、XML宣言で「encoding=」を記述する方法は、何らかの形でUS-ASCIIコードと互換性のある文字コード系に限られるということである。つまり、まずXML宣言を構文解析できねば、名前を取り出すことができないため、XML宣言はUS-ASCIIコードと仮定されて、チェックされるのである。例えばシフトJISは、半角英数文字の範囲に関しては、一部記号を除き、US-ASCIIコードと互換性があるので、このチェックを通る。しかし、US-ASCIIから遙かにかけ離れた文字コード系(例えば、IBMのEBCDICなど)は、このチェックを通らないかもしれない。
もう1つの注意点は、XMLが、XMLの仕様の中で利用可能な文字の範囲をUnicodeで規定している点である。この定義の結果として、どんな文字コード系を使った場合でも、文字の妥当性のチェックは、Unicodeのコード値を前提に行われねばならないことになる。このことは、裏を返せば、Unicodeに収録されていない文字は、どう逆立ちをしても、XML文書中に記述できないということを示す。現実的なXMLアプリケーションソフトの実装から考えても、Unicodeに収録されていない文字を処理するのは困難である。なぜなら、XMLアプリケーションソフトは、どんな文字コード系でXML文書を受け取った場合でも、一度Unicodeに変換してから処理するのが一般的である。そのため、Unicodeに変換できない文字があると、それは処理対象とすることができない。このような状況から、XMLで使用できるUnicode以外の文字コード系は、Unicodeに変換できる(つまりすべての文字がUnicodeに収録されている)ことが条件となる。この条件を満たさないものとして、2000年10月現在としては、いわゆる第3水準、第4水準と呼ばれる「JIS X 0213」が存在する。JIS X 0213に収録されている文字の中で、Unicodeにない文字は、現在Unicodeに収録すべく作業中であると言われている。この作業が完了し、公式にUnicodeに収録されて、Unicode上の文字コードが確定すれば、JIS X 0213を用いてXML文書を書くことが可能になる。
JIS X 0213に関しては、事前にこのような問題が起きることが明らかであったにも関わらず、強行的にJIS規格とされたことが悔やまれる。現時点でXMLとJIS X 0213は両方を同時に採用することはできない点に、XML利用者は十分に注意されたい。もし、どうしてもJIS規格でなければならない、という状況であるようなら、JIS X 0213ではなく、JIS X 0221(つまり、Unicodeと同等と見なせるもの)の採用を提案する必要がある。
Unicodeでも新たなる文字化けが
ここまで見てきたように、XMLではUnicode登場以前に知られている文字化け問題に関しては、ほぼ完璧に対策を打っていることが分かる。ところが、XMLは完全に文字化け問題から解放されていないことが判明したのである。
この問題の詳細は、JIS TR X 0015:1999 XML 日本語プロファイルに述べられている。要するに、Unicodeの登場以前には存在していなかった新しいタイプの文字化け現象が出現したということである。そして、Unicodeをシステムの内部処理にのみ使用し、情報交換に使用しない間には顕在化しなかった問題とも言える。そういう意味で、XMLが初めて問題を明らかにしたものだと言える。
■Unicodeに潜む文字化けの芽
この問題の性質を理解するには、Unicodeという文字集合の作成方法を知る必要がある。Unicodeは、全世界の文字コード系を集めて、それに収録された文字をすべてリストアップして整理して作られた。この方法なら、Unicodeの元になったすべての文字コード系にあったすべての文字は、Unicodeに収録されていることが保証される。ところが、である。確かに、足りない文字はないのだが、よく似た文字が複数収録されていて、区別を付けにくい、という状況が起こってしまったのだ。例えば、横棒の記号の一種であるダッシュ(-)だけでも、何種類も微妙に異なるバリエーションが収録されているのである。さらに困ったことに、どの文字が元の規格のどの文字に対応するか、明確な情報が残っていないのである。漢字に関しては幸いなことに、いろいろ騒動があったため、Unicodeの規格書に元規格との関係が記されているのだが、それ以外の文字に関しては、そのような情報が存在していないのである。
この結果として、主に記号類に関して、元規格とUnicodeの間で、どの文字とどの文字が対応するのか、人によって解釈が違うという現象が起きてしまった。そして、その解釈の違いが解消されないまま、それぞれのメーカーはUnicodeを自社ソフトに組み込む作業に着手した。従来からある資産を活用するために、従来型の文字コード系とUnicodeの間で文字コード変換を必要とするので、当然、変換ルールを記述した変換テーブルというものが作成される。ところが、変換ルールが人によって解釈が違うため、できあがった変換テーブルはメーカーごとに中身に相違があるという事態が生じてしまったのである(具体的な相違点を知りたい方は、筆者の調査結果が公開されているので参照願いたい)。
このような状況は、XMLにもストレートに反映されている。変換テーブルが何種類もあるということは、XMLアプリケーションソフトが使用する変換テーブルも一定していないということだ。つまり、シフトJISのような従来型の文字コード系でXML文書を書いた場合、使用するXMLアプリケーションソフトの種類によって、処理結果が異なる可能性があると言うことだ。
例えば、XMLパーサのような同じ機能を持ったソフトウェアが複数ある場合、本来なら同じXML文書を入力すれば、同じ出力が出てくることが期待される。ところが、上記のような状況があるため、同じXML文書を入力しても、結果として出てくる文字列の文字コードが食い違っている、という可能性がある。
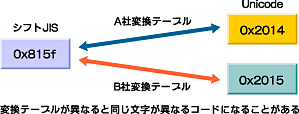
このような状況は、検索機能などでは致命的な問題を引き起こす。また、電子署名など、厳密な一致が得られなければならない分野では、使い物にならないことになる。
■解決策はUnicodeへの全面移行のみ
これを回避する方法は、いくつか考えられる。例えば変換テーブルの統一ができれば、文字化けを回避することができる。現在、各メーカーは、市場の要請から各社独自の変換テーブルからマイクロソフトの「CP932」と呼ばれる変換テーブルに合わせて変換テーブルを入れ替える動きがある。これが結実すれば問題は軽減されるかもしれないが、すでに多くの変換テーブルを含むソフトウェアが世の中に普及してしまったという事実があるため、完全な解決にはならない。
結局、問題を完全に解決するためには、最初から最後までUnicodeを使うしかない。XMLでは、Unicode以外の文字コード系を使用するオプションを用意しているが、これは利用できないと考え、全面的にUnicodeに移行するしかない。
残念ながら、これが今日のXMLと日本語の現実である。
しかしながら、ただ単にXML文書をUnicodeで書くようにしただけでは十分ではない。システムの中のどこかで文字コード変換を行っていれば、そこでトラブルが起きる可能性がある。例えば、入力や出力をUnicodeで行うことができないシステムでは、入出力時に文字コードを変換してやらねばならない。その時点でトラブルが起きる可能性がないとは言えないわけだ。実際に、システムが一貫してUnicodeを扱うことができないOSやアプリケーションソフトも、まだまだ存在する。例えば、Windows 2000は一貫してUnicodeで処理できるが、Linuxはまだ発展途上であり、Li18nuxなどの国際化とUnicode対応の強化プロジェクトが存在する。
しかし悲観する必要はない
いろいろ厳しい話を書いてきたが、悲観する必要はないと筆者は考える。ドッグイヤー、キャットイヤーで変化し続けるこの業界において、ソフトウェアやシステムの世代交代は早い。このような文字化け問題が、過渡期の笑い話となる日はそれほど遠くないだろう。それまでの間、XML利用者は、このような文字化けが起きるリスクに注意を払って、それを回避するように行動すればよいのである。少なくとも、Unicodeで記述されたXML文書形式で資産を蓄積しておけば、未来においてそれが無駄になることはないだろう。
さて、これまでXML 1.0 勧告のアウトラインを見てきたが、今回文字の話題を扱ったことで、そろそろ全体像が見えてきたと思う。そこで、次回からは、XML 1.0勧告の枠を飛び出して、その周辺の世界にも目を向けてみよう。最初に取り上げるのは、XML 1.0勧告そのものを一部変更する構文を含むほど、密接な関係のある名前空間(Namespaces in XML)を解説しよう。これは、現在の実用言語(XMLによる)では、必ずと言ってよいほど使用されている重要な機能である。
それでは次回、また会おう。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。