ブロックアルゴリズムとB-Treeアルゴリズム:Linuxファイルシステム技術解説(2)(2/3 ページ)
ブロックアルゴリズムとext2
ext2はBSDのFast File System(BSD FFS)を基に開発されたもので、UNIXで伝統的に用いられてきた「ブロック管理アルゴリズム」をベースとしている。ブロックアルゴリズムは前述したとおり、ディスク領域を「ブロック」に分けて管理する方法である。ここでは、「ブロックアルゴリズム」の基本的な構造をext2を例に見ていく。
ブロック管理
ext2は、ファイルシステム作成時に平均的なファイルサイズの予測に従ってブロック(注)を作成し、複数のブロックを「ブロックグループ」にまとめて管理する。
注:1024、2048、4096bytesのいずれか。
ブロックグループの構造を図1に示す。図の右側は、ext2パーティションのレイアウトを示している。「ブートブロック」は、パーティションのブートセクタとして予約されているブロックで、ブートローダの格納などに使用される。図の左側は、ブロックグループ0内のレイアウトである。
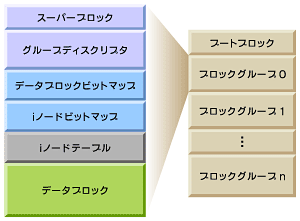 図1 ext2パーティションとブロックグループのレイアウト
図1 ext2パーティションとブロックグループのレイアウトブロックグループには機能の異なる複数のブロックが含まれる。主な要素を表2にまとめた。
| スーパーブロック | ファイルシステムに関する管理情報 |
|---|---|
| グループディスクリプタ | グループ内の情報 |
| データブロックビットマップ | データブロックの情報 |
| iノードビットマップ | iノードビットマップ |
| iノードテーブル | ファイル/ディレクトリに関する情報を保持するiノードを格納 |
| データブロック | 実際のデータの保持 |
| 表2 ブロックグループの構成要素 | |
後で説明するが、ext2ではブロックグループ0の「スーパーブロック」に、パーティション内のブロックグループ全体の管理情報が格納される。
スーパーブロックには、
- iノードの総数
- ブロックサイズ
- ファイルシステムのサイズ
- 空きブロック数、空きiノード数
- 使用されているブロックグループ
- 最終fsck時刻
など、ファイルシステムに関するさまざまな情報が含まれている。「グループディスクリプタ」は、「データブロックビットマップ」や「iノードビットマップ」情報などを参照して空きブロックや空きiノードを探し、データを割り当てる際に最適なブロックを決定するのに使われる。
「データブロックビットマップ」と「iノードビットマップ」は、ビットマップ情報である。ビットマップ情報は、あるデータが使用中か未使用かを0か1のbitで保持している。1byte=8bitsなので、80個のブロックの状態を10bytesで管理できる。
書き込み/読み込みなどが行われる実際のデータ(編注)は、「データブロック」に保持される。データブロックのサイズは、ほかのブロックと同じ1024、2048、4096bytesのいずれかの値である(通常、デフォルトでは4096bytes)。iノードのアドレスは128bytesなので、データブロックサイズを「1024」bytesにすると1ブロック当たり8つのiノード、「4096」bytesの場合は32個のiノードを使用できる。これらは通常、ファイルシステムが計算して割り当てる。「iノードテーブル」は、データブロックとiノードを結び付けて、「どのディレクトリにどのような権限を与えて保存しているか」といったファイル情報として管理している。
編注:人間が「ファイル」として認識できるデータ。
実際に、パーティション上のレイアウトの様子をdumpe2fsコマンドで確認してみよう。「dumpe2fs /dev/ディスク」を実行すると、以下のような表示が得られる。
# dumpe2fs /dev/sda1 |
| 注:Group 0、Group 1と、ブロックは連続的に続く。Group 0の最後はフリー(未使用)ブロック(下線部参照)。 |
アドレスの特定
ユーザーがext2パーティション上にあるファイルにアクセスするには、そのファイルのディスク上の実アドレスを特定できなければならない。ext2のブロックグループはさまざまな管理情報を保持しているので、ext2はこの情報にアクセスして適切なアドレスを返す。
例えば、ファイル名に結び付けられたiノード情報から、iノードテーブル内に保持されている対応するブロック番号が分かれば、そのアドレスを返すことができる。以下のように、13021番のiノードのディスク上のアドレスへの参照が行われると、「データブロック3のオフセット733」が返される。

次に、特定の大きさのファイルを参照することを考えてみよう。先に見たデータブロックサイズは4096bytesなので、ファイルサイズが4Kbytesよりも大きい場合は複数のデータブロックを使用することになる。例えば、400Kbytesのファイルの参照には、100個のデータブロックが必要となる。しかし、100個のデータブロックに対して100個のアドレスを保持するのは大変なので、ext2では効率的にアドレス範囲を使用するために間接ブロックを作成し、間接ポインタによって参照できるようにしている。
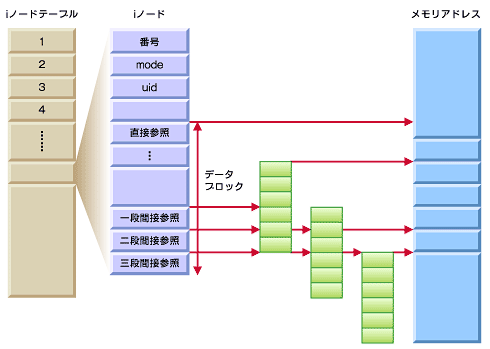 図2 データブロックのアドレッシング用データ構造
図2 データブロックのアドレッシング用データ構造iノードとデータブロックの関連付けは、「iノード構造体」(注)の中の1つのメンバとして保持されている。iノード構造体が持つデータブロック参照用の配列は15個。ext2では、そのうち12個を「直接参照」、残りの3つをそれぞれ「一段間接参照」「二段間接参照」「三段間接参照」用に使用することで、複数のデータブロックを必要とする大きめのファイルを効率的に扱うようにしている。
注:構造体はデータを格納するオブジェクトの単位、メンバはその中の1つのデータ参照用の単位と考えていただければよい。
直接参照で表現可能なファイルサイズは、ブロックサイズが1024や4096bytesの場合、「ブロックサイズ×12個」で、それぞれ12Kbytes、48Kbytesとなる。
一段間接参照では、「ブロックサイズ÷4」(ブロックポインタの大きさ[byte]) 個分使用できるため、ブロックサイズが1024bytesの場合は1024÷4=256個のエントリになる。これをファイルサイズに換算すると、256個×1024bytesで256Kbytesとなる。ブロックサイズが4096bytesで400Kbytesのファイルの場合、「(4096÷4)×4096bytes」で約4Mbytesまでの参照に当てはまるため、一段間接参照でファイルをアドレッシングできる。つまり400Kbytesのファイルの場合、直接参照では100個の配列が必要だが、一段間接参照であれば13個の配列で済むのである。
4096bytesのデータブロックを使用した場合、二段間接参照では「((ブロックサイズ÷4)^2)×ブロックサイズ」となり、4Gbytesまでのファイルのアドレスを表現できる。
ブロックアルゴリズムの限界
ext2のディスク領域の基本的な管理方法について見てきたが、これらにはいくつかの問題点がある。
- 間接参照の問題
二段間接参照で4Gbytesのアドレス表現ができるとしたが、ext2ではファイルサイズが32bitの制限に引っ掛かるため、2Gbytes以上のファイルは参照できない。また、ファイルサイズが大きくなると、二段、三段間接参照といった形で数回データブロックにアクセスしなければならないため、パフォーマンスが低下する。さらに、ファイルのサイズによって参照回数が異なればアクセス時間も変動するので、ファイルを一様に扱いたい場合などは不都合が生じる。 - iノードの枯渇
先に述べた「ブロックグループ当たりのiノード数」は計算上、ブロック当たりのbytes数という制限を受けるので、必然的にiノードの数も固定的になる。iノードが不足するとデータブロックに空きがあってもファイルを作成できなかったり、逆にデータブロックがいっぱいになると未使用のiノードが発生してしまうという問題が生じる。これに対しては、動的にiノードを割り振ることで事実上の制限をなくすReiserFS、JFS、XFSなどのファイルシステムが次第に使われるようになってきた。 - ブロック単位の記憶媒体の割り当て
ブロックアルゴリズムは、ブロック単位で記憶媒体の領域を割り当てるために非効率といえる。例えば、アルファベット1文字のみを書き込んだファイルは1byteのデータしか含まない。しかし、ブロックサイズが1024bytesの場合は1024bytes、4096bytesの場合は4096bytesのディスク領域を消費することになる(編注)。
編注:DOS/Windowsの「クラスタギャップ」と同じ。FAT16で2Gbytesのパーティションを作成した場合、クラスタサイズは32Kbytesとなる(どれほど小さなファイルも最低32Kbytes消費する)。
- スーパーブロックの更新
前述したdumpe2fsの例にもあるように、Group 0(ブロックグループ0)のスーパーブロックは「Primary Superblock」となっている。しかし、Group 1(ブロックグループ1)では「Backup Superblock」となっている。
カーネルによって使用されるのは、ブロックグループ0に含まれるスーパーブロックとグループディスクリプタのみで、そのほかのブロックグループに含まれているスーパーブロックとグループディスクリプタは基本的に変更されない(Backupとされているスーパーブロックは、Primaryのバックアップ)。そのほかのブロックグループは、定期的にブロックグループ0のスーパーブロックをアップデートする形で全体の同期を取る。
このように、ext2はブロックグループ0のスーパーブロックに依存した構造となっているため、スーパーブロックが何らかの理由で破壊されると元のディスク情報が再現できないといった致命的な障害となる。
図3は、e2fsck(ext2の一貫性チェックを行うコマンド)の実行過程を示す。コマンドは以下1、2の手順でファイルシステムの整合性を取る。
前述したdumpe2fsの例にもあるように、Group 0(ブロックグループ0)のスーパーブロックは「Primary Superblock」となっている。しかし、Group 1(ブロックグループ1)では「Backup Superblock」となっている。
カーネルによって使用されるのは、ブロックグループ0に含まれるスーパーブロックとグループディスクリプタのみで、そのほかのブロックグループに含まれているスーパーブロックとグループディスクリプタは基本的に変更されない(Backupとされているスーパーブロックは、Primaryのバックアップ)。そのほかのブロックグループは、定期的にブロックグループ0のスーパーブロックをアップデートする形で全体の同期を取る。
このように、ext2はブロックグループ0のスーパーブロックに依存した構造となっているため、スーパーブロックが何らかの理由で破壊されると元のディスク情報が再現できないといった致命的な障害となる。
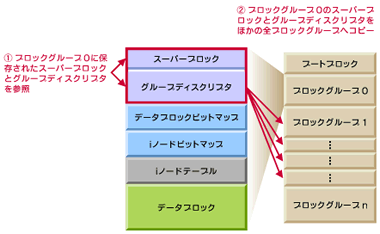 図3 e2fsckの実行過程
図3 e2fsckの実行過程- ディスク容量増大によるfsck時間の増加
ext2は、スーパーブロックに保持するビットマップ情報で記憶媒体の状態を管理している。ビットマップはiノードに単純に対応するものなので、ディスク容量が増えればビットマップ情報の量も増加する。
ext2のように、すべてのビットマップ情報を1カ所に保存する方式は、クラッシュ時の弊害が大きくなる危険性も高い。また、fsckコマンドは各ブロックグループとスーパーブロックを比較する方式で記憶媒体の整合性チェックを行うので、非常に時間がかかる。これに対して、ext3などジャーナリング機能が実装されたファイルシステムでは大幅に起動時間が短縮された。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。