Windows‚إInternet Explorer‚ًژg‚ء‚ؤ•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚éپFTech TIPS
Windowsٹآ‹«‚إ‚حپAƒVƒtƒgJISˆبٹO‚ة‚à‚³‚ـ‚´‚ـ‚ب•¶ژڑƒRپ[ƒh‚ھ—ک—p‚³‚ê‚ؤ‚¢‚éپB‚µ‚©‚µWindows•Wڈ€‚جƒRƒ}ƒ“ƒh‚âƒcپ[ƒ‹‚حƒVƒtƒgJISˆبٹO‚ج•¶ژڑƒRپ[ƒh‚ًگ³‚µ‚ˆµ‚¦‚ب‚¢‚±‚ئ‚à‚ ‚éپB‚»‚±‚إInternet Explorer‚ً—ک—p‚·‚é‚ئپAژèŒy‚ة•¶ژڑƒRپ[ƒh‚ً•دٹ·‚µ‚ؤ•ت‚جƒtƒ@ƒCƒ‹‚ة•غ‘¶‚إ‚«‚éپB
‘خڈغƒ\ƒtƒgƒEƒFƒAپFWindows XPپ^Windows Vistaپ^Windows 7پ^Windows 8پ^Windows 8.1پ^Windows Server 2003پ^Windows Server 2008پ^Windows Server 2008 R2پ^Windows Server 2012پ^Windows Server 2012 R2پAInternet Explorer 6پ^7پ^8پ^9پ^10پ^11
‰ًگà
پ@ƒRƒ“ƒsƒ…پ[ƒ^پ[‚إژg‚ي‚ê‚镶ژڑƒRپ[ƒh‘جŒn‚ة‚ح‚³‚ـ‚´‚ـ‚ب‚à‚ج‚ھ‚ ‚éپBWindows‚إژg‚ي‚ê‚镶ژڑƒRپ[ƒh‚ئ‚µ‚ؤ‚حپAMS-DOS‚جژ‘م‚©‚çپuƒVƒtƒgJISپvƒRپ[ƒh‚ھ‚ظ‚ع•Wڈ€‚إ‚ ‚ء‚½پB‚¾‚ھپAUNIXپ^Linux‚âMacپAƒXƒ}پ[ƒgƒtƒHƒ“پ^ƒ^ƒuƒŒƒbƒgپA‚»‚µ‚ؤƒCƒ“ƒ^پ[ƒlƒbƒgٹآ‹«‚ب‚ا‚إ‚حپA‚»‚ج‘¼‚ج•¶ژڑƒRپ[ƒh‚à‘½‚ژg‚ي‚ê‚ؤ‚¢‚éپB
پ@‚ـ‚½“ْ–{Œê‚¾‚¯‚إ‚ب‚پAگ¢ٹE’†‚جŒ¾Œê‚àƒRƒ“ƒsƒ…پ[ƒ^پ[‚إ“ˆê“I‚ةژو‚舵‚¤‚½‚ك‚ةپAŒ»چف‚جWindows OS‚إ‚حپA“à•”“I‚ة‚حپuUnicodeپv‚ًژg‚ء‚ؤڈˆ—‚ًچs‚ء‚ؤ‚¢‚éپB‚»‚µ‚ؤٹO•”‚ئ‚ج“üڈo—حژ‚ة‘¼‚ج•¶ژڑƒRپ[ƒh‚ئ‘ٹŒف‚ة•دٹ·‚ًچs‚ء‚ؤ‚¢‚éپB
پ@“ْ–{Œê‚ةŒہ‚ء‚ؤ‚¢‚¦‚خپAŒ»چف‚جWindowsٹآ‹«‚إ‚حˆب‰؛‚ج‚و‚¤‚ب•¶ژڑƒRپ[ƒhŒ`ژ®‚ھ‚و‚ژg‚ي‚ê‚ؤ‚¢‚éپB
| •¶ژڑƒRپ[ƒh–¼ | ˆس–، |
|---|---|
| ANSI | ƒAƒ‹ƒtƒ@ƒxƒbƒg‚ج‰pگ”ژڑ‹Lچ†•¶ژڑ‚ًٹـ‚قپA7bit‚جٹî–{“I‚ب•¶ژڑƒRپ[ƒhپB‘¼‚ج•¶ژڑƒRپ[ƒh‚إ‚àپA‰pگ”ژڑ•”•ھ‚ج•¶ژڑƒRپ[ƒh‚ح‚±‚جANSI•¶ژڑƒRپ[ƒh‚ًƒxپ[ƒX‚ة‚µ‚ؤ‚¢‚é‚à‚ج‚ھ‚ظ‚ئ‚ٌ‚ا‚إ‚ ‚éپBASCIIƒRپ[ƒh‚ئ‚àŒؤ‚خ‚ê‚é |
| ƒVƒtƒgJIS | MS-DOS‚جژ‘م‚©‚ç“ْ–{‚إچL‚ژg‚ي‚ê‚ؤ‚«‚½•¶ژڑƒRپ[ƒhپBٹ؟ژڑ•¶ژڑƒRپ[ƒh‚ئ‚µ‚ؤپAپuJISƒRپ[ƒhپv•\‚ً‚×پ[ƒX‚ة‚µ‚ؤ•دŒ`‚³‚¹‚½‚à‚جپiƒVƒtƒg‚µ‚½‚à‚جپj‚ً—ک—p‚µ‚ؤپAANSI•¶ژڑ‚ئ‹¤‘¶‚³‚¹‚ؤ‚¢‚é‚ج‚إ‚±‚¤Œؤ‚خ‚ê‚éپBPCٹآ‹«‚إ‚حˆê”ت“I‚ب“ْ–{Œê•¶ژڑƒRپ[ƒh |
| EUC | ڈ‰ٹْ‚ج“ْ–{Œê‘خ‰UNIXٹآ‹«‚إچL‚ژg‚ي‚ê‚ؤ‚¢‚½“ْ–{Œê•¶ژڑƒRپ[ƒhپBƒVƒtƒgJIS‚ئ‚حˆظ‚ب‚é•û–@‚إANSI•¶ژڑ‚ئٹ؟ژڑ•¶ژڑ‚ً‹¤‘¶‚³‚¹‚ؤ‚¢‚éپBŒ»چف‚جUNIXپ^Linux‚إ‚حUnicodeپ^UTF‚ًژg‚ء‚ؤ‚¢‚é‚à‚ج‚ھ‘½‚¢ |
| JISƒRپ[ƒh | ANSI•¶ژڑƒRپ[ƒh‚ئٹ؟ژڑ•¶ژڑƒRپ[ƒh‚ًپAپuƒGƒXƒPپ[ƒvƒVپ[ƒPƒ“ƒXپv‚ئŒؤ‚خ‚ê‚é“ء•ت‚ب•¶ژڑƒVپ[ƒPƒ“ƒX‚إگط‚è‘ض‚¦‚ب‚ھ‚狤‘¶‚³‚¹‚ؤ‚¢‚镶ژڑƒRپ[ƒhپBڈ]—ˆپAƒCƒ“ƒ^پ[ƒlƒbƒg“dژqƒپپ[ƒ‹‚ح‚±‚ج•¶ژڑƒRپ[ƒh‚إ‘—ژَگM‚³‚ê‚邱‚ئ‚ھ‘½‚©‚ء‚½‚ھپA‘م‚ي‚è‚ةUTF-8‚ھ‚و‚ژg‚ي‚ê‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚«‚ؤ‚¢‚é |
| Unicode | گ¢ٹE’†‚ج•¶ژڑ‚ً16bit‚à‚µ‚‚ح32bit‚جŒإ’è’·‚ج•¶ژڑƒRپ[ƒh‚إ“چ‡“I‚ةˆµ‚¤‚½‚ك‚ةچى‚ç‚ꂽ•¶ژڑƒRپ[ƒhپB•¶ژڑ‚جژي—ق‚ة‚و‚炸ƒRپ[ƒh’·‚ھˆê’肵‚ؤ‚¢‚é‚ج‚إپAƒvƒچƒOƒ‰ƒ€‚©‚爵‚¢‚â‚·‚پAOS‚âƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ج“à•”ƒRپ[ƒh‚ئ‚µ‚ؤژg‚ي‚ê‚邱‚ئ‚ھ‘½‚¢پB‚½‚¾‚µژں‚جUTF-16‚ئ“¯‹`‚ةژg‚ي‚ê‚éڈêچ‡‚à‘½‚¢پBWindows OS‚à“à•”‚إ‚ح‚±‚جUnicode‚ً—ک—p‚µ‚ؤ‚¢‚é |
| UTF | Unicode‚ًƒxپ[ƒX‚ة‚µ‚ؤپAژہچغ‚ةƒtƒ@ƒCƒ‹‚ةٹi”[‚µ‚½‚èپA’تگM‚ًچs‚¤ڈêچ‡‚جƒoƒCƒgƒfپ[ƒ^‚ج•ہ‚וû‚ب‚ا‚ً‹K’肵‚½‚à‚جپBUTF-7‚ئ‚©UTF-8پAUTF-16پAUTF-32‚ب‚ا‚ھ‚ ‚éپBUTF-16‚إ‚حپAƒoƒCƒgƒIپ[ƒ_پ[‚جˆل‚¢‚ة‚و‚èپAƒٹƒgƒ‹ƒGƒ“ƒfƒBƒAƒ“Œ`ژ®‚ئƒrƒbƒOƒGƒ“ƒfƒBƒAƒ“Œ`ژ®‚ب‚ا‚جˆل‚¢‚ھ‚ ‚éپB“ء‚ةUTF-8‚حپAƒVƒtƒgJIS‚âJISƒRپ[ƒh‚ة‘م‚ي‚ء‚ؤ‚و‚ژg‚ي‚ê‚é‚و‚¤‚ة‚ب‚ء‚ؤ‚«‚ؤ‚¢‚é |
| “ْ–{Œê‚جWindows OSٹآ‹«‚إ‚و‚ژg‚ي‚ê‚镶ژڑƒRپ[ƒh | |
پ@‚±‚ê‚當ژڑƒRپ[ƒh‚جˆل‚¢‚حپA’تڈي‚جƒ†پ[ƒUپ[‚ح‹C‚ة‚·‚é•K—v‚ح‚ب‚¢پB‚¾‚ھڈêچ‡‚ة‚و‚ء‚ؤ‚حپA•¶ژڑƒRپ[ƒh‚جˆل‚¢‚ة‚و‚ء‚ؤگ³‚µ‚ڈˆ—‚ھ‚إ‚«‚ب‚¢‚ئ‚¢‚ء‚½ƒPپ[ƒX‚à‚ ‚éپB
پ@—ل‚¦‚خپAWindows OS‚جƒRƒ}ƒ“ƒhƒvƒچƒ“ƒvƒgڈم‚إژg‚ي‚ê‚éٹeژي‚ج•Wڈ€ƒRƒ}ƒ“ƒh‚إ‚حپAƒVƒtƒgJISˆبٹO‚ج•¶ژڑƒRپ[ƒh‚إڈ‘‚©‚ꂽƒeƒLƒXƒg‚ًڈˆ—‚إ‚«‚ب‚¢‚à‚ج‚ھ‘½‚¢پiƒRƒ}ƒ“ƒh‚ة‚و‚ء‚ؤ‚حƒVƒtƒgJIS‚ئUnicode‚ج—¼•û‚ھژg‚¦‚é‚à‚ج‚à‚ ‚éپjپB‚ـ‚½ƒپƒ‚’ ‚إ‚حپAپuJISƒRپ[ƒhپv‚âپuEUCƒRپ[ƒhپv‚إڈ‘‚©‚ꂽƒeƒLƒXƒgƒtƒ@ƒCƒ‹‚ًٹJ‚‚ئ•¶ژڑ‰»‚¯‚µ‚ؤ‚µ‚ـ‚¤پB
پ@‚±‚ج‚و‚¤‚بڈêچ‡‚حپAƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ھ—‰ً‚إ‚«‚éŒ`‚ةپA‚ ‚ç‚©‚¶‚ك•¶ژڑƒRپ[ƒh‚ً•دٹ·‚µ‚ؤ‚¨‚‚±‚ئ‚ھ–]‚ـ‚µ‚¢پB–{چe‚إ‚حپA‰½‚©ƒcپ[ƒ‹‚ً—pˆس‚·‚邱‚ئ‚ب‚پAWindows OS•Wڈ€‘•”ُ‚جInternet Explorerپiˆب‰؛IEپj‚ً—ک—p‚µ‚ؤژèŒy‚ة•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚é•û–@‚ًڈذ‰î‚·‚éپB‚»‚ج‘¼‚ج•û–@‚ة‚آ‚¢‚ؤ‚حپAژں‚ج‹Lژ–‚ًژQڈئ‚µ‚ؤ‚¢‚½‚¾‚«‚½‚¢پB
- nkfƒcپ[ƒ‹‚إ•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚é
- PowerShell‚إ•،گ”‚جƒtƒ@ƒCƒ‹‚ج•¶ژڑƒRپ[ƒh‚ًˆêٹ‡•دٹ·‚·‚é
- WSH‚إƒtƒ@ƒCƒ‹‚ج•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚é
‘€چى•û–@
پ@ƒtƒ@ƒCƒ‹‚ةٹـ‚ـ‚ê‚镶ژڑ‚جƒRپ[ƒhپiٹ؟ژڑ‚ج•¶ژڑƒRپ[ƒhپj‚ً•دٹ·‚·‚é‚ة‚حپAInternet Explorerپiˆب‰؛IEپj‚ًژg‚¤‚ج‚ھٹب’P‚إ‚و‚¢پB‘€چى•û–@‚ئ‚µ‚ؤ‚حپA’P‚ةIE‚إ‘خڈغƒtƒ@ƒCƒ‹‚ًٹJ‚«پA•ت‚ج•¶ژڑƒRپ[ƒh‚ًژw’肵‚ؤƒeƒLƒXƒgŒ`ژ®‚إ•غ‘¶‚·‚邾‚¯‚إ‚ ‚éپB‚±‚ꂾ‚¯‚إ•ت‚ج•¶ژڑƒRپ[ƒh‚ة•دٹ·‚إ‚«‚éپB
پœ‚ـ‚¸IE‚إ‘خڈغ‚جƒtƒ@ƒCƒ‹‚ًگ³‚µ‚¢•¶ژڑƒRپ[ƒh‚إ•\ژ¦‚³‚¹‚é
پ@•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚é‚ة‚حپA‚ـ‚¸”Cˆس‚ج•¶ژڑƒRپ[ƒh‚إ‹Lڈq‚³‚ꂽƒtƒ@ƒCƒ‹‚ًپAپuپ`.txtپv‚ئ‚¢‚¤ƒtƒ@ƒCƒ‹–¼‚ة•دچX‚·‚éپB‚»‚µ‚ؤ‚±‚ê‚ًپA‹N“®‚µ‚½IE‚جƒEƒBƒ“ƒhƒE‚ضƒhƒ‰ƒbƒOپ•ƒhƒچƒbƒv‚·‚éپB
پ@‚±‚جژ“_‚إIE‚ج‰و–ت‚ة‚حپA‘خڈغƒtƒ@ƒCƒ‹“à‚ة‹Lڈq‚³‚ꂽƒeƒLƒXƒg‚ھگ³‚µ‚•\ژ¦‚³‚ê‚ؤ‚¢‚é‚ح‚¸‚إ‚ ‚éپi‚»‚جڈêچ‡‚حپuگ³‚µ‚•\ژ¦‚³‚ꂽ‚ç•ت‚جƒtƒ@ƒCƒ‹‚ة•غ‘¶‚·‚éپv‚ضگi‚ٌ‚إ‚¢‚½‚¾‚«‚½‚¢پjپB‚¾‚ھپA‚±‚ج’iٹK‚إ•¶ژڑ‰»‚¯‚ھگ¶‚¶‚邱‚ئ‚à‚µ‚خ‚µ‚خ‚ ‚éپB
پ@IE‚إ‚حƒtƒ@ƒCƒ‹‚âWebƒyپ[ƒW’†‚إژg‚ي‚ê‚ؤ‚¢‚镶ژڑƒRپ[ƒh‚ًژ©“®“I‚ة”»•ت‚µ‚ؤپAگ³‚µ‚¢•¶ژڑƒRپ[ƒh‚إ•\ژ¦‚·‚é‹@”\‚ًژ‚ء‚ؤ‚¢‚éپB‚µ‚©‚µپA•¶ژڑƒRپ[ƒh‚ً”»•ت‚·‚邽‚ك‚جڈî•ٌ‚ھڈ‚ب‚©‚ء‚½‚èپA”»•ت•s‰آ”\‚ب•¶ژڑ‚خ‚©‚è‚ھژg‚ي‚ê‚ؤ‚¢‚é‚ئپA•¶ژڑƒRپ[ƒh‚ج”»•ت‚ةژ¸”s‚µ‚ؤ•¶ژڑ‰»‚¯‚ھگ¶‚¶‚邱‚ئ‚ھ‚ ‚éپB
پ@‚±‚ج‚و‚¤‚بڈêچ‡‚حپAƒ†پ[ƒUپ[‚ھژè“®‚إپuگ³‚µ‚¢پv•¶ژڑƒRپ[ƒh‚ًژw’è‚·‚ê‚خ‚و‚¢پB‚ا‚ج•¶ژڑƒRپ[ƒh‚ب‚ج‚©•ھ‚©‚ç‚ب‚¢ڈêچ‡‚حپAˆب‰؛‚ج‰و–ت‚جƒ|ƒbƒvƒAƒbƒvƒپƒjƒ…پ[‚إٹe•¶ژڑƒRپ[ƒh‚ً1‚آ‚¸‚آ‘I‘ً‚µ‚ؤپA•¶ژڑ‰»‚¯‚ھ‰ًڈء‚³‚ê‚é‚ـ‚إژژ‚µ‚ؤ‚ف‚و‚¤پB
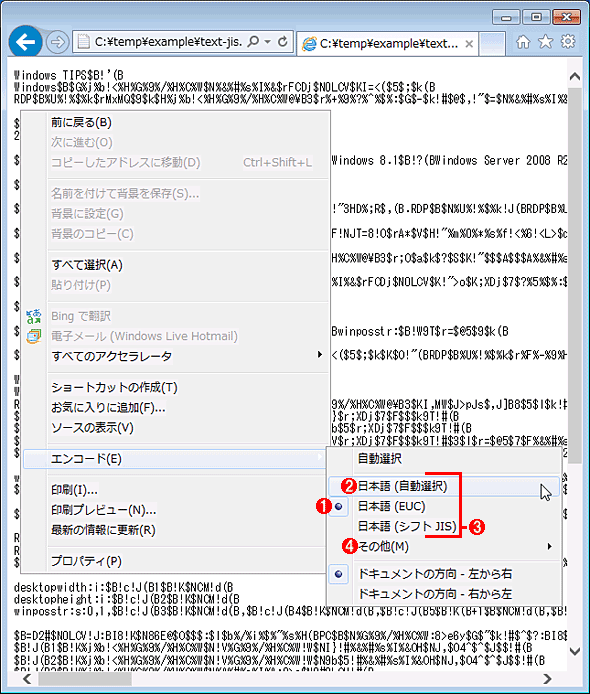 IE‚إ•\ژ¦’†‚جƒeƒLƒXƒg‚ج•¶ژڑ‰»‚¯‚ً’¼‚·
IE‚إ•\ژ¦’†‚جƒeƒLƒXƒg‚ج•¶ژڑ‰»‚¯‚ً’¼‚·•\ژ¦‚³‚ê‚ؤ‚¢‚镶ژڑ‚ھ‰»‚¯‚ؤ‚¢‚éڈêچ‡‚حپAƒ†پ[ƒUپ[‚ھ•¶ژڑƒRپ[ƒh‚ً–¾ژ¦“I‚ةژw’è‚·‚邱‚ئ‚ة‚و‚èپA‹گ§“I‚ةگ³‚µ‚¢•¶ژڑƒRپ[ƒh‚إ•\ژ¦‚إ‚«‚éپB•¶ژڑƒRپ[ƒh‚ًژw’肵‚ؤƒtƒ@ƒCƒ‹‚ً•غ‘¶‚·‚邽‚ك‚ة‚حپA‚ ‚ç‚©‚¶‚كگ³‚µ‚•\ژ¦‚³‚¹‚ؤ‚¨‚©‚ب‚¯‚ê‚خ‚ب‚ç‚ب‚¢پB•¶ژڑƒRپ[ƒh‚ً•دچX‚·‚é‚ة‚حپAƒEƒBƒ“ƒhƒEڈم‚إ‰EƒNƒٹƒbƒN‚µ‚ؤƒ|ƒbƒvƒAƒbƒvƒپƒjƒ…پ[‚©‚çپmƒGƒ“ƒRپ[ƒhپn‚ً‘I‚ش‚©پAپmAltپnƒLپ[‚ً‰ں‚µ‚ؤ•\ژ¦‚³‚ê‚éƒپƒjƒ…پ[ƒoپ[‚©‚çپm•\ژ¦پnپ|پmƒGƒ“ƒRپ[ƒhپn‚ً‘I‘ً‚·‚éپB
پ@ پi1پjŒ»چف‚جƒGƒ“ƒRپ[ƒfƒBƒ“ƒOŒ`ژ®‚ھ‚±‚ج‚و‚¤‚ةƒ}پ[ƒN•t‚«‚إ•\ژ¦‚³‚ê‚éپB‚±‚ê‚ھ–]‚ف‚ج•¶ژڑƒRپ[ƒh‚إ‚ب‚¢ڈêچ‡‚حپA‘¼‚ج•¶ژڑƒRپ[ƒh‚ً‘I‘ً‚إ‚«‚éپB‚½‚¾‚µJISƒRپ[ƒh‚جڈêچ‡‚حپm“ْ–{Œê (JIS)پn‚ئ‚¢‚¤چ€–ع‚ھ’WگF•\ژ¦‚³‚ê‚é‚ھپAپm“ْ–{Œê (JIS)پn‚ً‘I‘ً‚·‚邱‚ئ‚ح‚إ‚«‚ب‚¢پB‘م‚ي‚è‚ةپm“ْ–{Œê (ژ©“®‘I‘ً)پn‚ً‘I‘ً‚·‚éپB
پ@ پi2پjپm“ْ–{Œê (ژ©“®‘I‘ً)پn‚حپA•¶ژڑƒRپ[ƒh‚ًژ©“®“I‚ة”»•ت‚³‚¹‚éڈêچ‡پA‚¨‚و‚رJISƒRپ[ƒh‚ً‘I‘ً‚µ‚½‚¢ڈêچ‡‚ةژg—p‚·‚éپB
پ@ پi3پj‚·‚إ‚ة‰½“x‚©ژg‚ء‚½•¶ژڑƒRپ[ƒh‚جڈêچ‡‚ح‚±‚±‚ة•\ژ¦‚³‚ê‚ؤ‚¢‚é‚ج‚إپA‘f‘پ‚‘I‘ً‚إ‚«‚éپB
پ@ پi4پj‚ ‚ـ‚èژg‚ء‚½‚±‚ئ‚ج‚ب‚¢•¶ژڑƒRپ[ƒh‚جڈêچ‡‚حپAپm‚»‚ج‘¼پn‚ً‘I‘ً‚·‚é‚ئپAپi“ْ–{ŒêˆبٹO‚àٹـ‚قپj‘S‚ؤ‚جƒGƒ“ƒRپ[ƒfƒBƒ“ƒOŒ`ژ®‚ھƒTƒuƒپƒjƒ…پ[‚ئ‚µ‚ؤ•\ژ¦‚³‚ê‚éپB
پœگ³‚µ‚•\ژ¦‚³‚ꂽ‚ç•ت‚جƒtƒ@ƒCƒ‹‚ة•غ‘¶‚·‚é
پ@IE‚ج‰و–تڈم‚إگ³‚µ‚•¶ژڑ‚ھ•\ژ¦‚³‚ê‚ê‚خپA•ت‚ج•¶ژڑƒRپ[ƒhŒ`ژ®‚إ•ت‚جƒtƒ@ƒCƒ‹‚ة•غ‘¶‚إ‚«‚éپB
پ@•ت‚جƒtƒ@ƒCƒ‹‚ض•غ‘¶‚·‚é‚ة‚حپAپmAltپnƒLپ[‚ً‰ں‚µ‚ؤ•\ژ¦‚³‚ê‚éƒپƒjƒ…پ[ƒoپ[‚©‚çپmƒtƒ@ƒCƒ‹پnپ|پm–¼‘O‚ً•t‚¯‚ؤ•غ‘¶‚·‚éپn‚ً‘I‘ً‚·‚éپiIE9ˆبچ~‚إ‚حپmCtrlپnپ{پmSپnƒLپ[‚ً‰ں‚µ‚ؤ‚à‚و‚¢پjپB‚·‚é‚ئژں‚ج‚و‚¤‚ب‰و–ت‚ھ•\ژ¦‚³‚ê‚é‚ج‚إپAپmƒGƒ“ƒRپ[ƒhپn‚إ•¶ژڑƒRپ[ƒh‚ً‘I‘ً‚µ‚ؤ•غ‘¶‚·‚éپB
پ@Œ»چف‚ج•\ژ¦“à—e‚ھWebƒyپ[ƒW‚جڈêچ‡‚حپAپmƒtƒ@ƒCƒ‹‚جژي—قپn‚ًپmƒeƒLƒXƒg ƒtƒ@ƒCƒ‹پn‚ة‚·‚邱‚ئ‚ة‚و‚èپAƒeƒLƒXƒg•¶ژڑ•”•ھ‚ج‚ف‚ًƒeƒLƒXƒgƒtƒ@ƒCƒ‹‚ئ‚µ‚ؤ•غ‘¶‚إ‚«‚éپB
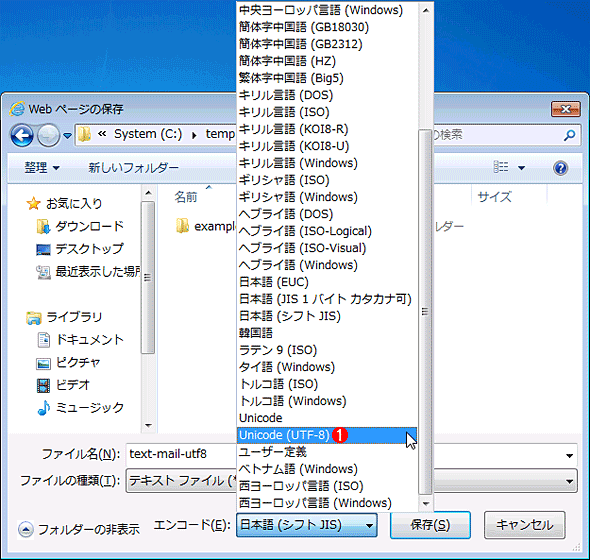 •غ‘¶ژ‚ج•¶ژڑƒRپ[ƒh‚ً‘I‘ً‚·‚é
•غ‘¶ژ‚ج•¶ژڑƒRپ[ƒh‚ً‘I‘ً‚·‚é•غ‘¶ژ‚ة•¶ژڑƒRپ[ƒh‚ًژw’è‚·‚邱‚ئ‚ة‚و‚èپAŒ³‚جƒeƒLƒXƒgƒtƒ@ƒCƒ‹‚ج•¶ژڑƒRپ[ƒh‚ئ‚حˆظ‚ب‚éŒ`ژ®‚ج•¶ژڑƒRپ[ƒh‚إ•غ‘¶‚إ‚«‚éپB
پ@ پi1پj•غ‘¶ژ‚ج•¶ژڑƒRپ[ƒh‚ً‘I‘ً‚·‚éپB“ْ–{Œê‚جڈêچ‡‚ةژw’è‚إ‚«‚镶ژڑƒRپ[ƒh‚ج–¼ڈج‚ة‚آ‚¢‚ؤ‚حپAژں‚ج•\‚ًژQڈئ‚µ‚ؤ‚¢‚½‚¾‚«‚½‚¢پB
پ@‚±‚جƒپƒjƒ…پ[‚إ‘I‘ً‚إ‚«‚é‚ج‚حپA“ْ–{Œê‚إ‚حˆب‰؛‚ج‚à‚ج‚¾‚¯‚إ‚ ‚éپB
| ‘I‘ً‚إ‚«‚镶ژڑƒRپ[ƒh‚ج–¼ڈج | ˆس–، |
|---|---|
| Unicode | 16bit‚جƒٹƒgƒ‹ƒGƒ“ƒfƒBƒAƒ“‚جUTF-16پi16bit Unicodeپjپ–1 |
| Unicode (UTF-8) | UTF-8پi8bit Unicodeپjپ–1 |
| “ْ–{Œê (EUC) | EUCƒRپ[ƒh |
| “ْ–{Œê (JIS 1 ƒoƒCƒg ƒJƒ^ƒJƒi‰آ) | JISƒRپ[ƒh |
| “ْ–{Œê (ƒVƒtƒg JIS) | ƒVƒtƒgJISƒRپ[ƒh |
| IE‚إ•غ‘¶‚إ‚«‚镶ژڑƒRپ[ƒh‚جژي—قپi“ْ–{ŒêٹضکA‚ج‚فپj پ–1پ@IE8ˆب‘O‚إ‚حپAƒtƒ@ƒCƒ‹‚جگو“ھ‚ةBOMپiByte Order Markپj‚ئŒؤ‚خ‚ê‚éپAUnicode‚ج“ء•ت‚بƒfپ[ƒ^‚ھگو“ھ‚ةڈ‘‚«چ‚ـ‚ê‚ب‚¢پB | |
پœIE8ˆب‘O‚إUnicode‚ً‘I‘ً‚µ‚½ڈêچ‡‚حپuƒoƒCƒgƒIپ[ƒ_پ[ƒ}پ[ƒNپiBOMپjپv‚ة’چˆس
پ@IE8ˆب‘O‚جڈêچ‡پAڈم‹L‚جژèڈ‡‚إپuUnicodeپvپuUnicode (UTF-8)پv‚ً‘I‚ٌ‚إ•غ‘¶‚·‚é‚ئپAƒtƒ@ƒCƒ‹‚جگو“ھ‚ةUnicode‚جپuBOMپiByte Order MarkپjپvƒRپ[ƒh‚ھڈ‘‚«چ‚ـ‚ê‚ب‚¢پBIE9ˆبچ~‚إ‚حگ³ڈي‚ةڈ‘‚«چ‚ـ‚ê‚éپB
پ@BOM‚ئ‚حپAƒoƒCƒgƒIپ[ƒ_پ[‚ًژ¯•ت‚·‚邽‚ك‚ج“ء•ت‚بƒfپ[ƒ^‚¾پB“ء‚ةUnicodeپiUTF-16پj‚جڈêچ‡پAƒtƒ@ƒCƒ‹‚جگو“ھ‚ة‚±‚جBOM‚ً‹L“ü‚µ‚ؤ‚¨‚‚±‚ئ‚إپAƒoƒCƒgƒIپ[ƒ_پ[‚ًگ³ٹm‚ة”»’è‚إ‚«‚éپBBOM‚ھ‘¶چف‚µ‚ب‚¢‚ئپAƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‚ة‚و‚ء‚ؤ‚حگ³‚µ‚Unicodeƒtƒ@ƒCƒ‹‚ً“ا‚فچ‚ق‚±‚ئ‚ھ‚إ‚«‚ب‚¢ڈêچ‡‚ھ‚ ‚éپB
پ@‚±‚ج‚و‚¤‚بڈêچ‡‚حپAIE‚إ•غ‘¶‚·‚é‚ج‚إ‚ح‚ب‚پAIE‚ج‰و–تڈم‚إƒeƒLƒXƒg‚ً‘I‘ًپEƒRƒsپ[‚µ‚ؤ‚©‚çƒپƒ‚’ ‚ة“\‚è•t‚¯پA‚»‚±‚إ‚ ‚炽‚ك‚ؤUnicode‚إ•غ‘¶‚·‚é‚ب‚ا‚ج‘€چى‚ًچs‚¦‚خ‚و‚¢پBƒپƒ‚’ ‚ھUnicode‚إ•غ‘¶‚·‚éڈêچ‡‚حپA•K‚¸BOM‚ھڈ‘‚«چ‚ـ‚ê‚é‚©‚ç‚إ‚ ‚éپB
پ،چXگV—ڑ—ً
پy2014/10/29پzWindows Vistaˆبچ~‚جWindows OSپA‚¨‚و‚رInternet Explorer 6پ`11‚ة‘خ‰‚µ‚ـ‚µ‚½پB
پy2004/02/28پzڈ‰”إŒِٹJپi‘خڈغƒ\ƒtƒgƒEƒFƒA‚حWindows 2000پ^XPپ^Server 2003پjپB
پ،‚±‚ج‹Lژ–‚ئٹضکAگ«‚جچ‚‚¢•ت‚ج‹Lژ–
- Windows‚إUnicode•¶ژڑ‚ًٹب’P‚ة“ü—ح‚µ‚½‚èپAUnicode‚ج•¶ژڑƒRپ[ƒh”شچ†‚ً’²‚ׂ½‚è‚·‚é•û–@پiTIPSپj
- nkfƒcپ[ƒ‹‚إ•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚éپiWindows•زپjپiTIPSپj
- ƒپپ[ƒ‹‚ج•¶ژڑƒRپ[ƒh‚ً—‰ً‚·‚éپiTIPSپj
- Windows‚©‚çiPhoneپ^iPod touchپ^Mac‚ة‘—‚ء‚ؤ‚ح‚¢‚¯‚ب‚¢•¶ژڑ‚ئ‚حپHپiTIPSپj
- Windows‚إƒoƒCƒiƒٹƒtƒ@ƒCƒ‹‚ج“à—e‚ًƒپƒ‚’ پinotepadپj‚إٹm”F‚·‚éپiTIPSپj
- ƒeƒLƒXƒgپEƒtƒ@ƒCƒ‹‚جچs––ƒRپ[ƒh‚ً•دچX‚·‚éپiTIPSپj
- ƒtƒ@ƒCƒ‹‚ج•¶ژڑƒRپ[ƒh‚ً•دٹ·‚·‚éپiTIPSپj
- ƒXƒNƒٹƒvƒgƒŒƒbƒgپEƒRƒ“ƒ|پ[ƒlƒ“ƒg‚إƒٹƒ\پ[ƒXڈî•ٌ‚ً’è‹`‚·‚éپiTIPSپj
پuTech TIPSپv
Copyright© Digital Advantage Corp. All Rights Reserved.
پ—IT eBook




![]() ITmedia‚حƒAƒCƒeƒBƒپƒfƒBƒAٹ”ژ®‰ïژذ‚ج“oک^ڈ¤•W‚إ‚·پB
ITmedia‚حƒAƒCƒeƒBƒپƒfƒBƒAٹ”ژ®‰ïژذ‚ج“oک^ڈ¤•W‚إ‚·پB