【真夏の夜のミステリー】Tomcatを殺したのは誰だ?:現場から学ぶWebアプリ開発のトラブルハック(6)(1/3 ページ)
本連載は、現場でのエンジニアの経験から得られた、APサーバをベースとしたWebアプリ開発における注意点やノウハウについて解説するハック集である。現在起きているトラブルの解決や、今後の開発の参考として大いに活用していただきたい。(編集部)
【第1章】Tomcatが無応答!?
トラフィックの多い大規模サイトでは、その負荷のためにさまざまな問題が発生する。それらの問題を回避するには、性能を考慮して作られたアプリケーションや、ノウハウに基づいたミドルウェアのチューニングが必要となる。
TomcatはServletコンテナとしての長い歴史を持ち、多くの採用実績を持つオープンソースのアプリケーションサーバ(以下、APサーバ)だ。大規模なサイトで採用される事例も出てきており、Tomcatに関してもきちんとしたノウハウが必要となっている。
■いったいTomcatに何が起こったのか?
今回トラブルが発生したシステムでもTomcatを採用していた。トラフィックの多いサイトであるため、特に性能には注意を払い、試験環境での負荷試験によって問題がないことを確認していた。しかし、それでもトラブルは起こってしまったのだ。
トラブルの内容は、トラフィックが多い時間帯になると、応答が返らないリクエストが発生するというものだった。しかし、一般的な過負荷状態とは異なり、Webブラウザでリロードを行うと、すぐに応答が返ってくる。また、Tomcatを再起動すると、一時的に状況は回復するらしい。
■トラブルシューティング屋はつらいよ
発生したりしなかったりという事象はとても解析しづらい。そうはいっても何とかしなければならないのが、トラブルシューティング屋の仕事だ。現場では、問題が発生したときには再起動でしのいでおり、システムは一応運用できている。そのため、対応は次の日でよいとのことだった。そこで、その日は急いで帰宅し、翌日早朝からの作業に備えることにした。
【第2章】徹夜明けの担当者を捕まえて聞き込み
翌朝現場に到着するとすぐに、徹夜明けの担当者を捕まえ、現状を正しく把握するためにヒアリングを行った。その結果、以下のような状況であることが分かった。
- Tomcatの前にはApacheを配置しており、mod_jkによって接続している
- Apache、Tomcatは別サーバとなっており、それぞれ2台構成である
- トラフィックが多いときに無応答となる
- 問題が発生しているときに内部セグメントから直接Tomcatにアクセスすると、応答がある
- DBサーバで取得しているスロークエリーのログには何も出力されていない
- CPUやメモリ使用率、GC(ガベージ・コレクション)のログは整理済み。そのほかのログファイルは大量の出力があるため、現在整理を行っている
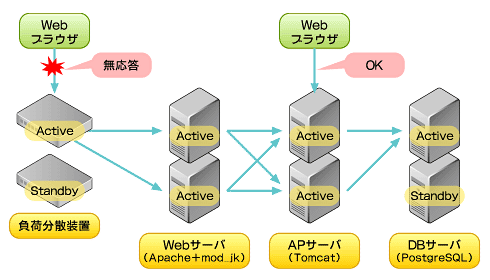 図1 トラブルが発生したシステム
図1 トラブルが発生したシステム問題となっているのは、どうやら負荷分散装置とApacheを経由するルートのみのようだ。また、現在はトラフィックが少ない時間帯であり、問題は発生していないとのことだった。
【第3章】何はともあれ、切り分けフローに従い分析
ヒアリングにより大まかな状況は把握できたが、より詳細に知るにはやはりログによる分析が必要だ。Webアプリの問題点を「見える化」する7つ道具を利用し、そこで整理が終わっているログから順に、トラブル切り分けフローに従い分析を行うことにした。
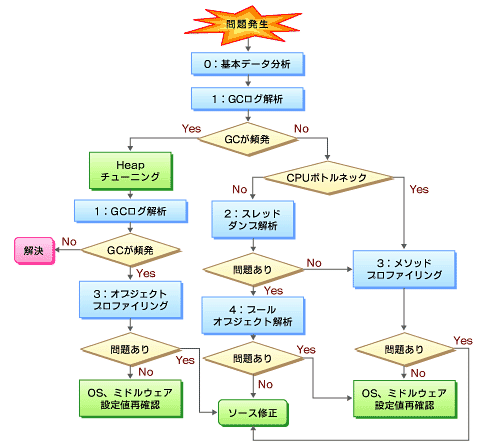 図2 トラブル切り分けフロー(
図2 トラブル切り分けフロー(■0:基本データ分析
無応答になるのは、トラフィックが多いときであるため、サーバがリソース不足になっている可能性がある。そこで、問題発生当時のCPU使用率やメモリ使用率を入念に確認した。表1はそのときの状況をまとめたものだ。
| サーバ | CPU使用率 | メモリ使用率 | |
|---|---|---|---|
| Web | 20〜30% | 60% | |
| AP | 40〜50% | 95% | |
| DB | 60〜80% | 95% | |
どうやら、リクエストが多いときのAPサーバの平均CPU使用率は50%、DBサーバは80%に達しているようだ。しかし、この程度の使用率では、無応答の原因になるとは考えられない。
次にメモリ使用率だが、こちらはAPサーバ、DBサーバは95%を超える高い値を示していた。しかし、JavaのHeap領域やDBMSの共有メモリを大きめに確保しているため、見た目の使用率が高くても、必ずしもメモリ不足ということにはできない。
そこで、スワップの使用状況も確認したところ、スワップはまったく使用されておらず、メモリも問題とはなっていないようだった。
DBサーバはスロークエリーがなかったため、原因になっているとは思えない。そこで、以降はAPサーバに焦点を絞って解析を続けることにした。
■1:GCログ
基本データ分析からは問題が発見できなかったため、切り分けフローに従いGC状況を確認した。ログからは、New領域のGCであるScavenge GCが、5秒に1回程度の頻度で発生していることが分かった。しかし、いずれも0.1秒以下で終了しており、応答時間に大きな影響を及ぼすとは考えづらい。また、停止時間の長いFull GCはまったく発生していなかった。
どうやら、GCも原因にはなっていないようだ。
編集部注:New領域、Scavenge GC、Full GCについて詳しく知りたい読者は、連載Javaパフォーマンスチューニングの第3回 「Javaのヒープ・メモリ管理の仕組み」をご参照ください。
■2:スレッドダンプ解析
切り分けフローでは、次はスレッドダンプ解析になるが、問題発生時のスレッドダンプは取得できていなかった。
現在は問題は発生していない。しかし、問題が顕在化していない状況でも、何回かダンプを取得し、スレッドの状態を比較することで、異常となる傾向が発見できることもある。また、問題が発生したときに比較するための材料にもなる。そこで一応、スレッドダンプを取得し確認してみることにした。
間隔を空けダンプを3回取得し、チェックを行う。その結果、ロック待ちとなっているスレッドの数も多くはなく、3回を通してロック待ちやDBの応答待ちで固まっているスレッドもなかった。
つまり、何も原因はつかめなかった。
問題が発生したときに取得すれば、もう少し何か分かるかもしれない。プロジェクトの担当者に、問題が発生したときには、速やかにスレッドダンプを取ってもらうことを依頼した。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。