高負荷なのに片方のサーバにだけ余裕が……なぜ?:Linuxトラブルシューティング探偵団(1)(3/4 ページ)
やはりスレッドダンプを見るしかない!
ここまでの調査で、以下のことが分かりました。
- アクセス数自体は、設定どおり均等に振り分けられている
- リクエスト処理時間に違いが見られる
- Minor GCの数がCPU使用率の差を生じさせている
- 目立ったDBのスロークエリは存在しない
これだけでは原因の特定には至らないため、再現試験を行うことにしました。
まず、ThreadBusyとなっているスレッドがなぜ停止しているのかを確認するため、スレッドダンプを行います。スレッドダンプは、以下のようにJavaの実行プロセスにSIGQUITシグナルを送ることで取得できます(UNIXの場合)。スレッドダンプの出力内容を表4に示しました。
# kill -QUIT <TomcatのプロセスID>・プロセスの実行ユーザーかrootユーザーで実行する必要があります ・シグナルを送られた時点で、標準出力にすべてのJavaスレッドのスレッドスタックを出力します ・スレッドダンプを行ってもアプリケーションは終了しません |
"TP-Processor61" daemon prio=1 tid=0x00002aaad1 483320 |
at java.lang.Object.wait(Native Method)
|
|
定期的にスレッドダンプを出力することで、長期間停止しているスレッドの状態確認などが行えます。出力例は下記のようになります。
■CPU使用率に差がある状態でTomcatのスレッドダンプを取得
問題の再現試験を行い、偏りが発生している状態でスレッドダンプを取得し、スレッドがどのような状態になっているかを調査してみました。
この結果、負荷の高い方のサーバでは、「org.apache.tomcat.dbcp.pool.impl.GenericObjectPool.borrowObject」で多くのスレッド(平均で1300スレッド)が止まっていることが明らかになりました。これは、DBCP(注4)のコネクションプールからコネクションを取得しようとしたところで止まっていることを示しています。
"TP-Processor1186" daemon prio=1 |
実際にコネクションを使用してデータベースへアクセスしているスレッドは、スレッドダンプの中で「locked」と出力されていて、jdbc関連のオブジェクトをロックして実行中のスレッドです。その数は最大でも30でした。検証環境のDBCPの設定で、コネクションプールの最大数を30としていたので、これは予定どおりの動作です。
"TP-Processor1181" daemon prio=1 |
DBCPでは、コネクションプールからコネクションを取得するまでの時間にタイムアウトも設定できます。これは60秒に設定していたため、処理がGenericObjectPool.borrowObjectで止まっても、60秒以内に取得できれば問題なく動作します。
アクセスログを見ると、処理時間は長くても2秒以内で、エラーも出ていません。このことから、仮に1300スレッドが待たされていても、60秒間は待たされることなくコネクションを取得できているようです。そこで、コネクションプールの設定を30よりも大きくすれば処理がスムーズに流れそうですが、データベースサーバのCPU使用率は、2台のアプリケーションサーバからの処理で80%近くに上っており、これ以上上げられません。
そもそも、2台のアプリケーションサーバとも同じ設定になっていますから、負荷が高い原因は、コネクション待ちの影響が大きいと考えられます。しかし、コネクション待ちのスレッドが偏る原因は、まだ分かりませんでした。
注4:DBCP:Tomcatとデータベースとの間で、リクエストのたびに毎回接続を行うと接続コストが高くなるため、一度接続したものを取っておき、次からはそれを使ってSQLのリクエストを行う機能です。最大同時接続数やプールする数、破棄する時間など設定することができます。Tomcatでは、Apache Commons DBCP(Commons Pool)を利用しています。
■ランプアップ中のスレッドダンプを取得し調査
偏りの原因となりそうな差がいつから出始めるのかを見極めるため、今度は、ランプアップ中に10分間スレッドダンプを出力し、調査してみました。
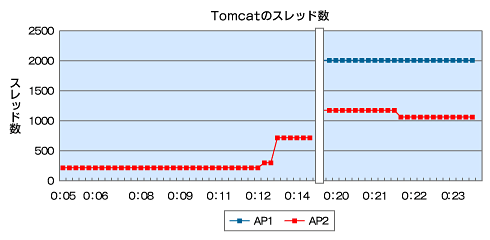 図3 結果のグラフ
図3 結果のグラフ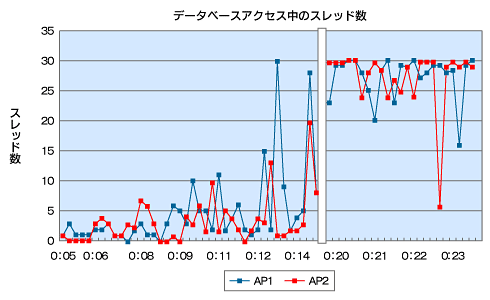 図4 結果のグラフ
図4 結果のグラフ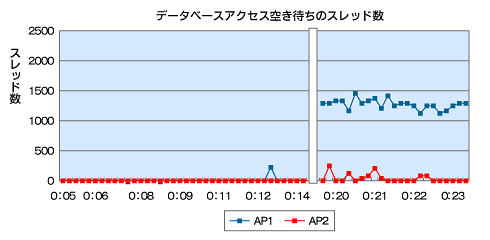 図5 結果のグラフ
図5 結果のグラフこの結果、アクセス数が多くなってスレッドが増加したときに、片方のサーバのみで「GenericObjectPool.borrowObject」で待機するスレッドが発生していることが分かりました。
●20分台(負荷が偏っている状態)
- 「Tomcatのスレッド数」には約800の差があります
- 「DBアクセス中のスレッド数」を見ると、どちらのAPもDB処理中のスレッドが限界の30に達しています
- 「DBアクセス空き待ちのスレッド数」を見ると、片方のサーバでスレッドが多く存在しており、Tomcatのスレッド数差のほとんどを占めていることが分かりました
●ランプアップ中(偏る前)
- 片方のサーバでDB接続が30に達し、接続待ちも発生してしまっています。
以下は、1分ごとの各アプリケーションサーバのアクセス数を集計した、より詳細な表です。
| 時間 | AP1 | AP2 | 合計 | 差 | 誤差 |
0:05 |
15701 |
15972 |
31673 |
271 | 0.85562% |
0:06 |
19247 |
19241 |
38488 |
6 | 0.01559% |
0:07 |
22826 |
22435 |
45261 |
391 | 0.86388% |
0:08 |
25855 |
25875 |
51730 |
20 | 0.03866% |
0:09 |
29087 |
29046 | 58133 |
41 | 0.07053% |
0:10 |
32108 | 32614 | 64722 | 506 | 0.78181% |
0:11 |
35866 | 35971 | 71837 | 105 | 0.14616% |
0:12 |
38961 | 38964 | 77925 | 3 | 0.00385% |
0:13 |
42271 | 41363 | 83634 | 908 | 1.08568% |
0:14 |
45606 | 45855 | 91461 | 249 | 0.27225% |
データベース処理待ちが発生した時間帯は「0:13」でした。数値として見ればわずか1%ですが、偏りが一番大きくなっています。ここまでの調査から、以下のような自体が発生していると判断しました。
- アクセス数が多くなると、わずかな誤差でも全体として差が大きくなるため、どちらか片方のアプリケーションサーバでデータベース処理待ちのスレッドが発生する
↓ - データベース処理待ちのスレッドが発生すると、リクエストの処理時間が長くなり、スレッド使用状況に差が生じる
↓ - 残っているスレッドがメモリを圧迫し、GC回数が増えてCPU使用率が高くなる
↓ - その後もmod_jkはほぼ均等にリクエストを送り続けるため、一度負荷の高くなったアプリケーションサーバともう1つのサーバとの間で、徐々にその差が大きくなってしまう
わずかな誤差から始まったアプリケーションサーバの負荷が広がった結果、負荷が偏っている状態であるにもかかわらず、mod_jkがリクエストを均等に振り分け続けてしまうことが問題の根本原因のようです。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。