一瞬でのバックアップを実現するSolaris ZFS:OpenSolarisで始めるブログサーバ構築(4)(1/4 ページ)
この連載では、サーバOSとして十数年発展してきた「Solaris」をオープンソース化した「OpenSolaris」を紹介し、ブログサーバ「Roller」と組み合わせて運用していくうえで有用なさまざまな知識を紹介していきます。(編集部)
前回の「Solarisコンテナでセキュリティを強化」では、仮想化技術であるSolarisコンテナを用いて、ブログサイトをセキュアな環境に移行する方法について解説しました。Solarisコンテナを用いると、思ったよりも簡単な手順で仮想環境が構築できることがお分かりいただけたと思います。
今回は、最新のSolaris ZFS(以下ZFS)ファイルシステムを用いたデータ管理方法やSolarisコンテナとZFSの組み合わせによるプロビジョニングなどの優位点を紹介します。
ZFS誕生のきっかけは「引っ越し」だった
これまでSolarisは、ファイルシステムとしてUFS(Unix File System)を採用してきました。しかしこのUFSは、20年以上も前に設計されたファイルシステムであるうえに、バージョンアップのたびにさまざまな拡張を積み重ねてきた結果、ソースコードが複雑化していました。また管理も難しくなり、パフォーマンスや拡張性という面でも行き詰まっていました。
そんなある日、サン・マイクロシステムズ(以下サン)のエンジニアチームがキャンパスの引っ越しに伴いハードディスクのアップグレードを行いました。そこで、ディスクにアクセスできないという問題が起こってしまいます。
このとき、エンジニアの1人が「メモリはマシンのカバーを開けてDIMMを差し込んで電源を入れるだけで増設できるのに、なぜ、ハードディスクでは同じようにできないのか?」と放った一言が、ZFS開発のスタートになったとか(Solaris 10ファイルシステムZFS誕生エピソード「心を解き放て!」参照)。
そこで、この20年に及ぶ陳腐化した前提を一掃し、新しいアプローチでゼロから設計したファイルシステムがZFSです。ZFSは、サンのエンジニアとOpenSolarisコミュニティのメンバーにより、さまざまなアイデアや専門知識が持ち寄られ、革新的なファイルシステムへと成長していきました。
関連記事
▼ノートPCでこそ使いたいZFS(@ITNews)
http://www.atmarkit.co.jp/news/200706/29/zfs.html
ZFSの概要と特長
ZFSは、従来のファイルシステムに存在するさまざまな問題点に取り組んだファイルシステムです。では、簡単にその特長を説明しましょう。
巨大なスケーラビリティ
ZFSは、「Zettabyte(ゼタバイトと読む)File System」の略です。「ゼタバイト」なんて、初めて耳にした人も多いのではないでしょうか?
このゼタバイトは、ビットで表すと70ビットの長さとなり、何と10億テラバイトにもなります。しかもZFSは、128ビットのファイルアドレッシングを採用しており、実に256 Quadrillion(注1)Zettabytesという膨大な大きさを表現できるファイルシステムになっています。現在のデータの肥大化がどんなに進んでも、ディスク容量のことを気にする必要はないといえます。
データの完全性と安全性
ファイルシステムにとって最も重要なことは、データの完全性と安全性ではないでしょうか?
ZFSは、従来のファイルシステムとは異なり、不慮の電源断などが起こってもファイルシステムが破壊されることはありません。fsckコマンドも、ロギングやジャーナリングも必要ありません。
ZFSは、トランザクションベースのCopy-on-write(COW)という技術を使用しています。COWではデータ変更の際、図1のように、当該ブロックの内容を未使用ブロックにコピーし、そこで変更を行ってから、最後に使用中のデータへのブロックポインタと置き換えます。これは、最上位のuberblock(注2)まで、ツリー全体に対して行われます。
すべてがトランザクションで処理されるため、ファイル操作の途中でアクシデントが発生したとしても変更前の状態に戻るだけで、データやファイルシステムが壊れることはありません。
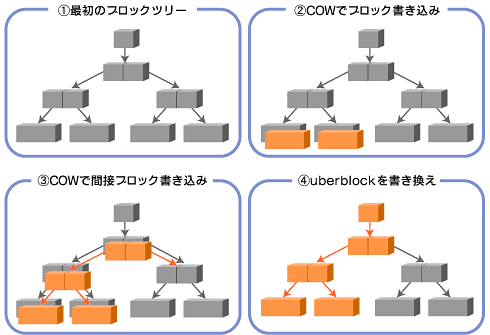 図1 COWの仕組み
図1 COWの仕組みまたZFSでは、ファイルシステム全体にわたるエンドツーエンドのチェックサムを提供します。
従来のファイルシステムは、ブロック内でチェックサムを保持していたので、自己のビット破損を防ぐだけでした。一方ZFSでは、それぞれの親ブロックのポインタにチェックサムが保存されるツリー構造になっているため、ファイルシステム全体の整合性がチェックされます(ただし最上位のuberblockだけは、自己診断を行うチェックサムを持っています)。
管理が簡単に
ZFSを使えば、新しいディスクを使うためにformatコマンドを使ってパーティショニングしたり、newfsコマンドでファイルシステムを作ってディレクトリにマウントするなんていう面倒な作業は、一切必要ありません。zpool(1M)コマンドを使ってストレージプールを作るだけです。これだけの作業で、すぐにファイルシステムを利用することができます。
冒頭で「ディスクをメモリのように扱うことができないのか」という問い掛けが、ZFS開発のスタートになったというエピソードを紹介しましたが、ZFSは、ストレージプールに仮想メモリの概念を取り入れた画期的なファイルシステムです。ディスク容量が足りなくなったら、メモリと同じようにストレージプールにディスクを追加するだけで、すぐに利用することができます。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。