故障発生時にフェイルオーバーしない?:Linuxトラブルシューティング探偵団(4)(3/3 ページ)
内蔵ディスクが故障してもアプリは動き続けた!
犯人探しは「まずログを見ろ!」というのが定石ですが、内蔵ディスク故障ということで、故障発生前後のログは取得できなかったのです(泣)。
そこでここからは、予想に従って故障を再現させてみるしかありません。実環境と同様のテストサーバを用意し、アクティブ系vividの内蔵ディスクを、勇気を出して稼働中に引き抜いてみます。
事象確認用にディスクを抜く前には、/etc/syslog.confに
*.info;mail.none;authpriv.none;cron.none @vigor |
という設定を追加し、スタンバイ系vigorにsyslogを転送するようにしてみました。さらに、vividにSSHでログインし、Heartbeatのクラスタ状態を表示するコマンド「crm_mon」を実行して、3秒ごとに状態表示させてみます。
[root@vivid ~]# /usr/sbin/crm_mon -i 3 |
さて、ハードウェア故障覚悟でvividのディスクをビビリながら抜いてみると(涙目)……vigorの/var/log/messagesに、vividのI/O errorのログが猛スピードで出力されますが、I/O error関連以外は特にエラーが見当たりません。
Jul 21 07:21:19 vivid syslogd: /var/log/messages: Read-only file system |
vividにSSHログインして動作させているcrm_monコマンドの結果を見ても、次のようにまったくの正常状態を表示し、vigorへフェイルオーバーする気配はありません。
============ →リソースは正常稼働中 |
思い出してほしいのですが、vividは強制ディスクレス状態です。いわゆる「疑似内蔵ディスク故障状態」なのです。このような状態にもかかわらず、vividはsyslogをvigorに転送し続け、crm_monも正常に動作するどころか、Heartbeatはクラスタ状態を正常と表示しています。
さらに、「内蔵ディスクを抜く前にWebブラウザで過去に接続したことのあるアプリケーション(URL)にはアクセスできた」のです。これって……。
キャッシュが犯人!?
Linux(に限らずほかのOSもそうですが)には、ディスクの内容を一度読んだらカーネルがキャッシュして、2度目以降はメモリから読み出す機構=ページキャッシュがあります。
「過去に接続したことのあるアプリケーションにはアクセスできた」という現象や、syslog転送、crm_monが動作し続けた事実からすると、Heartbeat、Apache、PostgreSQLなどのアプリケーションたちはキャッシュされ、ディスクレスでもプロセスがなくなることなく、メモリ上のみで動作してしまっていたとしか考えられません。さらに、DBなどのデータ領域は共有ディスクに置いているため、データ読み書きも可能だったと考えられます。
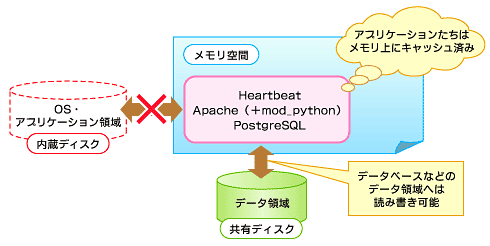 図7 原因はキャッシュだった
図7 原因はキャッシュだった実際に内蔵ディスクを抜いた後に、vigorからvividのPostgreSQLに対して“SELECT now();”のSQL文を実行させたところ、問題なく結果が出力されました。Apacheも同様で、Webブラウザからチェック用文字列が確認できたのです。
これでは、Heartbeatの立場としては正常に動作していると判断せざるを得ません。とはいえ、キャッシュを犯人扱いするのもお門違いですし……。
ここで、「そもそも、このリソースエージェントによるHeartbeatの監視方法が間違っているのでは?」という非難の声も上がってきそうですが、ApacheやPostgreSQLのプロセスが生きているかどうかの判断としては、決して間違っていないのです。
解決案は「灯台下暗し!」
そこで、HAクラスタとしての解決案を考えてみました。「内蔵ディスク故障検出を設定し、エラー検出時にフェイルオーバーさせれば良いのでは?」
って「いまさら何をいっている!」と、また非難されそうですね。しかし「内蔵ディスク故障=OS動作不能=スタンバイ系のHeartbeatが故障検知」とストレートに考えてしまうため、この設定については灯台下暗しだったのです。
そこで、ディスク監視デーモン「diskd」(※コラム参照)を使用することにしました。
今回のディスク構成では、内蔵ディスクデバイスの/dev/cciss/c0d0と、共有ディスクデバイスの/dev/sdaを監視するように設定してみます。
Filesystem 1K-ブロック 使用 使用可 使用% マウント位置 |
リソース構成の設定を行うcib.xmlには、次の設定を追加します。
<rsc_location id="rul_DK_dsc" rsc="grp"> |
サーバ基本設定を行う/etc/ha.d/ha.cfには次の行を追記して、Heartbeatを再起動します。
respawn root /usr/lib64/heartbeat/diskd -N /dev/cciss/c0d0 -a diskcheck_status -i 10 ←内蔵ディスク監視用 |
再起動後vividの内蔵ディスクを抜いてみたところ、転送されるsyslogから、I/O errorのログに交じって、diskdで内蔵ディスク(/dev/cciss/c0d0)のエラーを検出するログが確認でき、無事にvigorへフェイルオーバーしました。
Jul 21 19:07:21 vivid kernel: cciss: cmd 000001007df40000 has CHECK CONDITION byte 2 = 0x3 |
ここで解決案のHAクラスタ構成の設定ファイルをすべて記載すると長くなりますので、サンプルをダウンロードして参照してください。vivid、vigor両サーバとも、同様の設定になります。
関連リンク:設定ファイルサンプルのダウンロード
- サーバ基本
/etc/ha.d/ha.cf - サーバ認証
/etc/ha.d/authkeys - 動作環境、リソース構成、サーバの優先順位など
/var/lib/heartbeat/crm/cib.xml - ログ出力先
/etc/logd.cf
コラム ディスク監視デーモン「diskd」とは?
NTT OSSセンタでは、Heartbeatに標準装備されていなかったディスク監視デーモン(diskd)を開発し、前出のsfex同様、Linux-HA日本語サイト(http://linux-ha.org/ja/diskd_ja)からGPLライセンスで公開しています。
もともとは共有ディスクの故障検出を目的としたデーモンでしたが、今回の検証で、内蔵ディスクにも使用できることが分かりました。
強引な強制終了も1つの手
今回のようなハードウェア故障時には、OSやアプリケーションがどのような振る舞いをするかの予想は難しいです。実際にじっくり検証してみると、ページキャッシュの度合いによってやはりフェイルオーバーできなかったケースなど、さまざまな事象が出てきました。
Heartbeatには、監視対象ノードの異常を検出したときに、そのノードを強制的にダウンさせる「STONITH」というノードフェンシング機能がありますので、故障検出時にはこれを用いて強引に強制終了させ、フェイルオーバーさせるのも1つの手段かもしれません。
関連記事
Heartbeatでかんたんクラスタリング(3)"HAを見守る「Watchdog」と「STONITH」
http://www.atmarkit.co.jp/flinux/rensai/heartbeat03/heartbeat03a.html
と、4回目の俺さまをもってトラブルシューティング探偵団は解散だ! あばよー! あれ……、リーダー!? え? メモリの話も出たし、まだいい足りない? ということで、リーダーの番外編が続くぜ!
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。