ストレージをデータ保護から理解する:ストレージとは何か(2)(3/3 ページ)
ストレージの可用性
多くのストレージはHDD、キャッシュメモリでのデータ保護のほか、各コンポーネント障害がストレージシステム全体の停止を起こさぬよう、次のような対策を施している。
- コントローラ冗長化
- データ経路冗長化
- 電源冗長化
まず、2台のコントローラを専用ネットワークやバスで接続することで冗長化し、キャッシュデータの相互コピーによるデータ保護を行うとともにコントローラ自体の障害に備えている。そしてデータ経路を冗長化するには各々のコントローラのフロントエンドポートを使用する。さらにHBA、FCスイッチを冗長化することで、経路全体の冗長化も可能となる。これらのデータ経路冗長化を行うには、サーバで複数の経路(パス)を効率的に管理する(MPIO:Multi Path I/O)ソフトウェアが必要となる。このMPIOソフトウェアは、OS標準搭載の機能やストレージベンダのオプションソフトウェアとして提供されるのが一般的だ。
また、故障を想定して電源ユニットを複数で構成したり、電源系統ダウンに備え2系統以上(商用電源、UPSなど)を入力電源にすることもある。

ストレージの信頼性
システムの信頼性は、一般的にMTBF(Mean Time Between Failure)、MTTR(Mean Time To Repair)、稼働率といった指標で表されることが多い。それぞれの値は次の計算式で求めることができる。
MTBF=総稼働時間÷総故障件数
平均故障間隔 使用開始または修理を終えたシステムが次に故障するまでの平均時間
MTTR=総修復時間÷総故障件数
平均修理時間 故障したシステムの復旧に要する平均時間
稼働率=MTBF ÷ (MTBF+MTTR)
システム運用時間全体のうちの稼働時間の割合
上記のほか、MTTDL(Mean Time To Data Loss)と呼ばれるデータを消失する間隔を示す指標も利用されることがある。
しかし、実際のストレージはコンポーネント冗長化や後述する予防保守などの採用で“故障時間=停止時間”にはならない。つまり、信頼性・稼働率を重視したストレージ選択を行うには、計算による稼働率の算出ではなく、稼働率の実績値を参考にする以外方法はない。最近は実稼働率(計画停止を除いた実績稼働時間から算出した稼働率。例えば99.999%という表現は年間約5分間の不慮の停止があり得ることを意味する)を公表しているメーカーも存在する。
ここで、システム・インテグレータB社による別の事例を紹介しよう。
耐震偽装問題が話題になった建設業のC社では、各施工の工程を収めた写真を蓄積するシステムを立ち上げることになった。システム利用は24時間365日を予定しており、担当したB社は以下のようなシステムを提案した。
提案内容
- 各サーバに必要なディスクをSANストレージに配置することでバックアップを含めた運用を統合する。
- 1つのRAIDグループ(15本のHDDでRAID5を構成)から6つのLUNを切り出し各サーバに割り当てる。
各LUNの内訳は次のとおり。
- アプリケーションサーバ
OS領域、アプリケーション領域 - DBサーバ
OS領域、データベース領域 - ファイルサーバ
OS領域、画像データ領域
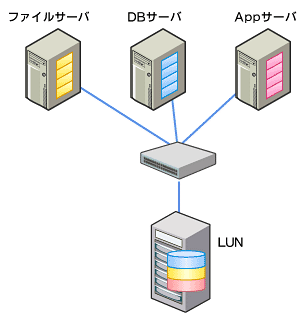 図8 B社の提案例
図8 B社の提案例これは、よく見かける構成のようだが問題はないのだろうか?
15本のHDDのうち1本の障害で縮退モードでの運用となり、2本の同時障害ではサーバ3台すべてのデータを消失し稼働を停止してしまう。従って、RAIDグループの構成で容量効率を重視する場合、RAID6やホットスペアでデータ消失リスクの低減を図るべきだ。一方、性能や縮退時の影響範囲を重視する場合では複数のRAIDグループで構成するなど用途やサービスレベルに即した設計をしてほしい。
最後に、多くのストレージで実装されている実稼働率を向上するための機能を解説する。
- オンライン・メインテナンス(ハード/ソフト)
- 自己診断機能
- 予防保守
稼働中のパーツ追加・交換などハードウェアのオンライン・メンテナンス作業は、可用性を求められるストレージでは一般的な機能である。最近の製品では、ファームウェアのアップグレードなどソフトウェアのメンテナンス作業も無停止で行うことができるものもある。
また、S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology)からの取得ステータス、メモリ、ファンなどを監視する自己診断機能も稼働率向上に貢献する。なお、S.M.A.R.T.はHDDのデータ読み取りや書き込みのエラー数、不良セクタ数など多数の項目を検査・記録する機能で、現在販売さているほとんどのHDDに搭載されている。
このような自己診断機能を故障前の交換(予防保守)に繋げることで、さらに高い稼働率を維持することが可能となる。最近では、HDDのエラーが設定した閾値を越えた時点で故障の疑いがあるとみなし、自動的にホットスペアにコピーを開始する製品もリリースされている。
今回はストレージについてデータの保護、可用性、信頼性について紹介した。次回はストレージの性能の考え方について紹介する。
参考文献:
▼RAID: High-Performance, Reliable Secondary Storage
PETER M. CHEN, EDWARD K. LEE, GARTH A.
GIBSON, RANDY H. KATZ, DAVID A. PATTERSON
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。