【DB概論】DBMSに求められるもの(2)耐障害性:できるエンジニアになる! ちょい上DB術・基礎編(3)(2/3 ページ)
回復時に実行される手順
データベースの設計を行う際に、どのようなタイミングでどのファイルのバックアップをとるべきか、バックアップファイルの種類としてどのようなファイルを取得するべきかを考慮した運用手順を設計する必要があります。 まず、回復に必要なファイルを図2で確認しましょう。
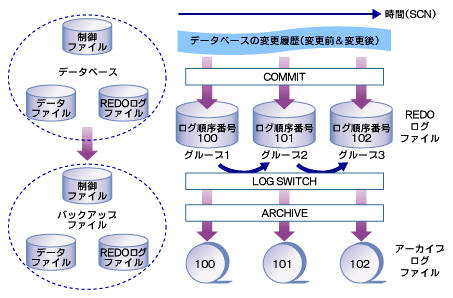 図2 回復処理フロー
図2 回復処理フロー●データベースのバックアップファイル
ディスクに物理的な障害が起きた場合、ディスクを交換し、直近に取得したバックアップファイルを戻して回復処理を行います。 そこで必要になるのが、物理的なファイルのコピーによって作成されたバックアップファイルです。 Oracleデータベースの場合、図2の左側にある、制御ファイル、データファイル、REDOログファイルの3種類のファイルのバックアップを取得します。
バックアップの種類も、「オンラインバックアップ」と「オフラインバックアップ」の2種類があります。 運用上データベースをシャットダウンできるのであれば、定期的にオフラインバックアップをとります。 データベースの全ファイルのオフラインバックアップを取得しておくと、最悪の場合でも、そのファイルを戻すことによってシャットダウン時のデータベースの状態に戻すことができます。
しかし、システムを停止することができないような場合(365日24時間フル稼働の場合)もあります。 この場合は、オンラインバックアップを取得します。
REDOログファイルは、オンラインバックアップの場合には取得しません。 REDOログファイルは、データベース内で起きたすべての更新処理をREDOログレコードという形で格納しているファイルです。
また、REDOログファイルは複数のグループで構成されていて、グループのファイルがいっぱいになると、次のグループに書き込みを継続できるようになっています(図の中ではグループ1→グループ2→グループ3)。 このグループ切替のタイミングをログスイッチと呼びます。 ログスイッチのタイミングで、アーカイブ処理とチェックポイント処理が後続で実行されます。
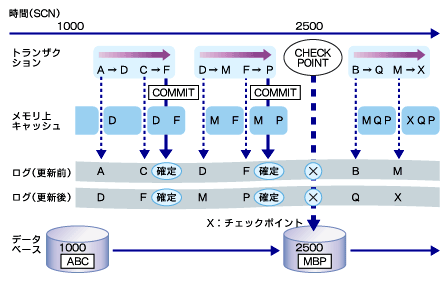 図3 バックアップ処理
図3 バックアップ処理- アーカイブ処理
アーカイブ処理は、REDOログファイルをアーカイブファイルにコピーする処理です。 REDOログをアーカイブファイルにコピーすることによって、REDOログファイルが循環利用されて上書きされても、更新ログが残るようになっています。 アーカイブファイルにもログ順序番号が割り振られ、障害時に適用する順番がわかるようになっています。
- チェックポイント
チェックポイントというイベントは、それまでにメモリ上で更新されたブロックを、データファイルに書き込むことによって、定期的にメモリ上の更新状態とディスク上のデータファイルの同期をとる処理です。
同期をとったデータファイルのヘッダには、同期をとった時刻、データベース内で使用しているSCN番号を記し、ここまでの更新ブロックがデータファイルに反映されていることを示します。
ディスク障害などが起きて、バックアップファイルを戻した場合には、このチェックポイントが完了した時点(SCN番号)を確認して、そこから回復処理を始めることができます。 また、チェックポイントの情報は制御ファイルやREDOログファイルにも記されていて、障害回復のために必要な情報として使用されます。
●トランザクションの回復手順
障害発生時の具体的な回復手順について説明します。 トランザクションがCOMMITされた場合、障害が起きてもそのトランザクションは回復でき、COMMITされていないトランザクションは、ロールバックしてデータベース内の整合性を維持する必要があると説明しました。 その仕組みについて、図4を使って説明します
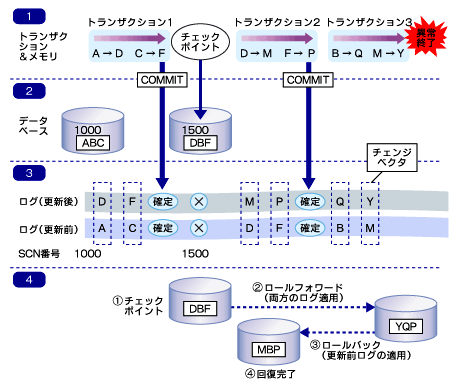 図4 回復処理フロー
図4 回復処理フロー1段目には、トランザクションの区切りとメモリ上の変更を示しています。 トランザクション1とトランザクション2はCOMMITしましたが、トランザクション3の仕掛途中にメモリ障害が発生したという想定です。
2段目はデータベースの状態を示しています。 データベースとは、ここでは物理的なファイル上の状態を表します。 メモリ上にはすべての変更が記述されていますが、データベースには変更がリアルタイムで反映されるわけではありません。
変更が反映されるイベントの1つとしてチェックポイントがあります。 ここでは、トランザクション1がCOMMITした後にチェックポイントが発生したという想定です。 チェックポイントが完了したときのSCN番号は1500で、データベースの各データファイルのヘッダには、チェックポイント完了時のSCN番号1500が記述されています。 チェックポイントによってトランザクション1の変更はデータベースに反映されていますが、トランザクション2、3による変更は、データベースには反映されていません。
3段目、4段目はREDOログファイルに記述されている更新後の情報を格納するログと更新前情報を時系列に表したものです。 REDOログファイルに書き込みが行われるタイミングはいくつかありますが、任意のトランザクションがCOMMITすると、必ずメモリ上にあった更新ログはREDOログファイルに書き込まれます。
わかりやすくするために更新前と更新後の記述を分けていますが、実際には処理の順に更新前情報、更新後情報はひとまとまりに格納されます。 処理の順がわかるようにするために、更新ログにはSCN番号が割り振られています。 また、更新前情報と更新後情報を破線で囲んでいますが、これは、ある1つの更新処理によって同時に行われるデータベース内の処理をひとまとまりにしたもので、チェンジベクタとよばれる単位です。
障害回復処理が行われる場合は、このチェンジベクタ単位の処理が必ず同期をとって実行されます。 つまり、回復処理を行う場合、更新後は表などのデータを含むブロックをSCNの順に更新、また、更新前情報を使って同時にロールバック用のブロックを更新していきます。 これが、一番下の段に記述されているロールフォワードと呼ばれる処理です。
●トランザクションレベルでみた回復の手順
4段目を見てください。 メモリが消滅してしまったような障害の場合、最後に確実にディスク上に更新が反映されたチェックポイントから回復の手順が始まります。
- チェックポイントから回復の手順開始: 最後に起きたチェックポイントの情報は、時系列の情報SCNとともに、制御ファイル、データファイルのヘッダ、REDOログファイルに記されています。 ここから適用すべきREDOログファイルを判別し、ロールフォワード処理が実行されます。
- ロールフォワード: ロールフォワード処理では、チェックポイント以降のデータブロックに対して再度REDOログを適用して更新処理をやり直します。 前述したとおり、更新後のデータブロックには更新後のログを適用し、ロールバック用のブロックには更新前情報を適用していきます。
- ロールバック: REDOログをすべて適用し終えたら、COMMITしていないトランザクションを調べて、ロールバック処理を行います。 2.でロールバック情報も、ロールバックセグメント内のブロックに対して再作成されているので、これを使って時系列を逆に遡って処理していきます。 ロールバック情報はトランザクション単位に管理されていて、逆方向にポインタをたどっていけるようになっています。
- トランザクションがCOMMITされた状態またはロールバックされた状態になり、データベースとして整合性のとれた状態になった時点で、障害回復作業は完了します。
複数のトランザクションが同時に進行している場合、障害回復処理がどのように実行されるかを、確認してみます。
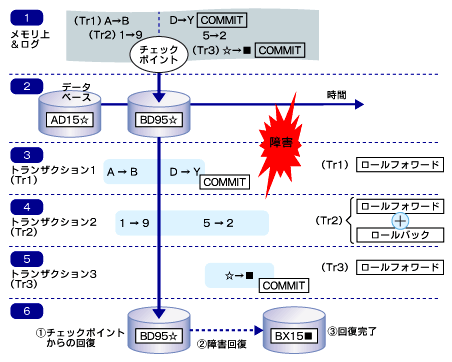 図5 回復フロー
図5 回復フロー1番上の段は、メモリ上の処理を示しています。 途中でチェックポイントが実行されています。
2番目の段は、データベースの「物理的なデータファイル内の、あるブロック内の値」を示しています。 チェックポイントが起きた時点で、メモリ上の変更はデータベースに反映されています。
3〜5番目の段は、3つのトランザクションの処理が実行されていることを示しています。 トランザクション1と2はチェックポイントの前から処理は実行されており、トランザクション1と3は、障害が起きる前にCOMMITが完了していることに注目してください。 このような状況で、障害が発生したとします。障害回復の開始点は、チェックポイントが起きた時です。 トランザクション1と3はCOMMITされていたため、完了状態まで回復されます。トランザクション2は仕掛中だったため、ロールバックされて、何も実行されなかった状態に戻される必要があります。
6番目の段は、回復した後のデータベースの状況を表しています。
●ディスク障害からの回復
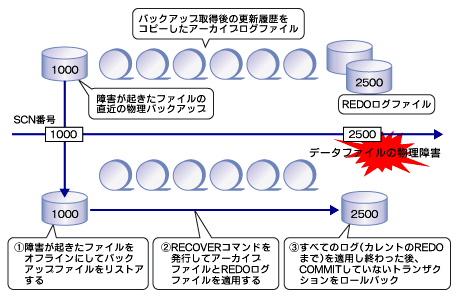 図6 ディスク障害からの回復
図6 ディスク障害からの回復メディア障害から回復するためには、図6に示すように物理バックアップ、REDOログファイル、アーカイブログファイルの3つのファイルが揃っている必要があります。
障害回復処理は、大きく分けると次の3つの工程になります。
- 障害が起きたファイルをオフラインにし、バックアップファイルをリストア
- バックアップファイルに記されているチェックポイント番号から後の更新ログを格納しているアーカイブログファイルを順次適用
- アーカイブされていない更新ログを含むREDOログファイルを適用し、COMMITされていなかったトランザクションをロールバック
回復処理時間を短くするためには、次のことに留意します。
- リストア時間を短くするために、バックアップの単位になっている、物理的なパックアップファイルのサイズを大きくしすぎない
- アーカイブログファイルの適用時間を短縮するために、頻繁に更新されるデータファイルは頻繁にバックアップを取得し、適用すべきアーカイブログファイルが少なくてすむようにする
回復に必要な手順は、バックアップの取得方法によって大きく異なります。 バックアップ/リカバリ用の専用ツールを使う場合、上記の説明は当てはまりませんが、基本的な考え方は同じでしょう。
データベース設計の中で物理設計をする際、障害回復の手順を明らかにしておくことによって、回復処理をなるべく簡潔に、早く終了させることができると考えられます。 障害時に最も危険なのが、オペレータの誤処理による二次災害です。 データベースの内部構造をしっかり理解しておくことによって、落ち着いた処理ができるように心がけておいてください。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。