試すのが難しい―機械学習の常識はMahoutで変わる:ビッグデータ処理の常識をJavaで身につける(4)(3/3 ページ)
クラスタリングの実行と結果の検証
クラスタリングの実行には、今回は「Canopy」「K-Means」という2つのアルゴリズムを使いました。Canopyによって、「入力データをいくつのクラスタに分けられそうか」大まかに調べ、その結果を踏まえてK-Meansできっちり分けます。
【5】アルゴリズム実行
まず「Canopy」「t1」「t2」オプションは大ざっぱにいうと、期待するクラスタの最大半径・最小半径、「dm」オプションは距離計算方法です。
$MAHOUT_HOME/bin/mahout canopy \ --input data/vector/tfidf-vectors \ --output data/canopy \ --t1 0.89 \ --t2 0.75 \ -dm org.apache.mahout.common.distance.CosineDistanceMeasure
結果が安定するまで何回か繰り返し計算されるので、最終回の結果を「--clusters」オプションに渡して「kmeans」を実行します。
$MAHOUT_HOME/bin/mahout kmeans \ --input data/canopy \ --output data/kmeans \ --clusters data/canopy/clusters-*-final \ --maxIter 20 \ --convergenceDelta 0.01 \ --clustering \ ……最後に全データをクラスタに分類 -dm org.apache.mahout.common.distance.CosineDistanceMeasure
K-Meansは渡されたclustersの中心点を初期状態として、最大でmaxIterの回数まで中心点の位置を計算しなおし、前回との差異がconvergenceDeltaより小さくなれば処理を終了します。
【6】結果表示
クラスタリングの出力もSequenceFileで、「hadoop fs -text」コマンドで見ると、以下のようになっています。
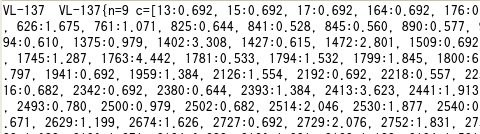
「VL-137」というクラスタに分類されたレコード数(n=9)と中心点(c=[13:0.692, ... ]ID13の語が0.692の重みで登場する……)を表していますが、数字だけでは意味が分かりません。Mahoutの「clusterdump」コマンドを使うと、ベクタ化の際に作られた辞書を参照して、各クラスタに特徴的な語が分かるように表示してくれます。
$MAHOUT_HOME/bin/mahout clusterdump \ --output clusterdump.txt \ --seqFileDir data/kmeans/clusters-*-final \ --pointsDir data/kmeans/clusteredPoints \ --dictionary data/vector/dictionary.file-* \ --dictionaryType sequencefile \ -dm org.apache.mahout.common.distance.CosineDistanceMeasure \ --numWords 30 ……表示するTop Termsの数
出力されたテキストファイルを見ると、まず先ほどと同じ内容が日本語になって表示されます。

続いて、このクラスタに多く登場する語が表示されます。
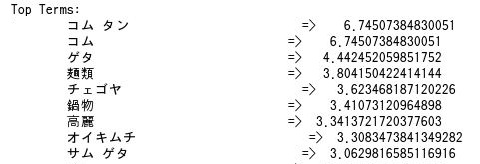
最後に、このクラスタに分類されたレコードが表示されます。どうやら、このクラスタには韓国料理店が分類されたようですね。
【7】結果評価
期待に沿うクラスタリングができているか評価します。クラスタの数は妥当そうか、きれいに分かれている(クラスタ中心点同士は離れていて、各クラスタ内の点は中心に集まっている)か、などが指標になります。
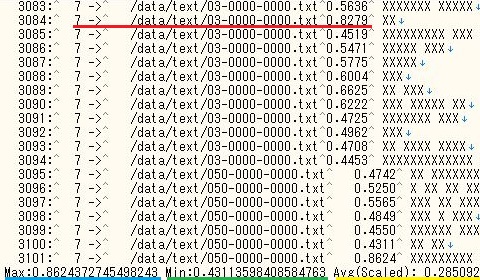
中心点同士の距離、中心と各点の距離はMahoutのDistanceMeasureクラスやHadoopのSequenceFile.Readerクラスを使ってこのように計算できます。
List<WeightedVectorWritable> points = pointsMap.get(clusterName);
DistanceMeasure measure = new CosineDistanceMeasure();
for (WeightedVectorWritable point : points) {
double d = measure.distance(
cluster.getCenter(), point.getVector());
……
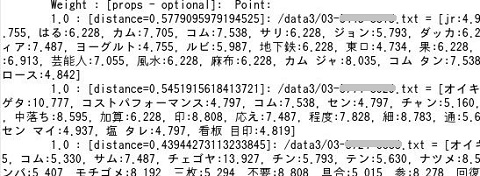
例えば下図では、クラスタ中心から各レコードへの距離(赤線部分)、その最大(青)・最小(緑)・平均値(黄)を表示し、また、(図では伏せましたが)店名を元のテキストファイルから引いて表しています。
普通いっぺんで期待通りにはならないので、結果を踏まえて各ステップを見直し、実行、評価を繰り返しましょう。
Java技術者なら機械学習は簡単に試せるようになった
機械学習は、とっつきにくいと思われがちで、実際、幅広い知識が必要ではありますが、理屈はさておきデータを分析してみると学べることも多いものです。MahoutはJava技術者なら簡単に動かせますので、まずはそこから機械学習に近づいてみてはいかがでしょうか。
機械学習の参考資料
機械学習については書籍やインターネットの情報が多数あります。用語解説や書籍紹介など情報量の豊富な「朱鷺の杜Wiki」、初心者にも分かりやすく理論と実装を解説している「機械学習はじめよう」を入り口としてお勧めします。
著者紹介
横田 明子(よこた あきこ)
2011年、現部門に異動しHadoopとMahoutに出会う。
ビッグデータ周辺のにぎわいと機械学習の奥深さに圧倒されつつも、社内にHadooperを増やすべく、宣伝啓蒙活動に日々余念がない。TIS先端技術センターでは、採れたての検証成果や知見などをWebサイトで発信中
関連記事
- テキストマイニングで始める実践Hadoop活用
- 次世代Hadoopの特徴は、MapReduce 2とGiraph
Hadoopの父に聞く、HadoopとClouderaの現在・未来 - Javaで覚えるIT技術者の40の常識
新人プログラマ/SEは覚えておきたい“まとめ” - 実践! Rで学ぶ統計解析の基礎
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。