管理が困難―分散処理の常識はZooKeeperで変わる:ビッグデータ処理の常識をJavaで身につける(8)(1/3 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
分散処理の課題が「管理」なのは常識
複数の計算機上で動作(分散)するアプリケーション、ソフトウェアが多く存在します。分散ソフトウェアは複数の計算機で動作することで大量のデータを扱えたり、高負荷な状況に対処します。本稿では、複数の計算機(クラスタ)で動作する各サーバを「インスタンス」と呼びます。
本連載で紹介した分散Key-Valueデータベースである「HBase」は複数の計算機で動作する代表的なソフトウェアです。両ソフトウェアはともに「Apache ZooKeeper」(以下、ZooKeeper)という「コーディネーションエンジン」を組み込んでいます。本稿では、このZooKeeperを紹介します。ここでいう「コーディネーションエンジン」は分散システムのコーディネートを支援するサービスを提供するエンジンです。

コーディネーションエンジンであるZooKeeperについてお話しする前に複数の計算機上で動作するソフトウェアのインストールおよび保守管理を考えてみます。
複数の計算機で動作するソフトウェアは分散環境(クラスタ)を構成する各計算機上にソフトウェアをインストールし、それぞれに設定を記述する必要があります。複数の計算機に設定を書くことは面倒ですが、その大半を手動でもコピーできるので、それほど問題にはなりません。
分散環境で動作するシステムで特に問題になるのは、運用中に環境が変化したときです。
■システムの一部欠損
例えば、あるサービス上でユーザーからのクエリを受ける機能があったとします。検索機能を実現するため、複数のデータベースサーバに検索クエリを投げるスクリプトが配備されました。その後検索を受け付けていたデータベースの1つが壊れた場合、ユーザーがいくら検索を発行しても検索結果は返ってきません。
このような場合、システムを運用している人は同じインデックスをコピー(replication)していた計算機にクエリを発行するように、スクリプト(もしくはスクリプトが読む設定ファイル)を手動で書き換える必要があります。
■設定のアップデート
分散データベースやファイルシステムの容量が限界に近くなった場合、新しくインスタンス(計算機)を追加する必要があります。このような場合、システム全体を1度落として、設定ファイルを新しいインスタンスを追加する部分を書き足して再びクラスタを立ち上げると、大きなコストになります。
計算機の追加以外にもクラスタの運用中に設定を変更する必要機会は多く存在します。このようなときは、「1つの計算機の設定を書き直すことで、その設定変更がクラスタ内のほかの計算機に動的に波及する」という仕組みが重要になります。
コーディネーションサービス「ZooKeeper」とは
ZooKeeperは上記のような分散環境で動作するソフトウェアを運用するうえでの困難を低減するためのサービスを提供します。通常このようなサービスは「コーディネーションサービス」と呼ばれます。
ZooKeeperは多くのサービスツールで利用されていますが、具体的には以下の目的で利用されます(以下で紹介する状況以外にも利用する状況はあります)。
■共有設定
複数のインスタンスを使用するシステムで設定の共有ファイルをZooKeeperに保存します。設定ファイルをZooKeeperサーバに保存し各インスタンスがZooKeeperに保存される設定ファイルを取得することで、各インスタンスの設定ファイルが同一であることを保証できます。
■分散Lock
分散環境で動作するソフトウェアが1つの共通リソースを利用していることを考えます。このとき、分散環境中の2つのインスタンスが同時に共有リソースを書き換えてしまうと、値の整合性が取れなくなってしまいます。ZooKeeperを利用することで分散環境で利用可能なロックを構築できます。
■メンバー取得
分散システムの各インスタンスからZooKeeperの「エフェメラルノード」(後述)を登録しておくことで、分散システム内で利用可能な状態にあるインスタンスの一覧を取得できます。これによりクライアントはアクティブ状態のサーバに確実に接続できます。
ZooKeeperの基本構成
前節「コーディネーションサービス「ZooKeeper」とは」でZooKeeperの利用が必要とされる環境について紹介しました。本節では、ZooKeeperが提供する機能について詳しく解説してゆきます。
ZooKeeperは小規模のファイルシステムを提供します。ファイルシステムは複数の計算機で共有され、各インスタンスはZooKeeperが提供するファイルシステムに保存されたデータにアクセスすることで最新の設定事項や環境の変化を知ることができます。
■データモデル
前節で紹介したようにZooKeeperはファイルシステムを提供します。UNIX ファイルシステムと同様に各ファイル(ノード)へのアクセスはスラッシュ「/」で区切られたパスでアクセスされます。
例えば下図で、ファイル「bar」へのアクセスは、「/foo/bar」で行われます。
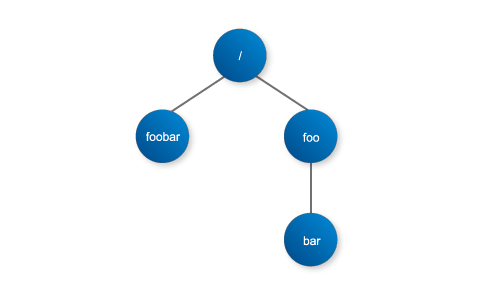
実際に利用する際は、各ファイルにはクラスタアプリケーションの設定やクラスタに参加する計算機名などを保存します。ZooKeeperが提供するファイルシステムは通常のファイルシステムと同様に何でも追加できますが、巨大なデータ保存する目的では利用できません。
ZooKeeperがファイルシステムとして特徴的なのは、「Znodeはファイルであると同時に、子ノードを持つディレクトリになれる」という点です。例えば、図で「foo」は小ノード「bar」を持ちますが、「foo」自体にファイルを保存できます。
■ノードの種類
ZooKeeperが提供するノードには、通常のもののほかに「エフェメラル(ephemeral)ノード」が存在します。エフェメラルノードは、通常のノードと同様に、アクセス(読み込み、書き込み)できますがノードを作成したプロセスとのリンクが切れてしまうと自動で消失します。
例えば、複数のインスタンスからなるクラスタを形成するアプリケーションを考えてみます。クラスタ内の各インスタンスがエフェメラルノードをZooKeeperに登録することで、現在利用可能なサーバ一覧を得られます。もしインスタンスが再起動などで利用可能状態でなくなると、エフェメラルノードは削除されます。クラスタに接続して処理を行うクライアントプログラムが合った場合に、利用可能でないサーバを避けて接続できます。
次ページでは、引き続き ZooKeeperの基本構成を解説し、ZooKeeperを利用するソフトウェアやZookeeperを使うための環境構築の仕方を紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。