第4回 ストレージの利用効率を高めるデータ重複除去機能:Windows Server 2012クラウドジェネレーション(1/2 ページ)
Windows Server 2012ではファイル内に含まれる重複したデータを自動的に検出して除去する機能が用意された。場合によっては8割以上ものディスク領域のスリム化が図れるという、待望の機能を解説する。

今回はWindows Server 2012の新機能「データ重複除去機能」を紹介する。「重複除去って何?」というところから、Windows Server 2012における仕様や実装、インストール手順、管理方法まで解説する。
「データ重複除去」技術とは
データの重要性が高まり、ますますストレージの大容量化が求められる現代のITシステムだが、ユーザーの要求に応じていくらでも無尽蔵に容量を追加できるわけではない。コストや信頼性、パフォーマンス、運用性、バックアップの手間などを考えると、何らかの方策でディスクの使用量を抑制したいところだ。
このような場合に使われる技術としては、例えばデータを圧縮したり、重複したファイルを1つにまとめてディスクの使用領域を節約したりするといった方法がある。最近ではさらに進んで、ファイルの内容を解析して重複したデータ領域を見つけ、複数のファイル間で同じデータ領域を共有してディスクを節約するという、「データ重複除去(Data Deduplication)」技術も使われている(「重複排除」とも呼ばれる)。ファイル・サーバ上にはさまざまなファイルが保存されているが、その内容をよく調査すると、実際には重複している部分が多い、という結果などに基づいて開発された技術である。当初はバックアップ・システムなどで使われることが多かったが、現在ではファイル・サーバやNAS(Network Attached Storage)などでも採用が進んでいる。
例えばビジネス文書などでは、1つのマスター・ファイルを元にして、少しずつ更新しながら使うことが多いため、ファイル数は多くてもファイルの中は似通っていることが多い。また仮想マシンをホスティングする場合、1つのマスターとなる仮想ディスク・イメージから多数の仮想マシンを派生させて作成、運用していることが多い。OSやアプリケーションのインストール用に大量のCD/DVDイメージを保存している場合もあるだろう。これらの用途では、重複する部分を除外すれば、全体としての必要ディスク量は、半分もしくはそれ以下になることも少なくない。ファイル単位で一致しているかどうか調べるのではなく、ファイルの中の任意のブロック単位で一致している部分を検出して重複を排除すれば、ファイルごとに圧縮する場合よりもディスクの利用効率が高くなる傾向にある。
Windows Server 2012の新機能「データ重複除去」
Windows Server 2012で新しく導入された「データ重複除去」は、複数のファイル間で重複するデータ領域を取り除いて1カ所にまとめ、全体的なディスク使用量を抑制する機能である。OS内部に組み込まれている機能であるため、ユーザーから見たファイル・システムは従来とほぼ完全に互換性を保っている。また重複した領域の検出やファイル間での共有化処理、最適化処理などは、CPU負荷の低いときにバックグラウンドで行われるため、ユーザーが重複除去を意識することはほとんどない。
 Windows Server 2012のデータ重複除去機能
Windows Server 2012のデータ重複除去機能Windows Server 2012では、OSの標準機能としてデータ重複除去機能が用意されている。ほとんど管理の手間もいらないし、従来のファイル圧縮機能よりも高い性能を示す(より多くの空き領域が確保できる)傾向がある。
Windows OSでは以前から「単一インスタンス ストア(SIS)」という機能が利用できたが、これは重複しているファイルを除去する機能しか持っていなかった。Windows OSのインストール/展開用サーバなどにおいて、完全に一致しているファイルを見つけて1つにまとめ、ディスク領域を節約するためのものである(OSのインストール・イメージには同じファイルが多数含まれていることが多い)。
これに対してWindows Server 2012のデータ重複除去では用途を問わず、ほとんどのケースで問題なく利用できるだろう。その特徴的な機能は次の通りである。
| 機能 | 概要 |
|---|---|
| シームレスな重複除去機能 | OSの標準機能として統合され、処理はすべてOS内部で行われるので、重複除去機能についてユーザーが意識することはない |
| 高い重複除去性能 | ファイル単位での単一化やクラスタ単位での圧縮機能と違い、より小さい(可変長の)ブロック単位で重複データを除去できるので、結果的にはより高いディスク領域の節約が期待できる |
| スケールとパフォーマンス | 重複除去はシステムが低負荷時に行われるため(スケジュール指定することも可能)、ユーザーのアクティビティに影響を与えることなく、機能を利用できる。 |
| 使い慣れたツールによる管理 | 重複除去機能は、ボリューム単位で簡単に有効/無効を設定できる。管理はサーバ・マネージャもしくはPowerShellで行う |
| BranchCacheサポート | BranchCacheサービスと連携し、要求されたデータ(チャンク)を素早く見つけ、送信できる |
| 最適化された状態でのバックアップ | Windows Server 2012に付属のバックアップ・ツールでは、重複除去された状態でのバックアップが可能(つまりバックアップ・サイズも少なくて済む) |
このデータ重複除去はボリューム単位で有効/無効を設定できるため、データベースやデータ更新の多いボリュームでは従来通りの使い方をしながらも(特定のフォルダや拡張子のファイルだけ除外することも可能)、それ以外の一般ユーザー向けボリュームやアーカイブ的なボリュームでは有効にする、といった使い分けが簡単にできる。対象となるファイルの種類にもよるが、一般的には次のようなディスク使用量の削減効果が得られるとされている。
| 用途/種類 | 期待できるディスク削減効果 |
|---|---|
| ユーザー・ドキュメント(一般的なオフィス文書など) | 30〜50% |
| 展開用共有(ソフトウェア・バイナリ、CABファイル、シンボル・ファイルなど) | 70〜80% |
| 仮想化ライブラリ(仮想ディスク・ファイルなど) | 80〜95% |
| そのほかの一般ファイル | 50〜60% |
ファイル・サイズが小さすぎたり(デフォルトでは32Kbytes未満)、ファイル間で重複するデータ領域が少ない、もしくはほとんど共通部分がないファイル・タイプの場合は、ファイルは元のまま保存され、ディスク領域は削減されない。例えば次のようなファイルが該当する。
- アーカイブ・ファイル/圧縮ファイル――ZIPやLZH、CABなどの圧縮ファイル
・写真/音声/映像ファイル――JPGやPNG、MP3、MOVなどのマルチメディア・ファイル
ただしこれらのファイルでも、同じ内容のファイルが複数存在していれば、1つ分にまとめられるので、ディスク領域削減の効果は期待できる。
システム・ボリュームやいくつかの特殊なファイル/フォルダも重複除去の対象外となっている。具体的には次のようなものがある。
- 拡張属性付きのファイル
- 暗号化されたファイル
- 32Kbytes未満のファイル
- リパース・ポイント・ファイル
- システム・ボリューム、ブート・ボリューム
- 非NTFSボリューム
- クラスター共有ボリューム(CSV)
- ReFS(Windows Server 2012の新ファイル・システム)ボリューム
- 単一インスタンス・ストア(SIS)ボリューム(共存は不可)
またファイルの更新頻度のことなどを考えると、次のような用途には向かない。
- Hyper-V ホスト
- VDIホスト
- WSUSサーバ
- SQL Server、Exchange Serverのサーバなど
- そのほか、更新頻度が高いファイル、常にオープンされているようなファイルなど
ddpeval.exeコマンドでデータ削減効果を見積もる
データ重複除去機能を導入すると、どの程度のディスク使用領域の削減(節約)が期待できるのか、あらかじめ知りたいこともあるだろう。その場合は「ddpeval.exe(Data Deduplication Savings Evaluation Tool)」というツールを使って事前評価するとよい。これは、Windows Server 2012のデータ重複除去と同じアルゴリズムで動作する評価用のツールだ。実際にファイル・システムに書き込むことはなく、結果を表示するだけのツールである。
Windows Server 2012に「データ重複除去」機能をインストールすると(具体的な手順は次ページ参照)、C:\Windows\System32フォルダに「ddpeval.exe」というツールがインストールされる(これをWindows Server 2012 から、ほかのWindows 7やWindows 8、Windows Server 2008 R2、Windows Server 2012などにコピーして実行してもよい)。Windows Server 2012のローカル・ドライブのほか(システム・ドライブやブート・ドライブ、すでにデータ重複除去機能を導入したボリュームに対しては使用不可)、リモートの共有フォルダ(Windows Server 2012の共有フォルダでなくてもよい)などを指定して実行する。ヘルプは「ddpeval /?」で表示される。
次の例では、各種Windows OSのインストールCD/DVDイメージが保存された「f:\osimage」フォルダを指定して実行している(完了までにはかなりの時間がかかる)。
E:\osimage>ddpeval e:\osimage
Data Deduplication Savings Evaluation Tool
Copyright (c) 2012 Microsoft Corporation. All Rights Reserved.
進行評価されたフォルダー: e:\osimage …対象フォルダ
評価されたフォルダーのサイズ: 50.11 GB …ファイルの合計サイズ
評価されたフォルダーのファイル: 901 …総ファイル数
処理されたファイル: 345 …削減対象ファイル数
処理されたファイル サイズ: 50.10 GB …削減対象の数合計サイズ
最適化されたファイル サイズ: 7.55 GB …削減後の総合計サイズ
領域の節約: 42.56 GB …これだけ削減できる
領域の節約割合: 84 …84%も削減できる(元の16%になるということ)
最適化されたファイル サイズ (圧縮なし): 7.88 GB …最終的な総ファイル・サイズ
領域の節約 (圧縮なし): 42.22 GB …最終的な削減サイズ
領域の節約割合 (圧縮なし): 84 …最終的な削減率は84%
ポリシーで除外されたファイル: 556 …削減対象ではないファイル数
小さいファイル (32 KB 未満): 556 …その内訳
エラーで除外されたファイル: 0
E:\osimage>
指定したフォルダには32Kbytes以上のサイズのファイルが全部で901個あり、その総サイズは50.11Gbytesである(そのほとんどはCD/DVDイメージの.isoファイル)。重複除去させると、最終的には7.88Gbytes(元の16%)まで削減される、という意味である。このように、ファイルの種類によっては8割以上削減できる可能性がある。
データ重複除去のしくみ
ここでデータ重複除去機能の仕組みについて簡単に見ておこう。
データの重複を検出する一番簡単な方法としては、例えばファイルを先頭から32Kbytesずつに分割してそれぞれのハッシュ値を計算し、一致するブロックを検出する、というような方法が考えられる。だがこのような単純な方法では、例えばコピーしたファイルの一方の先頭に1bytesのデータを挿入するだけでハッシュ値が一致しなくなり、重複を検出できなくなってしまう。
ファイル・サーバや通信路の占有帯域を削減する目的で現在広く使われている重複除去手法としては、例えば、ファイルを「チャンク(chunk)」と呼ばれる可変長のブロックに分割して(※1)、チャンク単位で内容が一致しているかどうかを判定するという方法がある。同じチャンクを持つファイルが複数あれば、チャンクのデータを1つだけ保存して残りは廃棄し、そのチャンクへのリンクで置き換えれば、領域を節約できる。Windows Server 2012のデータ重複除去処理では、32K〜128Kbytesの可変長のチャンクを使用している(平均で64Kbytes程度)。
※1 チャンクへの分割には、「Rabin fingerprint」ベースのスライディング・ウィンドウを使っているとのこと。同じサイズではなく、同じ内容になるようにチャンクを分割しているため(チャンクのサイズや切り分け方などで効率やパフォーマンスが違ってくるため、さまざまな方法が考案されている)、ファイル中の場所が違っていても重複を検出できる。
チャンクは圧縮後、まとめて1つのファイル(チャンク・ストア)へ記録し(1Gbytesごとに別ファイルにする)、ボリュームのルートにある特別な場所(「System Volume Information」フォルダ)に保存している。重複除去後の元のファイルはリパース・ポイントに置き換え、元のデータ・ストリームを再現するようにチャンクをリンクさせるマップを指すように変更している。
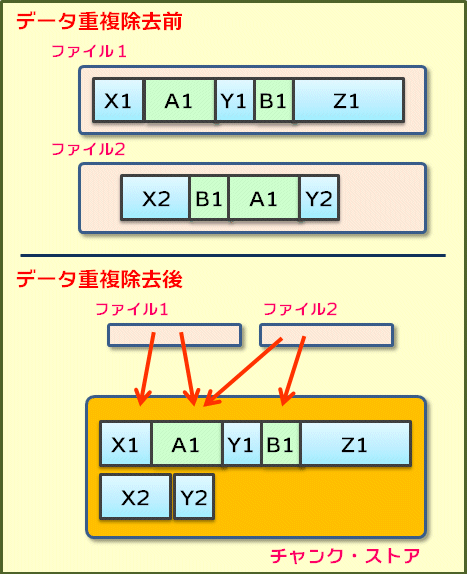 データ重複除去の仕組み
データ重複除去の仕組みボリューム上に記録されたファイルは可変長の「チャンク」というブロックに分割され、重複するものを除いてチャンク・ストア内に保存される。元のファイルはリパース・ポイントに変更され、複数のチャンクをつないで、元のファイルを再現できるようにする。
ファイルのコンテンツをまとめてチャンク・ストアに保存しているので、場合によってはディスクからオリジナルのファイルを読み出すよりも高い性能が期待できることがある。
ファイルへ書き込む場合は、チャンク・データはそのままにして、通常のファイル書き込み時のように、新しいブロック(クラスタ)を割り当ててそこへ書き込む。場合によってはチャンクと通常クラスタが混在することになるが、これはNTFSのスパース・ファイルの機能で対応する。
ファイルを削除した場合(および上書きした場合)はチャンク・ストア内に不要なデータが残ることになるので、後で最適化処理を行う。デフォルトでは週に1回、最適化やエラー・チェック、ガベージ・コレクションのジョブが実行される。チャンクをすぐに削除しないので、必要ならエラー発生時の冗長リカバリ用データとして使うこともできるし、よく使われるチャンクは複数保存して性能向上を図るなどの手法も併用されている。
- Introduction to Data Deduplication in Windows Server 2012[英語](TechNetブログ サイト)
- Data Deduplication API (Windows)[英語](MSDNサイト)
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。