インデックスオンリースキャンを試す:もう一度始めたい人のPostgreSQL(3)(2/2 ページ)
インデックスオンリースキャンの性能検証
インデックスオンリースキャンの性能を検証してみましょう。検証環境は以下の通りです。

対象とするテーブルはこれまでと同様のaidテーブルで、30万件のデータを選択します。EXPLAIN句にBUFFERSとANALYZEをオプションで指定すると、共有バッファからの読み取りページ数・ファイルからの読み取りブロック数と、そのクエリの実行時間を表示できます。また、SETコマンドを用いて、インデックスオンリースキャンを利用しないように設定できます。
postgres=# SET enable_indexonlyscan TO off ;
SET
postgres=# EXPLAIN (BUFFERS,ANALYZE) SELECT aid FROM pgbench_accounts WHERE aid < 300000 ;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.00..13452.71 rows=299899 width=4) (actual time=0.100..355.221 rows=299999 loops=1)
Index Cond: (aid < 300000)
Buffers: shared read=5742
Total runtime: 445.812 ms
(4 rows)
このように、インデックスオンリースキャンの代わりにインデックススキャンが使われています。
今回は、enable_indexonlyscanをonの状態とoffの状態とを織り交ぜて、クエリを8回ずつ実行してみました。
それぞれの状態のバッファヒット率、ブロック数、実行時間の平均値を比較してみます。ここでいうバッファヒット率とは、読み込んだインデックスとテーブルデータがどれだけ共有メモリに乗ったかを示すもので、EXPLAIN句のBUFFERSオプションの出力結果から算出しています。
下記のグラフの通り、クエリの実行時間(duration:単位はミリ秒)は、インデックスオンリースキャンでは通常スキャンの50〜60%程度で済んでいます。また、通常スキャンの方が値のばらつき(標準偏差:グラフに示された点線で単位はミリ秒)が大きくなっています。また、インデックスオンリースキャンは通常スキャンに比べてバッファヒット率(hit_ratio:単位は%)が高くなっています。ブロック数(block:単位はMB)はインデックスオンリースキャンでは通常スキャンの約7分の1となっています。
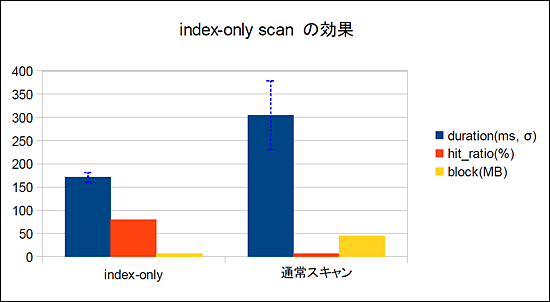 性能計測結果
性能計測結果今回のテスト環境ではOSのメモリに余裕があり、OSレベルのバッファヒット率が高くなっています。しかし、インデックスはメモリに乗っても、テーブルが乗らないようなメモリが不足している環境では、インデックスオンリースキャンではテーブルデータの読み込みが発生しないため、所要時間の差はさらに広がることが想定されます。また、参照するデータが散らばって存在する場合には、ディスクシークのコストと読み込まなければならないブロック数が増えて、通常スキャンがより遅くなると言えます。
インデックスオンリースキャンが使えない条件
最後に、インデックスオンリースキャンが使えない条件を確認しておきましょう。インデックスオンリースキャンは参照するページに変更されたデータがあり、まだVACUUMが済んでいない状態では利用できません。
追記型のアーキテクチャであるPostgreSQLでは、特定のトランザクションにおいて取得したいテーブルデータが可視であるかどうかは、ビジビリティマップという機能によって管理されています。インデックスオンリースキャンはこのビジビリティマップを利用していましたね。データ変更後、VACUUMによってビジビリティマップが更新されない間は、インデックスオンリースキャンを使うことができません。
postgresql.confファイルでVACUUM機能をオフにしたうえでpgbenchを使って、pgbench_accountsテーブルに多数のUPDATEを行います。その後にEXPLAINを実行してみます。
| 変更するパラメータ | パラメータの説明 |
|---|---|
| autovacuum = off | 自動バキュームの有効化 |
postgresql.confファイルはデータベースクラスタのディレクトリ内に存在します。
[postgres@node1 ~]$ pg_ctl reload server signaled [postgres@node1 ~]$ LOG: received SIGHUP, reloading configuration files LOG: parameter "autovacuum" changed to "off" LOG: autovacuum launcher shutting down [postgres@node1 ~]$ pgbench -n -c 10 -t 100 -U postgres postgres
postgresql.confファイルを編集したので、pg_ctlコマンドでファイルをリロードします。その後、pgbenchでベンチマークを実行します。-nオプションでベンチマーク実行前のバキューム処理をスキップします。-cオプションでクライアントの同時接続数を指定します。-tオプションで各クライアントが実行するトランザクションの回数を指定します。pgbenchで実行されるトランザクションは銀行の口座処理を模しており、いくつかのSELECT、UPDATEと、1件のINSERTからなっています。
[postgres@node1 ~]$ psql -d postgres -U opstgres
[postgres@dhcp-177-168 ~]$ psql
psql (9.2.4)
Type "help" for help.
postgres=# EXPLAIN SELECT aid FROM pgbench_accounts WHERE aid < 300000 ;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------
Index Only Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.00..8603.69 rows=301365 width=4)
Index Cond: (aid < 300000)
(2 rows)
データベースに接続してEXPLAINを実行してみます。一見すると、インデックスオンリースキャンが使われているように見えますが……。
postgres=# EXPLAIN (BUFFERS,ANALYZE) SELECT aid FROM pgbench_accounts WHERE aid < 300000 ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.00..8603.69 rows=301365 width=4) (actual time=0.209..188.913 rows=299999 loops=1)
Index Cond: (aid < 300000)
Heap Fetches: 68821
Buffers: shared hit=3184 read=961
Total runtime: 244.272 ms
(5 rows)
EXPLAINにBUFFERSとANALYZEオプションを指定して実行してみると、実際には、「Heap Fetches: 68821」という結果が出力されています。これは、68821行についてはインデックスのみでなく、ヒープ(テーブル本体)からデータを参照したことを表しています。
以上、3回にわたってPostgreSQLの最新バージョンの主な特徴を紹介させていただきました。
執筆時点では次期メジャーバージョン 9.3に向けたベータ版がリリースされており、これまでのメジャーバージョンアップと比較しても多数の新機能が追加されています。着実に、今後もますますの機能の充実が図られていくPostgreSQLに、ぜひとも一度触れてみてください。
正野 裕大
SRA OSS, Inc. 日本支社 マーケティング部
大学ではITとあまり縁のない分野を専攻しつつもOSSの世界に飛び込み、日々勉強中の身。PostgreSQLエンジニアとして、トレーニング、サポート、PostgreSQLベースのプロダクト開発などを担当。プライベートでは去年の夏に結婚し、新婚生活を満喫中。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。