Apache Mahoutの使い方:テキスト分類のアルゴリズムを活用する:Mahoutによる機械学習の実際(1/3 ページ)
機械学習は古くからある情報処理のアルゴリズムの総称です。これをApache Hadoop上で実施する際のフレームワークの1つがApache Mahoutです。本稿ではApache Mahoutを使った機械学習の初歩を学んでいきます。
ビッグデータ活用:その分析実装として注目されるMahout
長年蓄積した企業内データや、ソーシャルネットワークサービス、センサ端末から集められる膨大なデータを活用し、企業における利益向上やコスト削減などに活用する動きが活発になってきました。
データの分析手段として最近とみに注目されている技術として「機械学習」があります。大規模データの処理を得意とする大規模分散処理基盤「Apache Hadoop」の強みを生かし、簡単に機械学習を行うためのライブラリが、「Apache Mahout」(以下、Mahout)です。
 Apach MahoutのWebサイト
Apach MahoutのWebサイト本稿ではMahoutを用いたデータ分析の例として「文書分類」を取り上げます。マシンを用いて分析実行する際の手順や陥りがちなポイント、チューニング方法の一例を紹介します。
Mahoutとは?
MahoutとはApache Software Foundationが公開しているOSSの機械学習ライブラリです。大きく分けて3つの機械学習分野(1)「レコメンデーション(Recomendation)」、(2)「クラスタリング(Clustering)」(3)「分類(Classification)」を中心に実装されています。
Mahoutは現在も活発に開発が続けられており、2013年7月25日にバージョン0.8が正式リリースされました。このリリースと同時に1.0版に向けたマイルストーンも発表されています。1.0版では商用利用されることを意識し、0.9〜1.0版ではバグのフィックスやメンテナンスが十分でない機能の削除などに注力するとの方向性がアナウンスされています。
文書分類とは
パソコンとインターネットの普及に伴い、メールやWebニュース、ブログやビジネス文書ファイルといった電子化された文書情報(テキスト)が多く存在するようになりました。これら文書情報から何らかの傾向や予測、判断材料など新たな知見を見いだすことを「テキストマイニング」といいます。
テキストマイニングにおいて、例えばニュース記事を幾つかのカテゴリに区分けしたり、受信メールがスパムメールか非スパムメールか判定したりと、文章をカテゴリに分けることを「文書分類」と呼びます。
分析する文書の量が膨大になってきた場合、例えば1台のマシンのメモリ内に収まらないサイズとなると、分析に使用できるツールは限られてきます。Mahoutは複数のマシンで並列処理するHadoopを基盤としており、データ量が膨大になる場合に強力な武器となります。
ナイーブ・ベイズとは
本稿では、文書分類を「ナイーブ・ベイズ(Naive Bayes)」というMahoutに実装された分類アルゴリズムを用いて行います。
はじめに、ナイーブ・ベイズの原理として使われるベイズ推定について説明します。ベイズ推定は条件付き確率を説明したベイズの定理を基にしています。ある文書DiがあるカテゴリCjである確率について、ベイズの定理を用いると
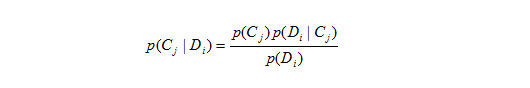
と表現できます。
この式を用いて、試験データDiに対して全てのカテゴリCj=1,...,nに属する確率を計算し、最も確率が高いカテゴリにDiを分類します。
確率の計算においては、各文書に出現する言葉1つずつを変数として利用します。文書Diに含まれる言葉について、仮にカテゴリCjに含まれる言葉をCj={yj1,yj2,.....,yjm}と定義した場合、
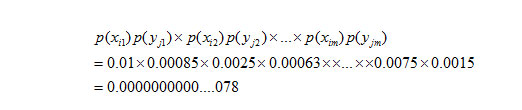
というように計算できます。
さらには、各言葉に対する重み付け、文書長やカテゴリ長に対する正規化、確率のアンダーフロー対策を行いますが、ここでは説明を省略します。
上の計算式では各言葉の出現確率が互いに独立であることを前提としています。この前提を適用することが疑わしい場合に、計算の便宜上この前提を適用することを「ナイーブ」といいます。
実行環境の準備
今回のテキスト分類では、オープンソースソフトとして利用できるMahout、Hadoop、MeCab、IPADICを使用します。それぞれのWebサイトからインストールパッケージをダウンロードし、環境に合わせた設定を行います。
本稿ではMahoutの最新バージョン0.8を使用しています。Mahoutをインストールしたディレクトリを「MAHOUT_HOME」として環境変数設定し、以降「$MAHOUT_HOME」で表現します。HadoopはMahoutの動作条件にてHadoop 0.20.0系としているため注意してください。Hadoopを環境に入れない場合は、実行ユーザーの環境変数に「MAHOUT_LOCAL」としてデータを配置するディレクトリ位置を設定することで、ローカルファイルシステムを使用して実行できます。
日本語テキストの分かち書きには形態素解析器「MeCab」を使用します。また、外部辞書が必要となるため日本語辞書「IPADIC」を使用します。
データの準備
本稿ではインターネット電子図書館「青空文庫」で公開されたテキストファイルをデータとして使用します。トップページから「分野別リスト」ページに行くと「0_総記」から「9_文学」まで10の分野に分かれており、そのリンク先にそれぞれ文書が格納されています。
ここから著作権のない文書(テキストファイル)を収集し、この分野別リストの通りに文書が分類されるか、確認していきます。
データのクレンジング
Webサイトから収集したファイルを「分野別リスト」のリンク構成通りに配置したら、実際のテキストファイルの中身を確認します。
青空文庫におけるテキストファイルでは、ヘッダ部としてタイトルや著者名、テキスト中に使用する記号に関する注釈を記載し、フッタ部として底本などの出典やテキストファイル作成に関する注釈を記載するという決まりがあります。また、本文中には何らかの記号を目印として、テキスト作成者による注記などが埋まっています。
以降で分類処理する上で入力データとして望ましくない部分は、ここでクレンジング(削除/変換)をする必要があります。本稿では全文書に対して一律に、ヘッダ部、フッタ部を削除し、入力者注としての記載([#○○○])やルビの記載(《○○○》)を削除しています。
実際の分析作業においても、本作業はとても重要で作業負荷の掛かる作業となります。以降に記す分析処理を実行しては結果の詳細を追跡し、このクレンジング作業に立ち返るという作業を繰り返すことになります。
日本語テキストの分かち書き
文章をナイーブ・ベイズで処理するためには、文章を単語に分割して処理する必要があります。英語文書などでは単語と単語の間に空白があるため、空白を利用して単語の抽出が行えます。日本語では単語の切れ目として空白を使わないため、何らかの手法で文章から単語を抽出することが必要となります。
今回はMeCabを用いて、日本語文章のテキストを「形態素(意味の最小単位)」の単位で単語ごとに空白で区切る手法を使います。これを「分かち書き」と呼びます。
ワークディレクトリ直下に「aozora」というディレクトリを作り、その配下に収集したデータを配置して、以下のように分かち書きを実行します。
for f in `find aozora -type f -print`
do
mecab -b 81920 -O wakati ${f} -o ${f}.wkt
rm -f ${f}
done
(例)分かち書き前のテキスト
学界というものをごく狭く理解して、研究室や研究所に直接関係がある世界のことだとすると、私は今日では全く学界の外の人である。
(例)分かち書き後のテキスト
学界 という もの を ごく 狭く 理解 し て 、 研究 室 や 研究所 に 直接 関係 が ある 世界 の こと だ と する と 、 私 は 今日 で は 全く 学界 の 外 の 人 で ある 。
ここまでで分析処理を実行する下準備ができました。次ページからは、Mahoutを実行して文書分類を行う流れを見ていきましょう。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。