増えるログ、多様化するログをどう効率的に運用するか:今さら聞けないfluentd〜クラウド時代のログ管理入門(1)(1/2 ページ)
仮想化やクラウド化、モバイル化の進展に伴い、管理すべきログが多様化・肥大化しています。そんな中でも効率よく、意味のあるログ管理を実現するツールとして注目されている「fluentd」を、これから始めたい方のために一から解説します。
システムを安定して効率良く運用していくために、ログ管理は欠かせない要素の1つです。仮想化やクラウド化、モバイル化の進展につれてシステムはますます大規模化し、それに伴い管理すべきログが多様化・肥大化する傾向にあります。
fluentdはこういった中でも、効率よく、意味のあるログ管理を実現するために非常に有用なツールです。本連載では、fluentdの基本と具体的な活用方法を紹介します。
ログ管理の現状と課題
環境の仮想化・クラウド化、さらには端末のモバイル化促進によりIT環境は大きく変化しました。これに伴い、顧客・ユーザー要求の面でも、低コストで迅速な対応を求めるようにニーズが変化しています。
こうした要因が、ログ管理の側面にも大きな影響を及ぼしています。具体的には、以下の2つです。
- ログの多様化・肥大化への対応
- ログ情報を基にした分析の必要性
1. ログの多様化・肥大化への対応
インフラ環境の仮想化やクラウド化が進むことで、ログの出力元は、これまでになく非常にドラスティックに変化するようになっています。
例えば、システムの稼働状況に応じてオートスケールする場合などが典型例です。オートスケールして管理対象の仮想マシンが増加すれば、その分、内部で発生するログも増えます。
さらに、サービスを利用するクライアント端末のモバイル化が進めば進むほどサービスの利用が活発になり、これまで以上に多くのトラフィックが発生する可能性があります。当然、トラフィック増加に伴い、ログ出力も増大します。
また、これまでは手元のサーバー内部のログファイルに出力されていた情報だけで済んだものが、パブリッククラウドサービスなどを利用すると、クラウドサービス提供者が管理している領域からも情報を収集しなければならない状況が起こり得ます。この場合、「ログファイルを開いて直接見る」というこれまでのやり方に代わり、クラウドAPIを経由して情報を収集するといった異なる方法を取らなければならないことも少なくありません。
このように、大量のログをさまざまな方法で管理しなければならない状況が増えてきています。
2. ログ情報を基にした分析の必要性
前述の通りログが大量に出力されるようになると、ただ単に「ログを保存しておき、何か発生したら後で確認する」といった管理方法では対応が難しくなります。膨大なログの中から「意味のある情報を抽出する」ことが重要となります。
さらには、ただ抽出するだけでなく、ログに出力される内容を基に傾向などを分析し、潜在的な事象を導き出すことも重要になります。
例えば、サービスへのアクセス状況をログから分析してオートスケールの自動実行に連動させたり、アプリケーション開発における方針決定に反映するなど、次のアクションにつなげることのできる、意味のある情報の抽出や分析が非常に重要な要素となります。
これまでのログ管理手法の限界
これまでのログ管理のやり方を振り返ってみましょう。OSやミドルウェア、アプリケーションなどが生成するログはファイルに出力し、そのログファイルをlogrotateなどの機能を使って世代管理したり、バックアップや集約管理という観点からrsyslogなどを使って別サーバーに転送して管理する、といった形で運用するケースが多かったのではないでしょうか。
これにちょっとした応用を加え、監視ツールを導入し、「ログの中に特定の文字列が出力されたら検知し、アクションを起こす」という形で、ログ監視を安定運用に活用している方も多いのではないでしょうか。
しかし、前述の通り環境が激変する中、より柔軟で効率のよいログ管理が求められる状況においては、これまでの管理手法では難しい点が多々生じます。
そこで、ログ収集をプログラマブルに実施し、状況に応じた柔軟な対応が実現できるfluentdのようなソフトウェアが注目されているのです。
軽量でプラガブル……fluentdの特徴とは
fluentdはトレジャーデータの開発者およびコミュニティベースで開発が進められている、Rubyで実装された軽量でプラガブルなログ収集ツールです。オープンソース(ライセンス:Apache License Version 2.0)として公開されています。
各マシンにインストールしたfluentdのエージェントがログの収集や加工、分析処理などを行い、エージェント同士が互いに連携してログ管理を実現します。第3回でも紹介するように、既にいろいろなサービスで活用され始めています。
2013年12月時点での最新バージョンは0.10.41で、本連載はこの0.10.41をベースに解説します。
【関連記事】
グリー技術者が聞いた、fluentdの新機能とTreasure Data古橋氏の野心
http://www.atmarkit.co.jp/ait/articles/1310/07/news010.html
大人気のログ収集ツールfluentdとは? そして、トレジャーデータやクックパッド、NHN Japanはどう使っているのか?
https://event.atmarkit.co.jp/events/d327924f8d5657b70d3bebe5debfb6ff/atmarkit_report
fluentdのアーキテクチャ
fluentdの使い方に触れる前に、fluentdがどういったアーキテクチャでログ管理を実現しているのかを紹介しておきましょう。
fluentdの最も特徴的なところは、ログの管理を「インプット」「バッファ」「アウトプット」という3つの層に分けて管理する点です。さらに、各層がプラガブルなアーキテクチャを取っており、用途に応じてプラグインを追加するだけで使える仕組みになっています。
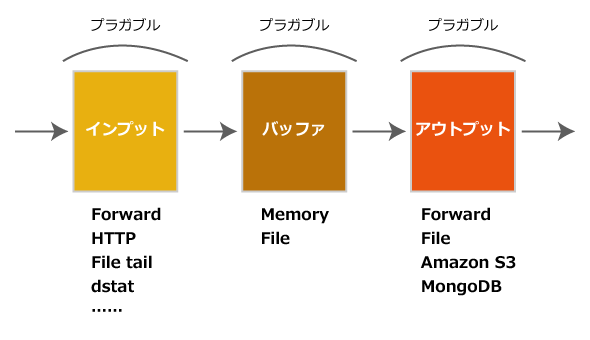 図1 fluentdのinput/buffer/outputプラグインの構造(引用元:http://www.qcontokyo.com/data_2013/MugaNishizawa_QConTokyo2013.pdf)
図1 fluentdのinput/buffer/outputプラグインの構造(引用元:http://www.qcontokyo.com/data_2013/MugaNishizawa_QConTokyo2013.pdf)また、fluentdは内部で各ログデータに対して「タグ」を付与し、管理しています。このタグベースで処理の振り分けなどを行うため、fluentdでログデータを扱う際には、このタグの管理が重要な要素になります。
fluentd内部におけるデータの流れの概略図は、以下の通りです。
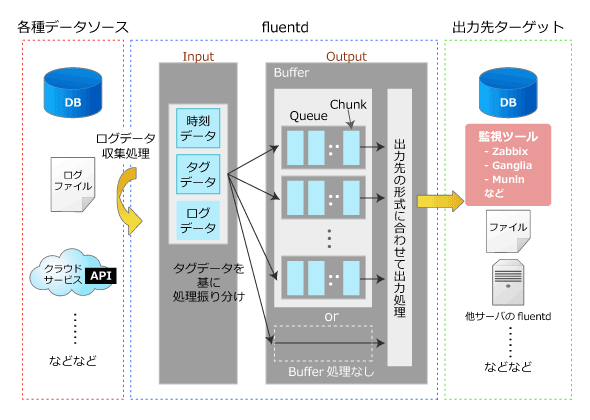 図2 fluentd内部のデータフロー
図2 fluentd内部のデータフローCopyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。