ヒープに対する攻撃とその対策:Beyond Zero-day Attacks(3)(1/3 ページ)
攻撃手法を技術的に理解するための連載、今回はスタックと並んでよく耳にする「ヒープ破壊」を取り上げます。
前回取り上げたスタックオーバーフローは比較的理解しやすい攻撃手法なのですが、今回取り上げるヒープオーバーフローは少々分かりにくい面があります。恥ずかしながら、筆者自身、これまでなかなか理解ができていなかったのが実情です。スタック管理と比較すると、ヒープ管理はとても複雑で、解説が難しいのですが、ここではできるだけ単純化し、ポイントとなる点をご紹介していきます。
ヒープメモリとは
スタックとヒープは、どちらもプログラムに動的なメモリ領域を提供するための仕組みです。スタックは関数の呼び出しなど、プログラムの制御に伴って利用されるもので、コンパイルの結果としてスタック操作が組み込まれるため、プログラマーが意識することは少ないと思います。
これに対してヒープは、プログラム中でmalloc()などを呼び出すことで確保され、free()を使って解放されます。プログラマーが明示的に、この操作を行う場合に加えて、使用するライブラリやクラスの中から、間接的に(プログラマーが意識せずに)、この操作が行われます。
例えば、C言語のprintfでは、出力する文字列を生成するためにヒープが利用され、C++やJavaScriptで新しいオブジェクトを作る際にもヒープ上にオブジェクトが生成されます。
スタックは後入れ先出しで順番通りに取得、解放されますが、ヒープは取得した順番とは無関係に、プログラムの動きによって取得、解放が行われます。このためメモリを効率的に管理しないと、使用済みの領域が再割り当てされずに、大量のメモリ領域を消費してしまいます。一方で、ヒープ領域は頻繁に取得、解放が行われるため、オーバーヘッドが大きいと、プログラムの動作速度に深刻な影響を与えてしまいます。
ヒープ管理は、割り当てるメモリ領域のブロック数やサイズが頻繁に変わる特性を、効率的かつ柔軟に実装するために、リンク構造が利用されることが一般的です。単方向リンクで管理される場合もありますが、多くの場合、図1のように双方向リンクで管理されます。
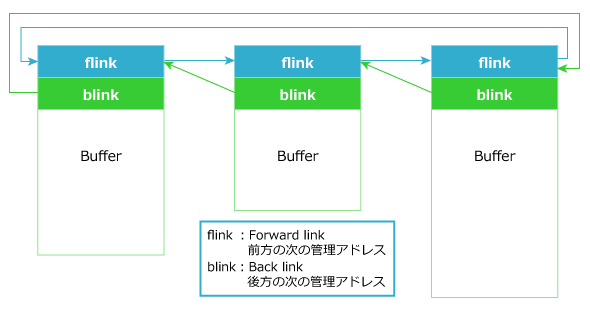 図1 ヒープの構造
図1 ヒープの構造図1はリンク構造の模式図なので、各ヒープ領域は独立したメモリ領域のように見えますが、実際には図2のように連続したメモリ領域を、論理的に区切って使用します。このため、アプリケーションに割り当てたヒープ領域を超えて書き込みが行われると、ヒープ管理情報(flink、blink等)を上書きしてしまいます。
スタック破壊でもgets()が出てきましたが、例えばgets()のパラメーターにヒープ領域を指定した場合、ヒープオーバーフローでヒープ管理情報を上書きすることが可能です。
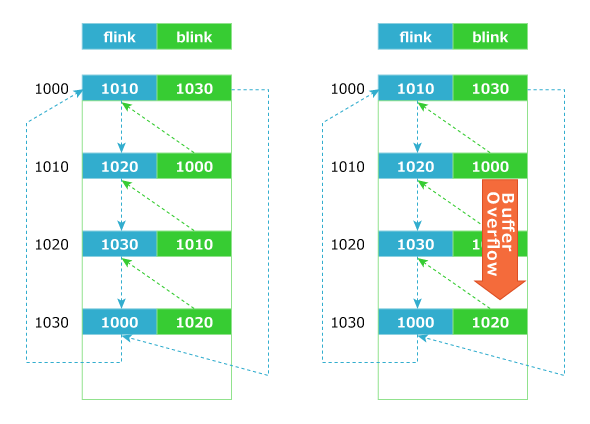 図2 ヒープのメモリ上での展開イメージ
図2 ヒープのメモリ上での展開イメージヒープの解放とヒープオーバーフロー
スタックオーバーフローでは、スタック上のEIPを書き換えることで、任意のアドレスに制御を移しましたが、ヒープオーバーフローでは直接的にプログラムの制御を操作せず、ヒープ管理の特性を悪用し、任意のアドレスに任意の4バイトを書き込むという動作を行います。
双方向リンクで管理されているヒープ領域を追加、解放した場合、flink、blinkの操作が行われ、ヒープの連結が保たれます。任意のアドレスへの任意の4バイトの書き込みは、この動作を悪用します(図3)。そして、図3を連続したメモリに展開したものが図4です。
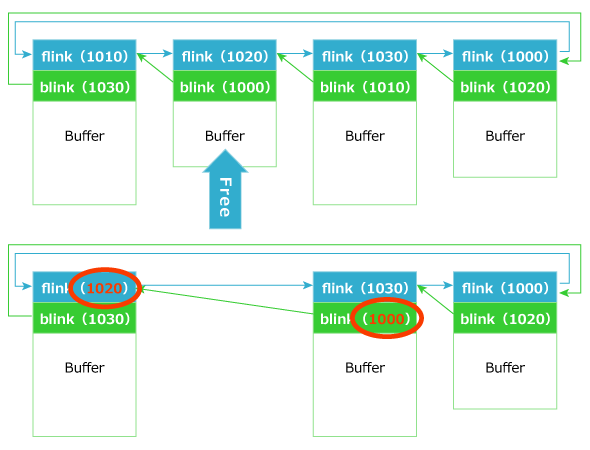 図3 ヒープ領域の解放(リンク構造としてのイメージ)
図3 ヒープ領域の解放(リンク構造としてのイメージ)例えば1010として割り当てられたヒープ領域を解放すると、1010のflinkに当たる1020のblink(1010)に、1010のflink(1000)が書き込まれます。そして、1010のblink(1000)のflink(1010)に、1010のblink(1020)が書きこまれ、リンク構造が維持されます。
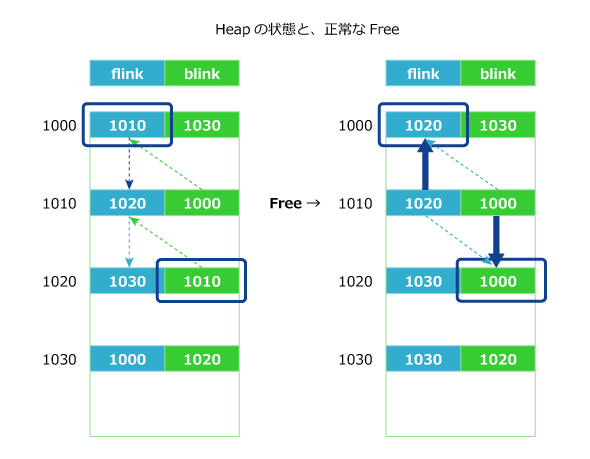 図4 ヒープ領域の解放(連続したメモリー上でのイメージ)
図4 ヒープ領域の解放(連続したメモリー上でのイメージ)図5では、ヒープオーバーフローにより、1010のflinkに2000、blinkに4141を書き込んでいます。この状態で、1010を開放すると、2000番地に4141が、4141番地に2000が書き込まれます。
この際に、どちらかのアドレスが書きこみ不可の領域の場合、アクセスバイオレーションでプログラムが異常終了するなど、ヒープオーバーフローは限定的な条件でしか成立しないため、脆弱性があっても、安定してこれを悪用することは難しい脆弱性といえます。
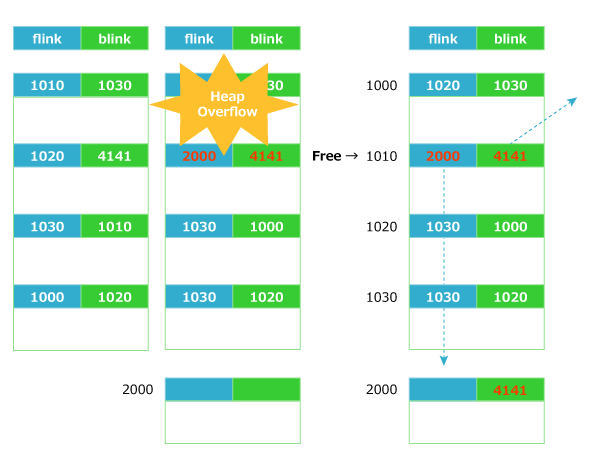 図5 ヒープオーバーフロー
図5 ヒープオーバーフローまた、一般に4バイトを書き換えただけでは、実行したい攻撃コード(Shell Code)に実行アドレスを遷移できません。攻撃を成功させるためには、実行アドレスをシェルコードに遷移させる必要があります。
ヒープオーバーフローを使って実行アドレスを遷移させるためには、例えば、C++のVirtual Tableなどの何らかの関数のアドレスが格納されたメモリ領域を、シェルコードのアドレスに書き換えることで実現します。また、下記の資料「Windows Heap Exploitation(Win2KSP0 through WinXPSP2)」では、アクセス違反の際に、ExitProcess()が、PEB lockルーチンを呼び出すことを利用する手法が紹介されています。
関連リンク
Windows Heap Exploitation(Win2KSP0 through WinXPSP2)
Matt Conover & Oded Horovitz
http://www.cybertech.net/~sh0ksh0k/projects/winheap/XPSP2%20Heap%20Exploitation.ppt
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。