OCR(光学文字認識)機能を実装するには?[ユニバーサルWindowsアプリ開発]:WinRT/Metro TIPS
「Microsoft OCR Library for Windows Runtime」を使って、ユニバーサルアプリにOCR機能を実装する方法を解説する。

powered by Insider.NET
アプリの中でOCR(光学文字認識)機能を使いたいと思ったことはないだろうか? 例えば、名刺を読み取って電話番号やメールアドレスなどをデータベースに登録したい、あるいは、商品コードを読み取って検索したいといったような場合だ。そのようなことが、マイクロソフトから提供された「Microsoft OCR Library for Windows Runtime」のOcrEngineで可能になった。
本稿では、OcrEngineを利用する実装方法を解説する。なお、本稿のサンプルは「Windows Store app samples:MetroTips #91」からダウンロードできる。
事前準備
ユニバーサルプロジェクトを使ってユニバーサルWindowsアプリを開発するには、以下の開発環境が必要である。本稿では、無償のVisual Studio Express 2013 for Windowsを使っている。
- SLAT対応のPC*1
- 2014年4月のアップデート*2適用済みの64bit版Windows 8.1 Pro版以上*3
- Visual Studio 2013 Update 2(またはそれ以降)*4を適用済みのVisual Studio 2013(以降、VS 2013)*5
*1 SLAT対応ハードウェアは、Windows Phone 8.1エミュレーターの実行に必要だ。ただし未対応でも、ソースコードのビルドと実機でのデバッグは可能だ。SLAT対応のチェック方法はMSDNブログの「Windows Phone SDK 8.0 ダウンロードポイント と Second Level Address Translation (SLAT) 対応PCかどうかを判定する方法」を参照。なお、SLAT対応ハードウェアであっても、VM上ではエミュレーターが動作しないことがあるのでご注意願いたい。
*2 事前には「Windows 8.1 Update 1」と呼ばれていたアップデート。スタート画面の右上に検索ボタンが(環境によっては電源ボタンも)表示されるようになるので、適用済みかどうかは簡単に見分けられる。ちなみに公式呼称は「the Windows RT 8.1, Windows 8.1, and Windows Server 2012 R2 update that is dated April, 2014」というようである。
*3 Windows Phone 8.1エミュレーターを使用しないのであれば、32bit版のWindows 8.1でもよい。
*4 マイクロソフトのダウンロードページから誰でも入手できる(このURLはUpdate 3のもの)。
*5 本稿に掲載したコードを試すだけなら、無償のExpressエディションで構わない。Visual Studio Express 2013 with Update 3 for Windows(製品版)はマイクロソフトのページから無償で入手できる。Expressエディションはターゲットプラットフォームごとに製品が分かれていて紛らわしいが、Windowsストアアプリの開発には「for Windows」を使う(「for Windows Desktop」はデスクトップで動作するアプリ用)。
用語
本稿では、紛らわしくない限り次の略称を用いる。
- Windows:Windows 8.1とWindows RT 8.1(2014年4月のアップデートを適用済みのもの)
- Phone:Windows Phone 8.1
サンプルコードについて
Visual Studio 2013 Update 2(およびUpdate 3)では、残念なことにVB用のユニバーサルプロジェクトのテンプレートは含まれていない*6。そのため、本稿で紹介するコードはC#のユニバーサルプロジェクトだけとさせていただく*7。
*6 VB用のユニバーサルプロジェクトは、来年にリリースされるといわれているVisual Studio「14」からの提供となるようだ。「Visual Studio UserVoice」(英語)のリクエストに対する、6月18日付けの「Visual Studio team (Product Team, Microsoft)」からの回答による。
*7 Visual Studio 2013 Update 2(またはUpdate 3)のVBでユニバーサルWindowsアプリを作る場合のお勧めは、「The Visual Basic Team」のブログ記事(英語)によれば、PCLを使う方法だ。しかし、本稿で利用するOcrEngineは、PCLからは利用できないようである(PCLは「Any CPU」としてビルドできないと意味が無いが、現在のOcrEngineはCPU依存のライブラリである)。
OcrEngineをプロジェクトに導入するには?
「Microsoft OCR Library for Windows Runtime」は、ユニバーサルWindowsアプリのSDKにはまだ含まれておらず、NuGetから別途導入する*8。
VS 2013のソリューションエクスプローラーから、以下の画像のような手順でOcrEngineをプロジェクトに導入する。また、OcrEngineはCPUに依存するライブラリであるため、ソリューション構成を[x86]に変更しておく(リリース時は、対象とするCPUごとのバイナリを含んだパッケージバンドルにする*9)。
*8 「Building Apps for Windows」ブログの記事「Microsoft OCR Library for Windows Runtime」(英語)によれば、商利用にもライセンス料は不要とのことである。
*9 ストアにアップロードするパッケージを作る際に、[パッケージの選択と構成]ダイアログの[作成するパッケージとソリューション構成マッピングを選択する]欄で、[Neutral](=Any CPU)のチェックは外し、それ以外の対象とするCPUにチェックを入れる。
 OcrEngineをプロジェクトに導入する(その1)
OcrEngineをプロジェクトに導入する(その1)VS 2013のソリューションエクスプローラーで、ソリューションを右クリックし、そのメニューから[ソリューションの NuGet パッケージの管理](赤丸内)を選ぶ。
すると、[NuGet パッケージの管理]ダイアログが表示されるので、ここでインストールを行う。
 OcrEngineをプロジェクトに導入する(その2)
OcrEngineをプロジェクトに導入する(その2)[NuGet パッケージの管理]ダイアログが出てくるので、左側で[オンライン]を選び((1))、右上の検索ボックスに「Microsoft OCR」と入力して検索する((2))。中央部分に検索結果が出てくるので、その中から[Microsoft OCR Library for Windows Runtime]を選び((3))、[インストール]ボタンをクリックする((4))。
その後、[プロジェクトの選択]ダイアログが表示されたら、インストール対象のプロジェクトを指定する。
 OcrEngineをプロジェクトに導入する(その3)
OcrEngineをプロジェクトに導入する(その3)[プロジェクトの選択]ダイアログが出てくるので、導入したいプロジェクトにチェックを入れて、[OK]ボタンをクリックする。これでインストールが実行される。
C#のユニバーサルプロジェクトの共有プロジェクトでOcrEngineを利用する場合は、Windows用とPhone用の2つのプロジェクトを選択する。
なお、後から導入プロジェクトを変更するには、ソリューションの右クリックから開いた[NuGet パッケージの管理]ダイアログ(=前の画像)の左側で[インストール済みのパッケージ]を選んで行う。
OcrEngineのインストールが終わったら、ソリューション構成を調整する。


 OcrEngineをプロジェクトに導入する(その4)
OcrEngineをプロジェクトに導入する(その4)OcrEngineはCPU依存のライブラリであるため、ソリューション構成を適切に変更する。
上:デバッグなどでPhoneのテストをエミュレーターで行うなら、ドロップダウンで[x86]を選べばよい(赤丸内)。
中:リリース前のテストなどでPhoneの実機を使って実行するときは、ドロップダウンで[構成マネージャー]を選び(上の図の赤枠内)、出てきた[構成マネージャー]ダイアログの[アクティブ ソリューション プラットフォーム]で[<新規作成...>]を選ぶ(画像はこの時点のもの)。すると[新しいソリューション プラットフォーム]ダイアログが出てくるので、新しいプラットフォームの名前として例えば「Mixed」と入力し、設定のコピー元として[x86]を選び、[OK]ボタンをクリックして[構成マネージャー]に戻る(続く)。
下:(続き)[構成マネージャー]の[アクティブ ソリューション プラットフォーム]で、今しがた作成した[Mixed]を選び、Phone用プロジェクトの[プラットフォーム]を[ARM]に変更する(赤枠内)。これで、Windows用のプロジェクトはx86用にビルドされ、Phone用のプロジェクトはARM用にビルドされるようになる。次からはドロップダウンで[Mixed]を選ぶだけでよい。なお、このときは、画像の左に見えるように、XAMLのデザインビューが働かなくなる。
OcrEngineが認識できる言語を設定するには?
以上のようにしてOcrEngineを導入した場合、認識できる言語は英語だけである。他の言語も認識させたい場合は、以下の手順で設定ファイルを再生成する。
まず、ソリューションのあるフォルダーをエクスプローラーで開き、そこから次に示すフォルダーを開く。
- {ソリューションのあるフォルダー}\packages\Microsoft.Windows.Ocr.1.0.0\OcrResourcesGenerator
この「OcrResourcesGenerator」フォルダーに「OcrResourcesGenerator.exe」ファイルがあるので、それを実行する。出てきたダイアログで、認識させたい言語を右のリストに移し、[Generate Resources]ボタンをクリックする(次の画像)。保存先を尋ねられるので、OcrEngineを導入したプロジェクトのフォルダーの下にある[OcrResources]フォルダーを選び、「MsOcrRes.orp」ファイルを上書きする(複数のプロジェクトで使う場合は、ここで上書きしたファイルを他のプロジェクトにコピーすればよい)。
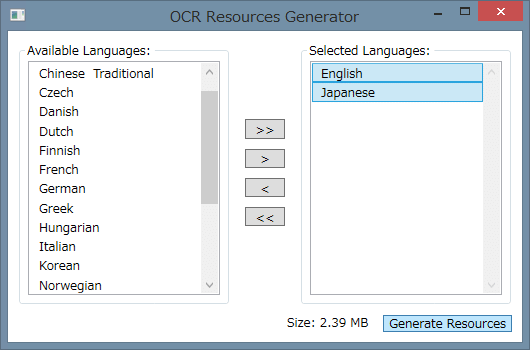 「MsOcrRes.orp」ファイルを生成するプログラム
「MsOcrRes.orp」ファイルを生成するプログラム左のリストで認識させたい言語を選び、中央のボタンを操作して右のリストに移す。ここでは、英語と日本語を選択している。
[Generate Resources]ボタンで、新しい「MsOcrRes.orp」ファイルを生成できる。
以下のサンプルコードでは、上の画像のようにして英語と日本語を設定した「MsOcrRes.orp」ファイルを使用している。デフォルト(=英語のみ)のままでは、日本語として認識させようとするとエラーになるので注意してほしい。
OcrEngineで画像から文字列を読み取るには?
OcrEngineのRecognizeAsyncメソッドに画像データを渡せばよい。ただし、読み取れる画像のサイズは、最小40×40ピクセルから最大2600×2600ピクセルまでである。
RecognizeAsyncメソッドの引数は、次のようになっている。
- 第1引数:画像の高さ(ピクセル数)
- 第2引数:画像の幅(ピクセル数)
- 第3引数:画像データのbyte配列(BGRAピクセルフォーマット)
これら3つの値を得るには、画像データをWriteableBitmapクラス(Windows.UI.Xaml.Media.Imaging名前空間)のオブジェクトとして保持しておけば簡単になる(利用法は後述のコードを参照)。例えば、画像ファイルを読み込んでWriteableBitmapオブジェクトを作るには、次のコードのようにする。
private async System.Threading.Tasks.Task<Windows.UI.Xaml.Media.Imaging.WriteableBitmap>
LoadImageAsync(Windows.Storage.StorageFile file)
{
// 画像ファイルからImagePropertiesを得る。画像の高さと幅が分かる
Windows.Storage.FileProperties.ImageProperties imgProp = await file.Properties.GetImagePropertiesAsync();
// 画像ファイルを開き、WriteableBitmapを生成して返す
using (var imgStream = await file.OpenAsync(Windows.Storage.FileAccessMode.Read))
{
var bitmap = new Windows.UI.Xaml.Media.Imaging.WriteableBitmap((int)imgProp.Width, (int)imgProp.Height);
bitmap.SetSource(imgStream);
return bitmap;
}
}
RecognizeAsyncメソッドの返値はOcrResultクラス(WindowsPreview.Media.Ocr名前空間)のオブジェクトであり、以下のような情報が入っている。
- Linesプロパティ:OcrLineオブジェクト(WindowsPreview.Media.Ocr名前空間)のリスト
- TextAngleプロパティ:読み取った文字列の水平(縦書きの場合は垂直)からの回転角度
また、OcrLineオブジェクトには、以下のような情報が入っている。
- IsVerticalプロパティ:縦書きのときTrue(日本語など一部の言語のみで有効)
- Wordsプロパティ:OcrWordオブジェクト(WindowsPreview.Media.Ocr名前空間)のリスト
そして、OcrWordオブジェクトには、以下のような情報が入っている。
- Textプロパティ:単語として認識した文字列(英語などの場合)か、個別に認識した1文字(日本語などの場合)
- Left/Top/Width/Heightプロパティ:OcrWordオブジェクトとして認識した領域(ただし、TextAngleプロパティの分だけ回転している)*10
*10 本稿では扱わないが、これらのプロパティ(OcrResultオブジェクトのTextAngleプロパティとOcrWordオブジェクトのLeft/Top/Width/Heightプロパティ)を利用すれば、文字として認識した領域を画像の上に表示できる。
WriteableBitmapオブジェクトを渡して文字列を認識させ、その結果をテキストボックスに表示するメソッドは、次のように書ける。
private async System.Threading.Tasks.Task
ExtractTextAsync(Windows.UI.Xaml.Media.Imaging.WriteableBitmap bitmap,
WindowsPreview.Media.Ocr.OcrLanguage language)
{
// OcrEngineオブジェクトを生成する
var ocrEngine = new WindowsPreview.Media.Ocr.OcrEngine(language);
// OcrEngineに画像を渡して、文字列を認識させる
var ocrResult = await ocrEngine.RecognizeAsync(
(uint)bitmap.PixelHeight, // 画像の高さ
(uint)bitmap.PixelWidth, // 画像の幅
bitmap.PixelBuffer.ToArray() // 画像のデータ(byte配列)
);
if (ocrResult.Lines == null || ocrResult.Lines.Count == 0)
{
this.ReadText.Text = "(何も読み取れませんでした)";
return;
}
// この時点で、読み取りは終わっている。以降は、読み取り結果を表示するためのコードである
// Word間の区切り(日本語では無し、英語ではスペースとする)
var separater = string.Empty;
if (language == WindowsPreview.Media.Ocr.OcrLanguage.English)
separater = " ";
// 結果を表示するテキストボックスをクリアする
this.ReadText.Text = string.Empty;
// 行番号(0始まり)を定義
int lineIndex = 0;
// 認識結果を行ごとに処理する
foreach (var line in ocrResult.Lines)
{
// 1行分の文字列を格納するためのバッファー
var sb = new System.Text.StringBuilder();
// 認識結果の行を、Wordごとに処理する
foreach (var word in line.Words)
{
// 認識した文字列をバッファーに追加していく
sb.Append(word.Text);
sb.Append(separater);
}
// ここでは、読み取った1行を以下のフォーマットで表示することにした
this.ReadText.Text += string.Format("[{0}{1}] {2}{3}",
(lineIndex++).ToString(), // 行番号(0始まり)
line.IsVertical ? "V" : "H", // 縦書き/横書きの区別
sb.ToString().TrimEnd(), // 読み取った文字列
Environment.NewLine // 改行
);
}
}
このメソッドの第2引数には、OcrLanguageオブジェクト(WindowsPreview.Media.Ocr名前空間)を与える。それによって、どの言語として認識するのかが決まる(認識結果が変わる)。
長いコードであるが、その大半は読み取った結果を表示するためのコードだ。
実行結果
C#の共有プロジェクトにユーザーコントロールを置き、そこにImageコントロール(Windows.UI.Xaml.Controls名前空間)やTextBoxコントロール(Windows.UI.Xaml.Controls名前空間)などを配置した。起動したときにサンプル画像を読み込んでImageコントロールに表示する。また、ボタンをいくつか配置し、それをタップしたときに画像から文字列を認識させ、その結果をTextBoxコントロール(上記コードではこれを「this.ReadText」として参照している)に表示するようにした。詳細は、別途公開のサンプルコードをご覧いただきたい。
まず気になるのは、日本語をどのくらい認識できるかだろう。縦書き文章の画像を読ませてみると、次の画像のようになった。なかなかの結果だといえる。
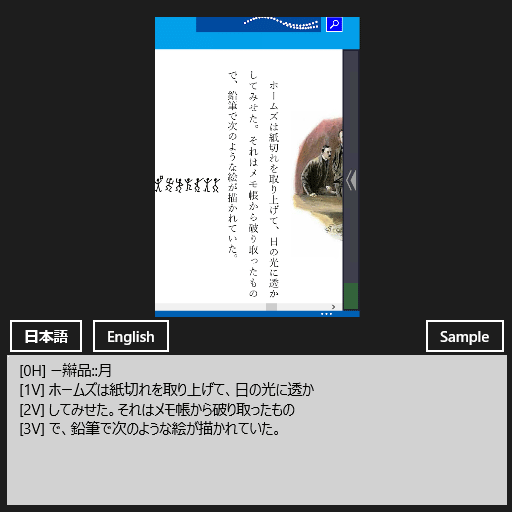 縦書きの日本語文章を認識させた例(画面の一部)
縦書きの日本語文章を認識させた例(画面の一部)ドキュメント:「踊る人形」(青空文庫)アプリ:青空文庫リーダー・ライト認識結果の行頭に付けてある記号は、行番号(0始まり)と縦書き/横書きの区別(H:横書き、V:縦書き)である。
文字ではない図形(上端にあるロゴとボタン)も日本語として読み取ろうとしているのが分かる(先頭行)。
英語の認識結果は次の画像のようだ。

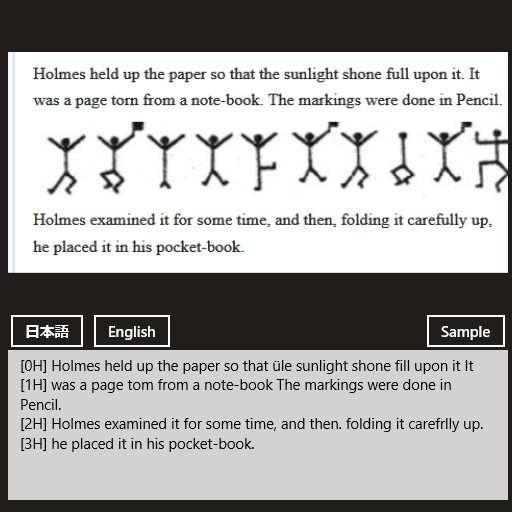 英語の文章を認識させた例(画面の一部、上:日本語として認識、下:英語として認識)
英語の文章を認識させた例(画面の一部、上:日本語として認識、下:英語として認識)ドキュメント:「The Adventure of the Dancing Men」(Wikisource)アプリ:Internet Explorer
日本語として認識させた場合(上)は、1行全体が1つのOcrWordに入ってしまう(デバッグ実行中にブレークさせて確認した)。カンマやピリオドも正しく認識できていない。
英語として認識させた場合(下)は、単語ごとにきちんとOcrWordに入ってくる。
このように、正しい言語を指定することが大切である。
印刷物をカメラで撮影した画像では認識精度が落ちるようだが、商品コードなどの英数字の認識は十分にできる(次の画像)。
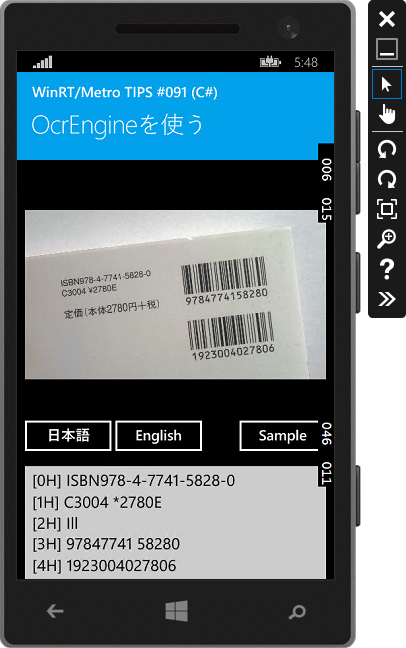 印刷物を撮影した画像を認識させた例(Windows Phone 8.1エミュレーター)
印刷物を撮影した画像を認識させた例(Windows Phone 8.1エミュレーター)本の裏表紙の一部をわざと斜めに撮影して、その画像を認識させてみた(筆者の著書)。
ここでは英語として認識させているため、「¥」記号と、「定価〜」で始まる行とが読み取れていない。
まとめ
Microsoft OCR Library for Windows Runtimeを利用することで、簡単にOCR機能を実装できる。認識させる言語の指定が正しくできれば、認識精度はかなりよい。このOCR機能については、次のドキュメントも参照してほしい。
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。