Html Agility Packを使ってWebページをスクレイピングするには?[C#、VB]:.NET TIPS
Html Agility Pack/XPath/LINQを組み合わせて、Webページから特定の情報を簡潔な形で抜き出す方法を解説する。

対象:.NET 2.0以降(ただしVisual Studioは2010以降)
Webページの内容をどのようにして解析すればよいだろうか? 例えば、記事の一覧が掲載されているWebページの内容を取得してきて、そこから記事のタイトルとURLだけを全て取り出したいといった場合だ。正規表現(System.Text.RegularExpressions名前空間のRegexクラス)を使えば可能ではあるが、かなり面倒である。WebページがXHTMLで記述されているならXDocumentクラス(System.Xml.Linq名前空間)で楽に解析できるはずなのだが、しかし現実のWebページにはXHTMLであると宣言してあってもXMLとしては不完全な記述のものが少なくない(=XDocumentクラスで解析できない)。そこで本稿では、オープンソースのライブラリ「Html Agility Pack」を使ってWebページを解析する方法を解説する。
事前準備
本稿では、文字コードがシフトJISエンコーディングになっているWebページを取得して解析する。取得の方法については、次のTIPSを参照してほしい。
以降で示すサンプルコードでは、Webページを取得する部分は省略している。WebページのURLを与えてそのページの内容を文字列として取得する部分は、上記のTIPSを参考にして実装していただきたい。
なお、上記TIPSのコードを前提としているため、以降で示すサンプルコードは.NET Framework 4.5以降(Visual Studio 2012/2013)用のものとなっている。それ以前のバージョンでコーディングする場合は、適宜修正してもらいたい。
また、Html Agility PackはNuGetを使ってインストールする。Visual Studio 2012以降では、NuGetが標準で使えるようになっているので、何もしなくてよい。Visual Studio 2010(Expressエディションを除く)では、NuGet Package Managerをインストールしておいてほしい。
Html Agility Packを導入するには?
Html Agility Packは、プロジェクトごとにNuGetから導入する。以下、Visual Studio 2012(無償のExpressエディション)の場合で説明する。まず、ソリューションエクスプローラーで導入したいプロジェクトを選択しておいて、メニューバーから[プロジェクト]−[NuGet パッケージの管理]を選ぶ(次の画像)。
![[NuGetパッケージの管理]ダイアログを開く(Visual Studio 2012)](https://image.itmedia.co.jp/l/im/ait/articles/1501/27/l_dt-01.gif) [NuGetパッケージの管理]ダイアログを開く(Visual Studio 2012)
[NuGetパッケージの管理]ダイアログを開く(Visual Studio 2012)Html Agility Packを利用したいプロジェクトをソリューションエクスプローラーで選択し((1))、メニューバーから[プロジェクト]((2))−[NuGet パッケージの管理]((3))を選ぶと、次の画像の[NuGet パッケージの管理]ダイアログが表示される。
すると、[NuGet パッケージの管理]ダイアログが表示されるので、左側のペーンで[オンライン]を選択してから、右上の検索ボックスに「HtmlAgilityPack」(空白なし)と入力して[Enter]キーを押す。すると次の画像のようにいくつかのパッケージが表示されるので、その中から[HtmlAgilityPack]を選び、そこに表示された[インストール]ボタンをクリックする(次の画像)。
![[HtmlAgilityPack]を選んでインストールする(Visual Studio 2012)](https://image.itmedia.co.jp/l/im/ait/articles/1501/27/l_dt-02.gif) [HtmlAgilityPack]を選んでインストールする(Visual Studio 2012)
[HtmlAgilityPack]を選んでインストールする(Visual Studio 2012)[NuGet パッケージの管理]ダイアログの左側のペーンで[オンライン]を選択し((1))、検索ボックスに「HtmlAgilityPack」(空白なし)と入力して[Enter]キーを押す((2))。検索結果が中央部分に表示されるのでその中から[HtmlAgilityPack]を選択し((3))、表示された[インストール]ボタン((4))をクリックすると、Html Agility Packのインストールが始まる。
インストールに成功すると、[インストール]ボタンが消え、その場所に緑色のチェックマークが出る。そうしたら右下の[閉じる]ボタンでダイアログを閉じて、作業完了だ(次の画像)。
 Html Agility Packのインストール完了(Visual Studio 2012)
Html Agility Packのインストール完了(Visual Studio 2012)インストールが完了すると、[インストール]ボタンが緑色のチェックマークに変わる((1))。[閉じる]ボタン((2))でダイアログを閉じて、作業完了だ。
Html Agility Packを導入した後でソリューションエクスプローラーを見ると、次の画像のようになっている(次の画像、全てのファイルを表示させている)。自動的に参照設定が追加され、また、NuGetパッケージ管理用の「packages.config」ファイルが作成されている。
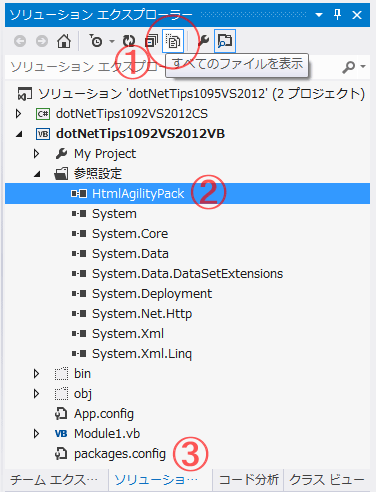 Html Agility Pack導入後のソリューションエクスプローラー(Visual Studio 2012)
Html Agility Pack導入後のソリューションエクスプローラー(Visual Studio 2012)VBのプロジェクトは既定では参照設定が表示されないので、ソリューションエクスプローラー上部の[すべてのファイルを表示]アイコン((1))をクリックして表示させる(C#のプロジェクトでは参照設定は常に表示されている)。参照設定に[HtmlAgilityPack]が追加されている((2))。また、NuGetパッケージ管理用の「packages.config」ファイルが作成されている((3))。
Html Agility Packを使ってWebページを解析するには?
処理の流れとしては、Webページの内容を取得し、それをHtml Agility PackのHtmlDocumentオブジェクト(HtmlAgilityPack名前空間)に読み込ませてから、XPath(XML Path Language)やLINQを使って解析することになる。HtmlDocumentオブジェクトを構築する方法は何種類か用意されており、ここでは文字列を渡す方法を使うことにする。
サンプルとして、次のWebページを使う(次の画像)。このWebページの内容を解析して、掲載されている記事のタイトル(1000件ちょっとある)とそのURLを抜き出してみよう。
 サンプルに使うWebページ(Internet Explorer)
サンプルに使うWebページ(Internet Explorer)この.NET TIPSの日付順インデックスのページである。記事へのリンクが1000件ちょっと掲載されている(最初の1件を赤枠で示す)。Html Agility Packを使って解析し、この記事タイトルとリンクURLを取り出してみよう。
上の画像で赤枠を付けたあたりのソースコードは、次のようになっている。目的の情報を得るには、「da-tips-index-target」というclass属性を持った<div>要素の中にあるclass属性を持たない<div>要素を探し、その中の<a>要素を取り出せばよさそうである。
<div class="da-tips-section"><a name="2015" id="2015"></a>2015年</div>
<div class="da-tips-index-target">
<div class="da-tips-target-title"><a name="20150113" id="20150113"></a>2015/01/13</div>
<div> - <a href="http://www.atmarkit.co.jp/ait/articles/1501/13/news142.html">HttpClientクラスでシフトJISのWebページを取得するには?[C#、VB]</a></div>
<div class="da-tips-target-title"><a name="20150106" id="20150106"></a>2015/01/06</div>
<div> - <a href="http://www.atmarkit.co.jp/ait/articles/1501/06/news086.html">HttpClientクラスでWebページを取得するには?[C#、VB]</a></div>
<div class="da-tips-backindex"><a href="#index">【インデックス一覧に戻る】 </a></div>
</div>
「da-tips-index-target」というclass属性を持った<div>要素の中にあるclass属性を持たない<div>要素の中の<a>要素に、記事のタイトルとURLが含まれている(太字の部分が最初の1件のもの)。 掲載年ごとに別の<div>要素になっており、また、日付の<div>要素と記事タイトルの<div>要素が交互に並んでいる(同じ日付に複数の記事が存在することもある)。これを解析するのは大変そうだ。読み進む前に、どのようなコードを書けば実現できそうかを少し考えてみてほしい。
そのような記事のタイトルとURLを全て取り出し、先頭の10件だけを表示するコンソールプログラムは、Html Agility Packを使うと次のコードのように書ける。
static void Main(string[] args)
{
Console.WriteLine("HttpClientクラスで取得したWebページを解析する(Html Agility Pack)");
// 時間計測用のタイマー
var timer = new System.Diagnostics.Stopwatch();
timer.Start();
// .NET TIPSの日付順インデックスのURL(シフトJISのページ)
Uri webUri = new Uri("http://www.atmarkit.co.jp/ait/subtop/features/dotnet/index_date.html");
……省略……
string htmlText = ……省略(Webページの内容を文字列として取得)……
Console.WriteLine("HTML取得完了: {0:0.000}秒", timer.Elapsed.TotalSeconds);
if (htmlText != null)
{
// HtmlDocumentオブジェクトを構築する
var htmlDoc = new HtmlAgilityPack.HtmlDocument();
htmlDoc.LoadHtml(htmlText);
Console.WriteLine("HtmlDocument構築完了: {0:0.000}秒", timer.Elapsed.TotalSeconds);
// 目的の<a>要素を全て取り出して(XPath)、
// そのhref属性とInnerTextを持つ匿名型オブジェクトのコレクションを作る(LINQ)
// ※冒頭に「using System.Linq;」の追加が必要
var articles
= htmlDoc.DocumentNode
.SelectNodes(@"//div[@class=""da-tips-index-target""]/div[not(@class)]/a")
.Select(a => new
{
Url = a.Attributes["href"].Value.Trim(),
Title = a.InnerText.Trim(),
});
Console.WriteLine("タイトル取り出し完了: {0:0.000}秒", timer.Elapsed.TotalSeconds);
Console.WriteLine();
// 先頭10件を表示する
Console.WriteLine("記事タイトル先頭10件(全{0}記事中)", articles.Count());
foreach(var a in articles.Take(10))
{
Console.WriteLine(a.Title);
Console.WriteLine(" - {0}", a.Url);
}
}
#if DEBUG
Console.ReadKey();
#endif
}
Sub Main()
Console.WriteLine("HttpClientクラスで取得したWebページを解析する(Html Agility Pack)")
' 時間計測用のタイマー
Dim timer = New System.Diagnostics.Stopwatch()
timer.Start()
' .NET TIPSの日付順インデックスのURL(シフトJISのページ)
Dim webUri As Uri = New Uri("http://www.atmarkit.co.jp/ait/subtop/features/dotnet/index_date.html")
……省略……
Dim htmlText As String = ……省略(Webページの内容を文字列として取得)……
Console.WriteLine("HTML取得完了: {0:0.000}秒", timer.Elapsed.TotalSeconds)
If (htmlText IsNot Nothing) Then
' HtmlDocumentオブジェクトを構築する
Dim htmlDoc = New HtmlAgilityPack.HtmlDocument()
htmlDoc.LoadHtml(htmlText)
Console.WriteLine("HtmlDocument構築完了: {0:0.000}秒", timer.Elapsed.TotalSeconds)
' 目的の<a>要素を全て取り出して(XPath)、
' そのhref属性とInnerTextを持つ匿名型オブジェクトのコレクションを作る(LINQ)
Dim articles _
= htmlDoc.DocumentNode _
.SelectNodes("//div[@class=""da-tips-index-target""]/div[not(@class)]/a") _
.Select(Function(a) New With _
{
.Url = a.Attributes("href").Value.Trim(),
.Title = a.InnerText.Trim()
})
Console.WriteLine("タイトル取り出し完了: {0:0.000}秒", timer.Elapsed.TotalSeconds)
Console.WriteLine()
' 先頭10件を表示する
Console.WriteLine("記事タイトル先頭10件(全{0}記事中)", articles.Count())
For Each a In articles.Take(10)
Console.WriteLine(a.Title)
Console.WriteLine(" - {0}", a.Url)
Next
End If
#If DEBUG Then
Console.ReadKey()
#End If
End Sub
省略した部分ではWebページの内容を文字列として取得している。実際のコードは「.NET TIPS:HttpClientクラスでシフトJISのWebページを取得するには?[C#、VB]」をご覧いただきたい。取得したWebページの内容(=HTMLドキュメント)は、ローカル変数「htmlText」に格納される。
HTMLドキュメントをHtml Agility Packに解析させるには、Html Agility PackのHtmlDocumentオブジェクトを作ってHTMLドキュメントを与える。ここではHtmlDocumentオブジェクトのLoadHtmlメソッドに文字列を渡している(ストリームやローカルファイルのパスを渡す方法もある)。
構築し終わったHtmlDocumentオブジェクトから特定の要素(のコレクション)を取り出すには、XPathとLINQが利用できる。ここに記述したXPath(SelectNodesメソッドの引数に当たる部分)については、後ほど説明する。また、ここではLINQのSelectメソッドを使って*1、<a>要素から「href」属性の値とInnerText(=タグの内側の文字列)を取り出して匿名型のオブジェクト(のコレクション)を生成している*2。もちろん、匿名型ではなくきちんと定義したクラスを使ってもよい。
先頭の10件を表示しているところでは、LINQのTakeメソッドを使っている。
経過時間を表示するためにStopwatchクラス(System.Diagnostics名前空間)を使っている。コードを簡潔にするために計測を止めずにコンソール出力をしているので、正確な時間表示ではない。目安として見てほしい。
末尾には、Visual Studioからデバッグ実行したとき、コンソールがすぐに閉じてしまわないように「Console.ReadKey()」と記述してある。そこで何かキーを押すとプログラムは終了する。
いかにも面倒そうに思えた解析処理が、ほんの数行で終わっている(プログラムの文としては1文)。HTMLドキュメントを与えて構築し終えたHtmlDocumentオブジェクト(=ローカル変数「htmlDoc」)からHTMLの要素(のコレクション)を取り出すには、そのDocumentNodeプロパティのSelectNodesメソッドを使う。SelectNodesメソッドの引数にはXPathの文字列を与える。なお、DocumentNodeプロパティのChildNodesプロパティに対してLINQをいきなり使う方法も採れるが、XPathを使うよりもかなり面倒になる。上のコードからXPathを使っている部分を抜き出して、もう一度お見せする(次のコード)。
var articles
= htmlDoc.DocumentNode
.SelectNodes(@"//div[@class=""da-tips-index-target""]/div[not(@class)]/a")
.Select(……省略……
Dim articles _
= htmlDoc.DocumentNode _
.SelectNodes("//div[@class=""da-tips-index-target""]/div[not(@class)]/a") _
.Select(……省略……
HtmlDocumentクラスのSelectNodesメソッドで、目的の<a>要素を全て取り出している。その引数に与えている文字列がXPath(XML Path Language)だ。
このXPathは、取り出す要素までのパスを示したものだ。詳しくはMSDNの「XPath」で学んでもらいたいが、概略は次のような意味である。
- 「//div[@class="da-tips-index-target"]」:HTMLドキュメント内の全ての<div>要素の中で、class属性が「da-tips-index-target」となっているもの全て
- 「/div[not(@class)]」:それらの子要素になっている<div>要素の中で、class属性を持たないもの全て
- 「/a」:それらの子要素になっている<a>要素の全て
これで目的とする記事タイトルを含む<a>要素のコレクションが取得できたので、あとはLINQのSelectメソッドで必要な情報だけを抜き出した匿名型オブジェクトのコレクションを生成しているのである。
実行してみると、次の画像のようになる。見事に記事タイトルとURLを取り出すことができた。

*1 Selectメソッドの引数には、ラムダ式を与える。ラムダ式について詳しくは、次のMSDNのドキュメントを参照していただきたい。
- MSDN:ラムダ式 (C# プログラミング ガイド)
- MSDN:ラムダ式(Visual Basic)
*2 匿名型は、Visual Studio 2008で導入されたもので、クラス定義をせずにオブジェクトを作る方法だ。匿名型について詳しくは、次のMSDNのドキュメントを参照していただきたい。
- MSDN:匿名型(C# プログラミング ガイド)
- MSDN:匿名型(Visual Basic)
利用可能バージョン:.NET Framework 2.0以降
カテゴリ:クラスライブラリ 処理対象:HTMLドキュメント
使用ライブラリ:HtmlDocumentクラス(Html Agility Pack)
関連TIPS:HTMLファイルを簡単に解析するには?
関連TIPS:HTMLファイルからテキストを取り出すには?[C#、VB]
関連TIPS:HttpClientクラスでシフトJISのWebページを取得するには?[C#、VB]
関連TIPS:ReadJEncを使って文字エンコーディングを推定するには?[C#、VB]
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。