Watsonはスマートフォン/ウェアラブル端末で収集したユーザーデータの活用で医療ITを革新できるのか:ヘルスケアだけで終わらせない医療IT(4)(2/3 ページ)
Watsonの構成要素とサービスの全体像
ここでは、Watsonがどのような要素で構成され、どのようなサービスを提供しているのか、その全体像を見てみよう。
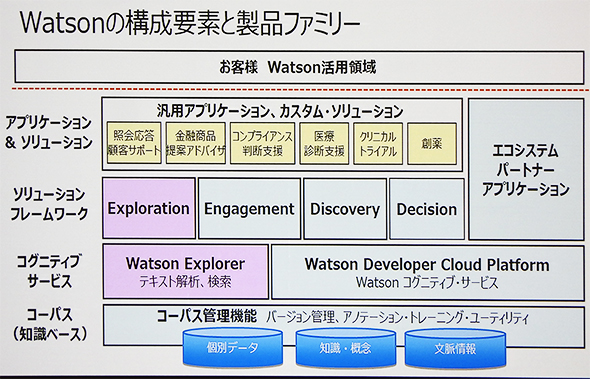
まず図の全体を見渡して、水色で示されているのが、クラウドで提供されるサービス、ピンク色で示されているのがソフトウエアパッケージとして提供されるサービスである。そして、黄色で示されているのが、IBMが提供するアプリケーション群である。
最も下のレイヤーに位置付けられているのが「コーパス」と呼ばれている知識ベース(個別データ、知識/概念、文脈情報)とその管理機能である。ここでは、Watsonにどのように情報を投入し、知識化していくのか、基本的な管理を担う。
その上が、Watsonのエンジンとして位置付けられる「コグニティブ・サービス」のレイヤーである。テキスト解析や検索の機能を提供するソフトウエアパッケージ「Watson Explorer」と、質問応答や機械翻訳などの基本的な「コグニティブ・サービス」をクラウドベースで提供する「Watson Developer Cloud」プラットフォームで構成されている。
その上のレイヤーが、ソリューションフレームワークであり、これを使うことで、より簡単にアプリケーションやソリューションを開発することが可能になる。
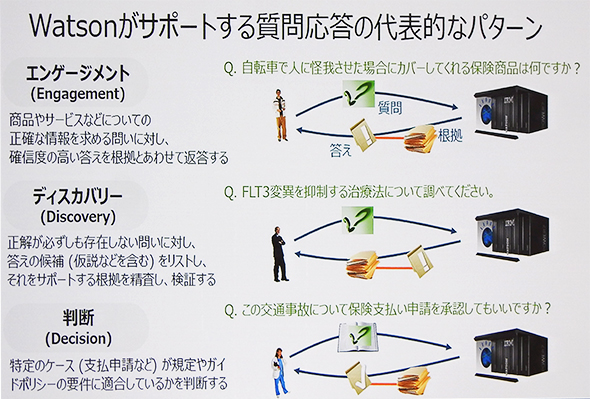
具体的には、アプリケーションビルダーやサービスアセットで構成されるソフトウエアパッケージ「Exploration」の他、質問に対して確信度の高い答えを根拠とともに返す「Engagement(エンゲージメント)」、正答が必ずしも存在しない問いに対して、答えの候補(仮説を含む)をリストし、根拠を精査して検証する「Discovery(発見)」、申請や要求が規定の要件に適合しているかどうかを判断する「Decision(判断)」などのクラウドベースのサービスが提供されている。
そして、もっとも上のレイヤーに位置付けられるのが、IBMが提供するアプリケーションやユーザーが開発するカスタムシステム、エコシステムパートナーが提供するアプリケーションとなる。
急ピッチで進化する「コグニティブ・サービス」
Watsonの核となる「コグニティブ・サービス」は、当初はQ&A(質問応答)サービスだけが提供されていたが、この1年の間に急ピッチで拡張が行われ、今後も多言語対応などを含む強化が進む見通しだ。
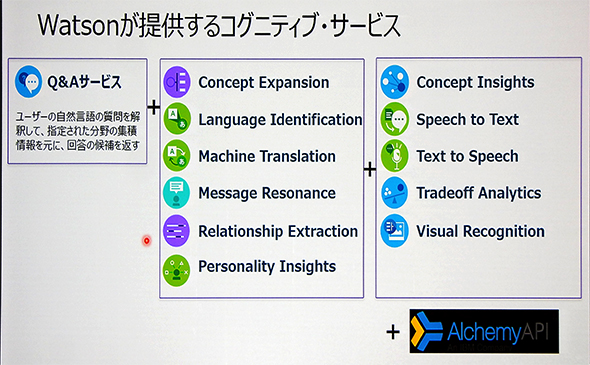
2014年2月には、対象者のプロファイリングを行う「Personality Insights」が正式にリリースされたのをはじめ、2014年10月には、機械翻訳の機能を提供する「Machine Translation」、どのような言語で書かれた文章かを判定する「Language Identification」、口語などの難しい表現から一般的で分かりやすい用語を導出する「Concept Expansion」、特定のコミュニティに対して最も共感が得られる用語を分析する「Message Resonance」、文章の構文解析を行って人、組織、場所などとの関係性を分析する「Relationship Extraction」の提供が開始された。
また、2015年2月には、英語のスピーチを音声認識してテキストに変換する「Speech to Text」、英語やスペイン語のテキストから自然なイントネーションの音声データを生成する「Text to Speech」、対象との関連を概念で識別して探索する「Concept Insights」、複数の競合や相反する要素に対して動的に重み付けを設定する「Tradeoff Analytics」、画像や動画を解析して、その内容を理解するための情報を提示する「Visual Recognition」の提供も開始されている。
さらにIBMは、これらの機能をAPIとして提供。同社が提供するPaaS「Bluemix」で利用できるようにしている。IBMはWatson以外についても、開発者が手軽にクラウドアプリケーションを開発できるようにBluemixのサービスを拡充しており、コンテストを開催するなどの力の入れようだ。前述したWatson HealthについてもBluemix上で利用できるようになることが予想される。開発者が医療に貢献できるアプリケーションを作ることができる環境が整いつつあるといえよう。
情報の洪水にさらされる医療現場
 日本IBM 東京基礎研究所 技術理事 武田浩一氏
日本IBM 東京基礎研究所 技術理事 武田浩一氏Watsonは、機能/サービスの強化が進む一方で、現実社会での活用に向けた実用化/商用化も急ピッチで進みつつある。中でも注目されているのが医療分野での活用である。その背景について、日本IBM 東京基礎研究所で技術理事を務める武田浩一氏は、次のように解説する。
「医療分野は、5年間で知識が倍増する、あるいは8年間で医療知識が刷新されると言われるほど、変化が早く、情報の洪水にさらされている。こうした状況の中で、医療従事者が十分な情報や知識を獲得し、高度な医療活動を遂行するためには、それを支援するためのツールが重要な役割を果たす」
では、医療分野での実用化のために、どのような能力が必要になるのだろうか。武田氏によると、クイズ番組で勝利するためだけの技術であれば、質問文の中の肯定表現だけに注目し、確信度の高い解答を計算すればよかった。しかし、医療分野においては、患者自身が訴える陽性の症状だけではなく、患者が自覚していない陰性の症状にも十分配慮しながら、エビデンス(根拠)に基づいて、最も確信度の高い診断のモデルを提示する必要がある。

また、Watsonの要素技術の一つであるテキスト分析の分野では、医学関連の大量のテキストを解析して関連性を見つけ出す従来型のテキストマイニング技術との連携が重要な課題になる。
すでにテキストマイニングの世界では、米国医学図書館がインターネット検索サービス「PubMed」を使って無料公開している膨大な医学情報の活用が実現されている。これらの情報には、2200万もの文献情報を収録した生物医学系データベース「MEDLINE」やライフサイエンス特許文書などが含まれている。
Watsonの医療支援システムでは、これらの医療文献情報とともに、電子カルテや臨床試験リポート、診療ガイドラインなどの情報を連携させて活用することで、医療従事者の活動をサポートできるようになっている。
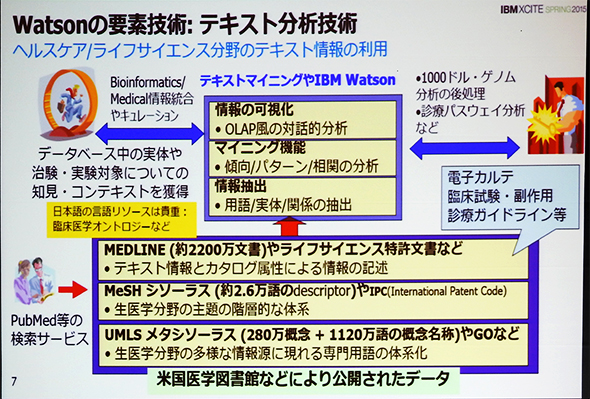
しかし、残念ながら、日本国内においては、米国のMEDLINEや臨床試験リポートのように充実した医療関連情報のリソースが整備されていないという問題がある。この点について、武田氏は、「現状のままでは、Watsonのシステムの日本語化が進んだとしても、国内で米国と同じレベルで活用することは難しい。国内でも、医療関連の情報リソースの早期の整備が望まれる」と指摘する。
Watsonの弱点を補完する技術を併用
一方、本格的な医療支援基盤を構築するためには、Watsonの弱点を補完する技術の導入も必要になる。例えば、Watsonは、文献やガイドラインに書かれた情報を手掛かりに答えを導き出す処理は得意としているが、時間的な関係を考慮した分析は苦手である。実際に、「入院患者のうち、手術をして経過の良かったのは、どの患者か」と問われても、Watsonの質問応答技術では対応することはできない。
そのため、医療従事者が、入院から退院までの診療プロセスの分析をきちんと行いたい場合には、Watsonのように蓄積された知識を使う技術とともに、大量のデータから時間的な関係を考慮して動的に答えを導き出す時系列分析技術を併用する必要が出てくる。現在、IBMの研究所ではWatsonの質問応答技術と時系列分析を併用するシステムの開発が進められているという。

関連記事
 スマートデバイスからのログ、病院DB、医療機器から得る画像――医療現場のビッグデータ活用を実践する3社の事例
スマートデバイスからのログ、病院DB、医療機器から得る画像――医療現場のビッグデータ活用を実践する3社の事例
医療、ヘルスケアに関連したテクノロジビジネスやスタートアップの動向を、エンジニアやビジネスマンに対して紹介するイベント「Digital Health Meetup Vol.2」のピッチセッションから3社の医療ベンチャーが開発したサービスやアプリの事例をお伝えする。 現役医師や医療ベンチャーが語る、医師会、IT活用、超高齢者、そして未来へ
現役医師や医療ベンチャーが語る、医師会、IT活用、超高齢者、そして未来へ
医療、ヘルスケアに関連したテクノロジビジネスやスタートアップの動向を、エンジニアやビジネスマンに対して紹介するイベント「Digital Health Meetup Vol.2」のパネルディスカッション「医療革命! 医師のIT活用とその未来について」の模様をお伝えする。 2025年問題、マイナンバー、改正薬事法――開発者が「唯一の成長市場」ヘルスケア/医療に参入する際の課題とは
2025年問題、マイナンバー、改正薬事法――開発者が「唯一の成長市場」ヘルスケア/医療に参入する際の課題とは
医療、ヘルスケアに関連したテクノロジビジネスやスタートアップの動向を、エンジニアやビジネスマンに対して紹介するイベント「Digital Health Meetup Vol.2」の講演「医療政策の動向から読み解く、これからの医療・介護業界」の模様からヘルスケア/医療業界に横たわる課題をまとめてお伝えする。 医療×IT 医師はプログラミングで医療の仕組みを変えられるか
医療×IT 医師はプログラミングで医療の仕組みを変えられるか
プログラミングはプログラマーだけの特権ではない?――ITを活用して自身の専門分野をより良くしていこうとチャレンジしている人たちにお話を伺うインタビューシリーズ、本日始動。 アップルがGitHubに公開した医療の研究調査用OSSフレームワーク「ResearchKit」の基礎知識
アップルがGitHubに公開した医療の研究調査用OSSフレームワーク「ResearchKit」の基礎知識
米アップルが2015年4月14日にGitHubに公開した医療の研究調査用OSSフレームワーク「ResearchKit」について、概要や機能、現時点でできないこと、どのようなアプリが作れるかについて紹介する。 医者はIT技術を学び、エンジニアは医学を学ぶ時代
医者はIT技術を学び、エンジニアは医学を学ぶ時代
2013年8月31日、「10年後の医療」をテーマに日本各地から1000人の医学生が都内に集結。「Medical Future Fes 2013」が開催された。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。