OpenStack、インストール後につまずかない、考え方・使い方のコツ(その1)――OpenStackはどのように構成されているか:特集:OpenStack超入門(9)(1/3 ページ)
いざ「OpenStackを使ってみよう」と思っても、方法が分からず使えなかった経験を持つ人も多いのでは? そこで本特集では、これから数回にわたり「OpenStackの構成例」を通じて使いこなしのコツを紹介していく。
OpenStackを使い始めるために
本特集ではOpenStackが求められる理由や、システム構築・運用における従来との違いやメリットなど、さまざまな視点からOpenStackの特徴を解説してきました。これまでの記事をご覧になられた方の中には、すでにOpenStackを使っている方もいるでしょうし、これから使ってみようと考えている方も多いのではないかと思います。
しかし、OpenStackを「使ってみよう」と行動を開始してから「使い始めた」に至るまでには、いくつかの壁があり、なかなかの労力が掛かります。というのも、OpenStack自体もオープンソースソフトウエア(以下、OSS)であるため、Githubのリポジトリからすぐにソフトウエアを取得することはできるのですが、「使い始める」ためのオペレーションまではOSSとして公開されていないからです。「全作業内容が網羅されたマニュアルがないとオペレーションできない」といった理由で、OpenStackに深い関心を持ちながらも使えなかった経験をお持ちの方もいるのではないでしょうか。
もちろん、以下のリンクのように、OpenStackコミュニティでもオペレーションをマニュアルとしてまとめてはいます。
- オペレーションマニュアル(OpenStack.org/英語)
- オペレーションマニュアル(OpenStack.org/日本語)
しかし、このマニュアルさえあればどのようなケースにも対応できるというわけではなく、皆さまがOpenStackでやりたいこと、すなわち個別の要件に沿ってオペレーションを応用していく必要があるのです。とはいえ、いくつかのポイントを知り、コツをつかめば、使うためのハードルをかなり下げることができます。
そこで本連載では、複数の「OpenStackの構成例」の紹介を通じて、“使いこなすためのコツ”を分かりやすく紹介していきます。皆さまの利用目的に合わせて、OpenStackを「使い始める」までの橋渡し役となれば幸いです。
OpenStack にはどんなプロセスがいるのか?
では最初に、「OpenStackはどんなプロセスで構成されているか」から説明していきましょう。
OpenStackでは、仮想マシン管理機能の「Nova」、仮想ネットワーク管理機能の「Neutron」、仮想ブロックストレージ管理機能の「Cinder」など、管理機能ごとにプロジェクトが分かれていることはご存じの通りです。今回は皆さまがほぼ間違いなく利用するであろう、Novaの代表的なプロセスを元に、OpenStackのプロセス構成を説明します。もちろん、プロジェクトごとにプロセスの種類や名前は異なりますが、構成に関する特質は似たところがあるため、他のプロジェクトでも同じように考えることができます。
まず、新しく仮想マシンを作成するときに動作するNovaのプロセスは、nova-api、nova-conductor、nova-scheduler、nova-compute の全4種類あります。そのプロセスをまとめると、以下の図1のようになります。
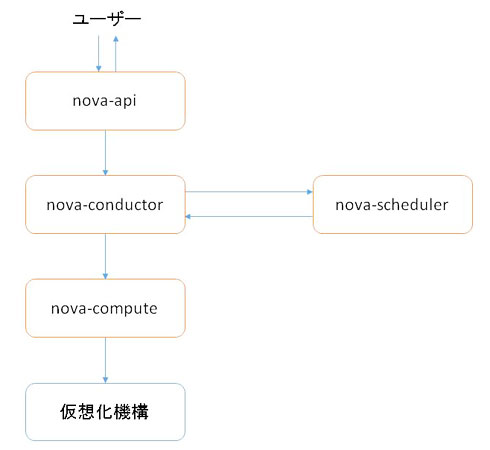 図1 VM起動までに関連するプロセス
図1 VM起動までに関連するプロセスnova-apiはユーザーからAPIのリクエストを受け取り、後続処理を実施する nova-conductorへリクエストを渡します。そして、nova-conductorへのリクエストの送信が完了した時点で、nova-apiはユーザーへAPIリクエストの受付完了のレスポンスを返します。nova-conductorはnova-apiからリクエストを受け取った後、VM起動までの非同期処理のマネジメントを実施します。
非同期処理の途中で、 nova-conductorは「起動するVMを、どのハイパーバイザーへスケジューリングするべきか」をnova-schedulerに問い合わせます。nova-conductorは、nova-schedulerから受け取ったハイパーバイザーの情報を元に、次はnova-computeへ実際のVM起動の依頼を行います。そして最後にnova-computeが、nova-conductorから受け取ったVM起動の依頼を元に、実際の仮想化機構に対してVMの作成を依頼します。
一方、これらプロセス間の通信はどのようにして実現されているのでしょうか? OpenStackでは、「nova-apiとnova-conductorの間の通信」などプロセス間の通信はメッセージキュー(以下MQ)を利用したRPC(Remote Procedure Call)で実現するのが一般的です。対して、「NovaとNeutron」など異なるプロジェクト間の通信には、それぞれのAPIを利用して通信を行っています。
これまでのプロセスの情報に追加して、OpenStackが利用するDBを加えると、以下の図2のように、Novaの4プロセスは連携して動作します。
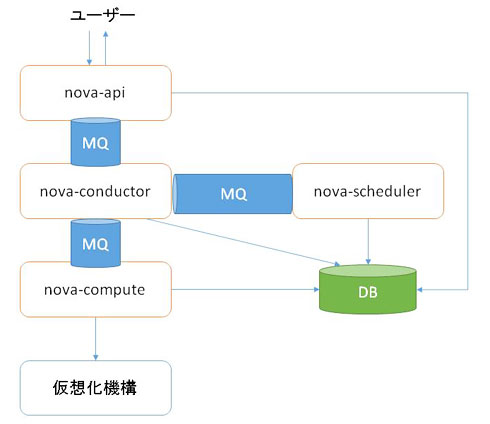 図2 Novaのプロセスの連携
図2 Novaのプロセスの連携図2で動作しているプロセスを大別すると、次の3種類のプロセスに分類できることが分かります。
- ユーザーからのAPIリクエストを受け付けるプロセス: nova-api
- APIに合わせた非同期処理のタスクを管理するプロセス: nova-conductor、nova-scheduler
- 仮想化機構に対して実際の操作を行うプロセス: nova-compute
これらのプロセスの分類は、Novaだけに限った話ではなく、ほとんどのプロジェクトで共通しています。例えば、仮想ネットワーク管理機能のNeutronでは、1と2をneutron-serverプロセスが担当しており、3をagentプロセスが担当しています。
関連記事
- OpenStackが今求められる理由とは何か? エンジニアにとってなぜ重要なのか?
スピーディなビジネス展開が収益向上の鍵となっている今、システム整備にも一層のスピードと柔軟性が求められている。こうした中、なぜOpenStackが企業の注目を集めているのか? 今あらためてOpenStackのエキスパートに聞く。 - OpenStackのコアデベロッパーは何をしているのか
@IT特集「OpenStack超入門」は日本OpenStackユーザ会とのコラボレーション特集。特集記事と同時に、日本OpenStackユーザ会メンバーが持ち回りでコミュニティの取り組みや、超ホットでディープな最新情報を紹介していく。第2回は日本OpenStackユーザ会メンバーで、OpenStack開発コミュニティ コアデベロッパーの元木顕弘氏が語る。 - ますます進化・拡大するOpenStackとOpenStackユーザーたち
@IT特集「OpenStack超入門」は日本OpenStackユーザ会とのコラボレーション特集。特集記事と同時に、ユーザ会メンバーが持ち回りでコミュニティの取り組みや、まだどのメディアも取り上げていない超ホットでディープな最新情報をコラムスタイルで紹介していく。第1回は日本OpenStackユーザ会会長 中島倫明氏が語る。 - 開発環境構築の基礎からレゴ城造り、パートナー交渉術まで〜OpenStack Upstream Trainingの内容とは?
OpenStack Summit Parisでは、数々の先進的な企業事例が登場した一方で、開発コミュニティ参加希望者に向けたオープンなトレーニングプログラムも企画されていた。OSSコミュニティのエコシステムの考え方まで考慮した2日間にわたるプログラムを、参加エンジニアがリポートします。 - OpenStack、結局企業で使えるものになった?
OpenStackを採用することで、企業のITインフラはどう変わるのか、導入のシナリオや注意点は何か。そんな問題意識の下で開催した@IT主催セミナー「OpenStack超解説 〜OpenStackは企業で使えるか〜」ではOpenStackの企業利用の最前線を紹介した。 - OpenStackとレゴタウンとの意外な関係
10月10、11日に東京で実施されたOpenStack Upstream Trainingでは、レゴを使った街づくりのシミュレーションが。レゴはOpenStackプロジェクトとどう関係するのか。 - いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。