Zabbix亄Pacemaker亄Fluentd亄Norikra亄Jenkins偱娔帇丄僋儔僗僞儕儞僌丄儘僌廂廤乛夝愅丄僶僢僋傾僢僾丗Elasticsearch亄Hadoop儀乕僗偺戝婯柾専嶕婎斦戝夝朥乮廔乯乮1/2 儁乕僕乯
儕僋儖乕僩偺帠椺傪婎偵丄戝婯柾BtoC僒乕價僗偵媮傔傜傟傞専嶕婎斦偼偳偆峔抸偝傟傞傕偺側偺偐丄偳傫側媄弍偑嵦梡偝傟偰偄傞偺偐丄塣梡偼偳偆側偭偰偄傞偺偐側偳偵偮偄偰夝愢偡傞楢嵹丅嵟廔夞偼丄娔帇丄僋儔僗僞儕儞僌丄儘僌廂廤乛夝愅丄僶僢僋傾僢僾偵巊偭偰偄傞OSS媄弍偲丄偦偺巊偄偳偙傠傪徯夘偡傞丅
丂儕僋儖乕僩偺慡幮専嶕婎斦乽Qass乿偺帠椺傪婎偵丄戝婯柾BtoC僒乕價僗偵媮傔傜傟傞専嶕婎斦偼偳偆峔抸偝傟傞傕偺側偺偐丄偳傫側媄弍偑嵦梡偝傟偰偄傞偺偐丄塣梡偼偳偆側偭偰偄傞偺偐側偳偵偮偄偰夝愢偡傞杮楢嵹丅
丂嵟廔夞偲側傞崱夞偼丄慜夞偺乽AWS亄僆儞僾儗偺僴僀僽儕僢僪僋儔僂僪側戝婯柾専嶕婎斦偱偼Immutable Infrastructure偲CI乛CD傪偳偆傗偭偰幚慔偟偰偄傞偺偐乿偵堷偒懕偒塣梡晹暘乮娔帇丒儘僌廂廤丒僶僢僋傾僢僾乯丄偦偟偰Qass偺崱屻偺揥朷偵偮偄偰偍揱偊偟傑偡丅
専嶕婎斦偺娔帇曽幃
丂僔僗僥儉傪埨掕壱摥偝偣傞偵偼丄乽僒乕僶乕傗傾僾儕働乕僔儑儞偑惓忢偵摦嶌偟偰偄傞偐乿乽梫媮偝傟傞僷僼僅乕儅儞僗偵懳偟偰儕僜乕僗偼懌傝偰偄傞偐乿傪忢偵娔帇偟丄忈奞傗儕僜乕僗晄懌傪偡偖偝傑娗棟幰偵捠抦偡傞巇慻傒偑昁梫晄壜寚偱偡丅Qass偱偼偦偆偟偨堦斒揑側僔僗僥儉娔帇偵壛偊偰丄Qass偺傾乕僉僥僋僠儍傗僒乕價僗偵懳墳偟偨撈帺偺儌僯僞儕儞僌傪峴偭偰偄傑偡丅偳偺傛偆側僾儘僟僋僩傪偳偺傛偆側栚揑偱妶梡偟偰偄傞偐丄偙傟偐傜徻偟偔尒偰偄偒傑偡丅
Zabbix傪拞怱偲偟偨娔帇偺偨傔偺媄弍
丂Qass偺娔帇偼丄摑崌娔帇僜僼僩僂僄傾偺Zabbix傪拞怱偵埲壓偺僣乕儖傪慻傒崌傢偣偰幚峴偟偰偄傑偡丅
丂Qass偺宲懕揑僀儞僥僌儗乕僔儑儞乛僨儕僶儕傪幚尰偡傞僣乕儖偲偟偰丄慜夞徯夘偟偨Chef傗Consul偲摨條丄OSS偱峔惉偝傟偰偄傞偙偲偑摿挜偱偡丅僆儞僾儗儈僗偺僒乕僶乕傗僱僢僩儚乕僋偺娔帇偵偮偄偰偼彜梡僜僼僩僂僄傾傕堦晹暪梡偟偰偄傑偡偑丄AWS忋偱壱摥偟偰偄傞僒乕僶乕偼Zabbix偺傒偱娔帇偟偰偄傑偡丅
丂僆儞僾儗儈僗偲僋儔僂僪偑崿嵼偡傞僔僗僥儉偵傕廮擃偵懳墳偱偒傞偙偲丄屻弎偡傞傛偆偵塣梡傪帺摦壔偱偒傞偙偲丄昗弨偺娔帇崁栚偵壛偊偰帺嶌偺僗僋儕僾僩傪娔帇偵巊偊傞偙偲偑Qass偵偍偗傞Zabbix偺儊儕僢僩偲尵偊傑偡丅
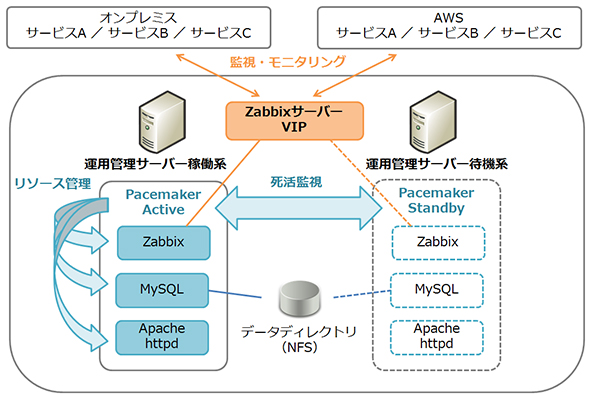
丂Zabbix僒乕僶乕偼僆儞僾儗儈僗偵2戜偁傝丄傾僋僥傿僽丒僗僞儞僶僀偺HA僋儔僗僞乕偲偟偰忕挿峔惉傪庢偭偰偄傑偡丅僋儔僗僞儕儞僌偼Pacemaker偱幚憰偟丄Zabbix丄MySQL丄Apache HTTP Server傪1偮偺儕僜乕僗僌儖乕僾偲偟偰娗棟偟偰偄傑偡丅Zabbix僒乕僶乕偼壖憐IP傾僪儗僗傪巊梡偟偰偍傝丄僼僃僀儖僆乕僶乕偡傞偲懸婡宯偑堷偒宲偄偱娔帇傪宲懕偟傑偡丅
僆儞僾儗儈僗偲AWS偺楢実
丂Qass偱偼僆儞僾儗儈僗乣AWS娫偺愙懕偵愱梡慄乮DirectConnect乯傪棙梡偟丄AWS偵Amazon Virtual Private Cloud乮VPC乯傪揔梡偡傞偙偲偱椉娐嫬傪摨堦偺僱僢僩儚乕僋傾僪儗僗懱宯偱塣梡偟偰偄傑偡丅偦偺偨傔丄Zabbix偺僱僢僩儚乕僋僨傿僗僇僶儕婡擻傗帺摦搊榐婡擻傪愝掕偟偰偍偗偽丄AWS偵僒乕僶乕乮僀儞僗僞儞僗乯傪怴偨偵峔抸偟偨帪揰偱帺摦揑偵儂僗僩傪搊榐偱偒傑偡丅
丂偨偩偟丄Zabbix偺儂僗僩柤偼廳暋偑嫋偝傟側偄偨傔丄Immutable Infrastructure偲偟偰僀儞僗僞儞僗傪嶌傝懼偊傞嵺偼怴媽偺儂僗僩柤傪暿乆偵愝掕偡傞偙偲偵側傝傑偡丅偦偆側傞偲儂僗僩搊榐傕暿屄偱峴傢傟丄儌僯僞儕儞僌偺儘僌傪堦娧偟偰尒搉偣側偄側偳偺晄曋偑惗偠傑偡丅
丂Qass偺娔帇曽幃偱偼丄AWS API偲Zabbix API傪梡偄偰偙偆偟偨壽戣偵懳張偟偰偄傑偡丅Immutable Infrastructure偺價儖僪僼儘乕偵偍偄偰怴偟偄僀儞僗僞儞僗傪峔抸偟丄僥僗僩傑偱姰椆偟偨屻偼AWS SDK for Ruby傪棙梡偟偨帺嶌僗僋儕僾僩偱埲壓偺張棟傪峴偄傑偡丅
- Zabbix偵搊榐偝傟偰偄傞儂僗僩偺堦棗傪Zabbix API偱庢摼偡傞
- AWS偵懚嵼偡傞僀儞僗僞儞僗偺忣曬傪AWS API偱庢摼偡傞
- Zabbix偺儂僗僩堦棗偲AWS偺僀儞僗僞儞僗忣曬傪斾妑偡傞
- 僀儞僗僞儞僗偺儂僗僩搊榐偑峴傢傟偰偄傞応崌偼Zabbix API偱IP傾僪儗僗傪忋彂偒偟偰娔帇傪桳岠壔偡傞
- 僀儞僗僞儞僗偑幚嵼偟側偄偵傕偐偐傢傜偢丄儂僗僩搊榐偝傟偰偄傞応崌偼娔帇傪柍岠壔偡傞
丂幚嵼偟側偄僀儞僗僞儞僗偵偮偄偰乽儂僗僩嶍彍乿偱偼側偔乽娔帇柍岠壔乿偡傞棟桼偼丄儌僯僞儕儞僌偺儘僌傪巆偟偰屻偐傜怳傝曉傞偙偲偑偱偒傞傛偆偵偡傞偨傔偱偡丅偙傟傜堦楢偺嶌嬈偑廔傢傝師戞丄師偺傾僋僔儑儞偲偟偰怴僀儞僗僞儞僗傪ELB偵庢傝晅偗丄媽僀儞僗僞儞僗偺愗傝棧偟偲攋婞傪峴偄傑偡丅
Fluentd偺儘僌廂廤婎斦
丂娔帇傗儌僯僞儕儞僌偺傒側傜偢丄傾僾儕働乕僔儑儞偺僄儔乕夝愅傗偝傜側傞専嶕夵慞偵岦偗偰儘僌傪曐懚偟偰偍偔偙偲傕昁梫偱偡丅Qass偱偼丄朻摢偵傕婰偟偨傛偆偵Fluentd乮td-agent乯傪梡偄偰儘僌廂廤傪幚巤偟偰偄傑偡丅
丂儘僌廂廤偺僜僼僩僂僄傾偲偟偰丄rsyslog傗Flume丄Logstash側偳偑懠偵懚嵼偟傑偡偑丄Qass偱偼埲壓偺億僀儞僩傪昡壙偟偰Fluentd傪嵦梡偟傑偟偨丅
- RPM僷僢働乕僕1偮偺傒偱峔抸偑壜擻
- 懡條側Input乛Output僼僅乕儅僢僩偑僾儔僌僀儞宍幃偱採嫙偝傟偰偄傞
- Ruby偱婰弎偝傟偰偄傞偨傔丄Chef側偳偱Ruby傪棙梡偟偨僀儞僼儔僄儞僕僯傾偑恊偟傒傗偡偄
- 忕挿壔傗晧壸暘嶶偑昗弨婡擻偲偟偰旛偊傜傟偰偄傞
丂摿偵RPM僷僢働乕僕1偮偺傒偲峔惉梫慺偑彮側偔丄娗棟懳徾傪嵟掅尷偵偱偒傞偙偲偼丄Chef側偳偱峔抸偑帺摦壔偝傟偰偄傞拞偱傕儊儕僢僩偲姶偠傑偡丅傑偨丄奺僜僼僩僂僄傾傪専徹偟偨嵺偵嵟傕晧壸偑掅偐偭偨偺偑Fluentd偱偁傝丄専嶕婎斦偱壱摥偡傞傾僾儕働乕僔儑儞偵彮偟偱傕懡偔偺儕僜乕僗傪妱傝怳傝偨偄偲偄偆堄恾偵傕偐側偭偰偄傑偟偨丅
Fluentd偺峔惉
丂Fluentd偱偼偲偰傕廮擃偵揮憲傗儘僕僢僋幚峴側偳偑偱偒傞偺偱丄偦傟偩偗愝寁偺帺桼搙傕崅偔側傝傑偡丅偨偩偟丄偦偺拞偱偼塣梡奐巒屻偵曄峏偑壛傢傞売強傪偱偒傞偩偗尭傜偟丄塣梡晧壸傪壓偘傜傟傞傛偆偵偡傞偙偲傪堄幆偟側偗傟偽側傝傑偣傫丅
丂摫擖摉弶偼僲乕僪偺栶妱偺嬫暘偑側偔丄昁梫側売強偱揮憲丒廤栺傪峴偭偰偄傑偟偨丅偟偐偟丄乽僲乕僪悢偑憹偊傞偵偮傟偰丄偳偺儘僌偑偳偺傛偆偵揮憲偝傟偰偄傞偐乿乽Config傗峔惉梫慺偑偳偺僲乕僪偵塭嬁傪媦傏偡偐乿偑敾抐偟偯傜偄忬嫷偲側偭偰偒傑偟偨丅偦偺偨傔丄尰嵼Qass偱偼Fluentd偺峔惉偲偟偰僔儞僾儖側Forwarder乛Aggregator偺儌僨儖傪嵦梡偟偰偄傑偡丅
丂偙偙偱奺僲乕僪偺栶妱偼丄師偺傛偆偵柧妋偵嬫暿偝傟偰偄傑偡丅
- Forwarder偼丄昁梫側儘僌僼僅乕儅僢僩偺惍宍偍傛傃Aggregator僲乕僪傊偺揮憲偺傒傪幚巤
- Aggregator偼丄儘僌廤栺傗曐懚愭偺妱傝怳傝丄儘僕僢僋幚峴傪扴摉
丂僒乕價僗傪採嫙偡傞僲乕僪偵偼Forwarder偲偄偆栶妱偺傒傪梌偊丄儘僌廤栺偡傞偨傔偺僲乕僪偵塣梡婡擻傪埾偹傞偙偲偱奺僲乕僪娫偺Config偺埶懚傪壜擻側尷傝尭傜偟丄僨乕僞偺棳傟傪暘偐傝傗偡偔偟偰偄傑偡丅

丂忋婰偺傛偆側峔惉偱偼丄Aggregator僲乕僪懁偱廮擃偵僨乕僞揮憲愭傪巜掕偡傞偙偲偑壜擻偲側傝丄暘愅婎斦傪捛壛偡傞嵺傗僨乕僞楢実愭傪憹傗偟偨偄偲偄偭偨働乕僗偵懳墳偟傗偡偔側傝傑偡丅傑偨丄Forwarder僲乕僪偑憹壛偟偨嵺偵摦揑偵儊僩儕僋僗傪妱傝怳傟傞傛偆丄乽fluent-plugin-forest乿傪棙梡偟偨Config偲偟偰偍偔偙偲偱丄愝掕傪峏怴偡傞偙偲側偔僒乕僶乕捛壛偑峴偊傞傛偆偵側偭偰偄傑偡丅
娭楢婰帠
 宲懕揑僀儞僥僌儗乕僔儑儞傪巒傔傞偨傔偺婎慴抦幆
宲懕揑僀儞僥僌儗乕僔儑儞傪巒傔傞偨傔偺婎慴抦幆
戝婯柾奐敪偲CI偺娭學丄CI惢昳乛僒乕價僗7慖丄慖掕偺3偮偺億僀儞僩丄Jenkins摫擖偱夝寛偟偨栤戣揰側偳傪夝愢偡傞 宲懕揑僨儕僶儕乛僨僾儘僀傪幚尰偡傞庤朄丒僣乕儖傑偲傔
宲懕揑僨儕僶儕乛僨僾儘僀傪幚尰偡傞庤朄丒僣乕儖傑偲傔
僶乕僕儑儞娗棟傗宲懕揑僀儞僥僌儗乕僔儑儞偲傕枾愙偵娭傢傞宲懕揑僨儕僶儕乛僨僾儘僀儊儞僩偺奣梫傗庡側僣乕儖丄宱堒丄幚慔帠椺傪徯夘丅幚慔庤朄偲偟偰乽僽儖乕僌儕乕儞丒僨僾儘僀儊儞僩乿乽Immutable Infrastructure乿偑拲栚偩丅 24帪娫搑愗傟側偄僒乕價僗偱桳岠側Immutable Infrastructure偺塣梡曽朄
24帪娫搑愗傟側偄僒乕價僗偱桳岠側Immutable Infrastructure偺塣梡曽朄
戝婯柾僾僢僔儏捠抦婎斦偵偮偄偰丄乽Pusna-RS乿偺幚憰帠椺傪婎偵傾乕僉僥僋僠儍傗塣梡傪夝愢偡傞楢嵹丅崱夞偼丄Pusna-RS偺塣梡柺傗敪惗偟偨壽戣偵偮偄偰丄巊梡偟偰偄傞媄弍傗僣乕儖乽AWS Elastic Beanstalk乿乽Jenkins乿乽Amazon CloudWatch乿乽GrowthForecast乿乽fluentd乿乽Elasticsearch乿乽Kibana乿側偳偺愢柧傪岎偊側偑傜徯夘偟傑偡丅 偄傑偝傜暦偗側偄乽僋儔僂僪偺婎慴乿乣僋儔僂僪僼傽乕僗僩帪戙偺忢幆丒旕忢幆乣
偄傑偝傜暦偗側偄乽僋儔僂僪偺婎慴乿乣僋儔僂僪僼傽乕僗僩帪戙偺忢幆丒旕忢幆乣
僋儔僂僪偺壜擻惈傗揔梡椞堟傪昡壙偡傞帪戙偼夁偓嫀傝丄僋儔僂僪棙梡傪慜採偵峫偊傞乽僋儔僂僪僼傽乕僗僩乿帪戙偵撍擖偟偰偄傞丅杮楢嵹偱偼僋儔僂僪傪巊偭偨SI偵朙晉側抦尒傪帩偮丄TIS偺IT傾乕僉僥僋僩 徏堜挩擵巵偑丄僋儔僂僪帪戙偺僔僗僥儉僀儞僥僌儗乕僔儑儞偺嵼傝曽傪婎慴偐傜暘偐傝傗偡偔夝愢偡傞丅 愨懳偵墴偝偊偰偍偒偨偄丄挻崅懍僔僗僥儉峔抸5梫審偲3偮偺僥僋僲儘僕
愨懳偵墴偝偊偰偍偒偨偄丄挻崅懍僔僗僥儉峔抸5梫審偲3偮偺僥僋僲儘僕
懡偔偺婇嬈偵偲偭偰乬僋儔僂僪僼傽乕僗僩乭偑僉乕儚乕僪偲側偭偰偄傞崱丄僋儔僂僪傪乽揔愗偵乿妶梡偡傞擻椡偼SIer傗IT晹栧偺僄儞僕僯傾偵偲偭偰昁恵偺媄擻偲側偭偰偄傞丅崱夞偼價僕僱僗梫惪偵傾僕儍僀儖偵墳偊傞乽僋儔僂僪僼傽乕僗僩帪戙偺僔僗僥儉僀儞僥僌儗乕僔儑儞乿偵昁梫側梫慺媄弍傪夝愢偡傞丅
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅