深層学習の判別精度を向上させるコツとActive Learning:いまさら聞けないDeep Learning超入門(終)(1/2 ページ)
最近注目を浴びることが多くなった「Deep Learning」と、それを用いた画像に関する施策周りの実装・事例について、リクルートグループにおける実際の開発経験を基に解説していく連載。最終回は、画像認識の判別精度を向上させる具体的手順と落とし穴、ハイパーパラメーターのチューニング、学習を自動化するActive Learningについて。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
赤裸々に解説
最近注目を浴びることが多くなった「Deep Learning(ディープラーニング・深層学習)」と、それを用いた画像に関する施策周りの実装・事例について、リクルートグループにおける実際の開発経験を基に解説していく本連載。
前回までは、下記のように解説してきました。ニューラルネットワーク、Deep Learning、Convolutional Neural Net(CNN)の基礎知識と活用例、主なDeep Learningフレームワークを紹介し、リクルートグループで画像解析において積極的に利用しているフレームワーク「Caffe」を中心にDeep Learningを利用した画像解析について解説。そして、リクルートグループにおける画像解析の事例を紹介し、ビジネスへの活用に当たり、CNNだけでは乗り超えられない壁を乗り越えるまでの試行錯誤の過程を解説しました。
- 第1回「ニューラルネットワーク、Deep Learning、Convolutional Neural Netの基礎知識と活用例、主なDeep Learningフレームワーク6選」
- 第2回「Caffeで画像解析を始めるための基礎知識とインストール、基本的な使い方」
- 第3回「もう絶望しない! ディープラーニングによる画像認識のビジネス活用事例」
最終回となる第4回では、リクルートグループにおける画像解析施策の実例を基に、判別精度向上の試みを赤裸々に解説していきます。
判別精度向上の具体的手順
Deep Learningに限らず、一般的に予測・分類などの目的で機械学習を行う際には、「判別精度」に着目してモデルの作成、チューニングを行います。この判別精度向上という作業が機械学習に携わる人間にとっては腕の見せ所であり、楽しみであり、また苦難が続く過程でもあるのです。
連載第3回で紹介した、ホットペッパービューティ―(リクルートライフスタイル運営)のネイルデザイン判別を例にすると、実際の判別精度の確認、向上作業は下記のような過程で進んでいきます。
- 対象となる画像を用意する
- 全ての画像に正解ラベルのラベリングを行う
- 訓練用データを学習し、モデリングを行う
- テストデータをモデルに適応し、予測を行う
- 予測したラベルの判別精度を確認する。
- モデルのチューニングを行う
画像を用意し、「正解」のラベリング
最初に、ネイルのデザイン画像を用意しラベル付けを行います。第3回でも記載した通り、投稿された「手の全体画像」からネイルに該当する部分を1枚ずつ切り出す作業を前処理として行っており、画像入稿時に付与される「手全体に対する単一のデザインラベル」をそのまま使用することはできません。そのため、切り出したネイル写真1枚1枚に対して人手で正解デザインのラベル付けを行う必要がありました。今回のモデリング用には最終的に4万718枚もの画像を用意しました。(この作業のおかげで、私たちはリクルートテクノロジーズの中でも1、2を争うほどネイルデザインに詳しくなったという伝説が生まれました)。
学習開始――モデルの作成とラベルの予測
次に、いよいよモデルを作成します。本施策では、40718枚の画像のうち、モデルの学習に用いる訓練データとして3万6633枚、予測用のテストデータとして4085枚の約9:1の割合で分割しました。この訓練データを用いてモデルを作成し、4085枚のテストデータのラベルを予測します。
学習に全てのデータを使いたいところですが、ここで全てのデータを学習に用いてしまうと、訓練データがデータとしての代表性に欠けているケースが実際に多いために、「過学習」と呼ばれる「訓練データに対してよく学習されているが、未知のテストデータに対しては適合できていない」事象に遭遇することが多くなります。
判別精度を確認
この未知データの予測処理が終わった後、実際に手動でラベル付したデザインと予測結果を比較し、答えが合っているかどうかで精度を算出します。
この全体精度に加えて、下記のようなConfusion Matrixを基に「どのデザインの精度がよかったか」などを考察し、各種ハイパーパラメーター変更や訓練データの追加などを行いながら、この一連の過程を 繰り返すことで精度を高めていきます。これが「チューニング」と呼ばれる作業です。
また、この精度検証では通常「K-分割交差検証」などの交差検証(Cross-validation)を用いて精度検証を行うとよいのですが、実際の現場では施策リリース時期などの制限もあり、簡易的な精度チェックを基にチューニングを繰り返すことになる方が多いようです。
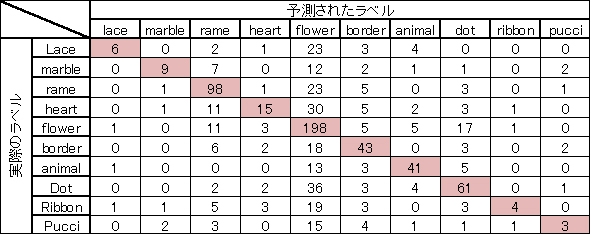
例えば、このConfusion Matrixからは、「animal」については、「実際にanimalとラベル付された74枚ラベルのうち、41枚がanimalと予測された」ので、半分以上の正答率となると分かります。一方で、「flower」に関してはどのデザインにおいても誤判別されやすい傾向があり、このflowerのデータからうまく特徴量が取り出せていない可能性があることも分かります。
ハイパーパラメーターのチューニング
Deep Learningにおける精度向上方法といえば、ハイパーパラメーター群のチューニングが真っ先に思い浮かぶと思います。連載第3回でも一部ご紹介しましたが、Deep Learningではハイパーパラメーターの種類が非常に多く、代表的なものを挙げるだけでも下記のようなパラメーター群が存在します。
- 学習係数:一回のイテレーションで進む学習の度合い
- イテレーション数:学習を繰り返す最大の回数
- モーメンタム:最適な重みを導き出すための勾配法の高速化パラメーター
- 隠れ層のユニット数:隠れ層の数。基本的に大きければ大きいほどよいが、過学習には注意
- 活性化関数の数・種類:Sigmoid、Tanh、ReLUなどの関数の種類と、「層をいくつ、どのタイミングで組み入れるか」などの調整
- Dropoutの数:学習時のパラメーターのいくつかを任意の確立で使わないようにし、汎化性能を上げる仕組み
これらのパラメーターを変更後、モデルを作成し精度を見るという方法を幾度か繰り返すことになります。「グリッドサーチ」と呼ばれる自動的に最適なハイパーパラメーターを探索する手法もありますが、現実的にはいくつか重要なパラメーターに絞り、順番を決め、その値を変更して最適値を求めていく手法が多く採られる傾向があります。
ネイルの画像判別においても、実に100回前後の試行を繰り返しました。下記のようにイテレーション数やdropoutの数などを変え精度の改善を図っていくのが現実的です。
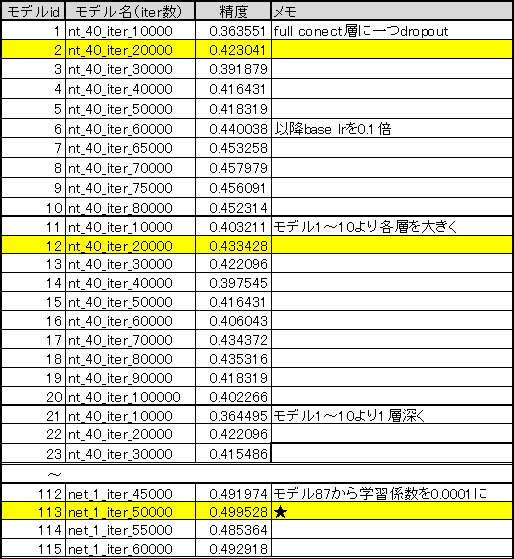
この図から、最終的にはパラメーターチューニングにより、20ラベルに対して50%程度の精度向上ができた過程が見てとれると思います。
関連記事
 グーグルの人工知能を利用できるWebインターフェースが登場
グーグルの人工知能を利用できるWebインターフェースが登場
オズミックコーポレーションとイントロンワークスは7月7日、グーグルの人工知能アルゴリズム「Deep Dream」を利用できるWebインターフェースを公開した。 人工知能の歴史と、グーグルの自動運転車が事故を起こさないためにしていること
人工知能の歴史と、グーグルの自動運転車が事故を起こさないためにしていること
本連載では、公開情報を基に主にソフトウエア(AI、アルゴリズム)の観点でGoogle Carの仕組みを解説していきます。今回は、ロボットの思考と行動のサイクルのうち「行動計画の立案」と「計画した動作の実行」について解説。最後に人工知能の歴史も。 顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
アドビ システムズは、2015年10月6日(現地時間)に開催した「Adobe MAX 2015 Sneak Peeks」で、11の新技術を披露。顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成naなど、今回もデザイナー/クリエイターのみならず、日常的にデジカメやスマホで写真を撮る人でも欲しくなるような機能が多数見られた。 米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
Deep-Learning技術による画像認識プラットフォームを展開してきたAlpacaDBが、資金調達に成功し、金融系の事業領域に本格進出する。 セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
どうしても攻撃者の後手に回りがちなセキュリティ対策。ここに機械学習を活用することで、先手を打った対策を実現できないか――そんな取り組みが始まろうとしている。 個人と対話するボットの裏側――大衆化するITの出口とバックエンド
個人と対話するボットの裏側――大衆化するITの出口とバックエンド
マシンラーニング、ディープラーニングなど、未来を感じさせる数理モデルを使ったコンピューター実装が注目されている。自ら学習し、機械だけでなく人間との対話も可能な技術だ。では、コンピューターはどのように人間との対話を図ればよいのだろうか。コンピューターの技術だけでなく、そこで実装されるべきインターフェースデザインを考えるヒントを、あるコンシューマーアプリ開発のストーリーから見ていく。 バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
8月26日に開催されたゲーム開発者向けイベントの中から、バンナム、スクエニ、東ロボ、MSなどによる人工知能や機械学習、データ解析における取り組みについての講演内容をまとめてお伝えする。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。