Unicode(ユニコード):Tech Basics/Keyword
デバイスやOSを問わず、システムの標準的な文字コードとして広く使われるようになった文字コード「Unicode」。その特徴や登場の背景、キーとなる技術をまとめる。

「Unicode」(ユニコード)は、世界中の文字を1つの文字コード体系で扱えるように作られた、文字コードセットの規格。現在のコンピュータシステムでは内部コードをこのUnicodeにして、世界中でほぼ同じバイナリーコードを使えるようにしていることが多い。Unicodeコンソーシアムが規格を策定している。
Unicode登場の背景
Unicodeが登場するまでは、コンピュータシステムではShift_JIS(主にDOSやWindows)やEUC(Extended UNIX Code、主にUNIX)、EBCDIC(主にメインフレームコンピュータ)などのコードが使われていた。
これらは、英語ともう1つの言語(日本語や中国語など)を使う分には特に問題はなかったものの、さらに多くの言語を同時に使うのは困難であった。また文字コード体系に合わせてプログラムをいちいち修正する必要があるなど、取り扱いも簡単ではなかった。
Unicodeの狙いと特徴
そこで考案されたのが、世界中の文字コードを統一して扱えるようにしたUnicodeである。全ての文字種を同じように扱えるため、言語の種類によってプログラムを変更する必要がなく、文字列部分さえ翻訳すれば、簡単に多言語化/国際化できる(実際には、各国固有の機能の追加も必要になるが)。
Unicodeのアイデアの基本は、世界中の文字を16bitの固定長で表現し、文字列の取り扱いを容易にすることである。
そのため、最初の規格ではCJK統合漢字(後述)などを使って必要なコード領域の圧縮を図っていた。しかし、その後の文字コードの追加などで、16bitでは表現しきれないほど多くの文字数になった。それでも、サロゲートペア(後述)を使って16bit単位で扱えるようにするなど、16bitのままでも使いやすくなる工夫を導入している。
また単なる文字コード表といった位置付けにとどまらず、複数のUnicode文字を組み合わせてより複雑な漢字や記号などを表現したり(合字や結合文字など)、文字を表示する向きを指定する(右から左へ書く)、異体字の選択機能を導入するなど、実装や運用にまで踏み込んだ定義が含まれている。
Unicodeに関する規格
世界中の文字コードを統一したコード体系という考え方は、Unicodeだけでなく、文字コードの国際標準規格を制定しているISO/IEC 10646でも考慮されていたが、最終的にはUnicode案に一本化された。現在では、UnicodeコンソーシアムがUnicodeの新しい規格を制定すると、それがほぼそのまま国際標準規格であるISO/IEC 10646「Universal Coded Character Set(UCS)」として承認されている。さらにそれを日本向けにしたものとしてJIS X 0221「国際符号化文字集合(UCS)」が制定されている。
Unicode規格は以下のように何度か大きく改定されている。最近では絵文字を取り入れたり、現代の文字だけでなく、古代の(既に使わなくなったような)文字まで取り入れたりと、古文書も含めたあらゆる文字情報をデータ化できるように改定され続けている。
| バージョン | 変更点 |
|---|---|
| Unicode 1.x | CJK統合漢字を含んだ最初のUnicode規格 JIS X 0201/JIS X 0208(第1、第2水準漢字)、JIS X 0212(補助漢字)を含む |
| Unicode 2.x | BMP以外の面を追加して、サロゲートペアによるアクセスを実現 |
| Unicode 3.x | CJK統合漢字の拡張Aを追加。JIS X 0213(第3、第4水準漢字)の一部を追加 |
| Unicode 4.x | ISO/IEC 10646:2003の追補Amd.1に対応 |
| Unicode 5.x | ISO/IEC 10646:2003の追補Amd.2などに対応 |
| Unicode 6.x | ISO/IEC 10646:2010/2012などに対応 |
| Unicode 7.x | ISO/IEC 10646:2012の追補Amd.1、Amd.2に対応。絵文字の追加 |
| Unicode 8.x | ISO/IEC 10646:2014の追補Amd.1に対応 |
| Unicodeの主なバージョンと概要 最近のバージョンアップでは、新しい文字セットの追加がメインとなっている。 | |
以下では、Unicodeのキーとなる部分を幾つか取り上げ、解説する。
Unicodeのコードポイント(U+0000〜U+10FFFF)
Unicodeで定義されている文字には、全て番号(コードポイント。単に文字コードとも)が付けられている。
また文字コードは「U+nnnn」という方法で表記する。nは4〜6桁の16進数で表現した文字コード番号である。
現在のUnicodeでは「U+0000〜U+10FFFF」までの範囲を使用することにしている。総数にすると111万4112文字まで収容可能ということになる(Unicode 8.0で実際に定義されているのは約12万文字)。
面、区、点
現在のUnicodeのコードを全て表現するには21bitのデータ幅が必要になる。これを24bitまで拡大し、上位から8bit、8bit、8bitと区切ったものをそれぞれ「面(plane)」「区(row)」「点(cell)」と呼ぶ(以前は「面」の上に「群(group)」という分類もあったが、Unicodeの上限がU+10FFFFなので常に群0しか存在せず、不要なので現在では群という用語は廃止された)。
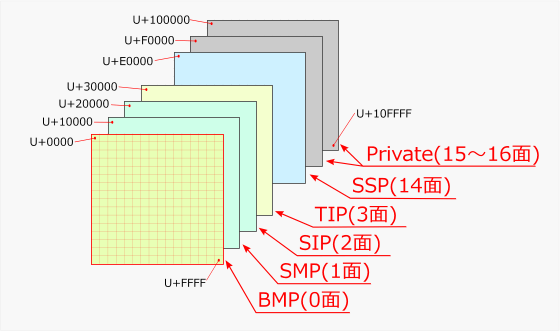 Unicodeの面
Unicodeの面256×256の文字の集まりを「面」と言い、Unicodeでは第0面から第16面までを使うことになっている。第0面は16bitのコードで表現できるので使いやすいが、第1面以降はより多くのbit数が必要なので取り扱いが少し面倒である。アプリケーションによっては、BMP面のUnicodeしか扱えないものもある。
面には、その内容に応じて次のような名前が付けられている。
| 面 | コード位置 | 名称、用途 |
|---|---|---|
| 第0面 | U+0000〜U+FFFF | ・基本多言語面(Basic Multilingual Plane:BMP) ・現在よく使われている欧米のアルファベットやCJK漢字コードなどが割り当てられている。最初のUnicode規格で制定されていた領域 ・この面のコードは16bit以内で表現できるため、コード効率がよい |
| 第1面 | U+10000〜U+1FFFF | ・追加多言語面(Supplementary Multilingual Plane:SMP) ・現在ではあまり使われていない古代の文字や、顔文字などの記号類を収容 |
| 第2面 | U+20000〜U+2FFFF | ・追加漢字面(Supplementary Ideographic Plane:SIP) ・人名でしか使わないような、使用頻度の低い漢字などを収容 |
| 第3面 | U+30000〜U+3FFFF | ・第三漢字面(Tertiary Ideographic Plane:TIP) ・甲骨文字などの古代文字を収容する予定の領域 |
| 第4〜13面 | U+40000〜U+ DFFFF | (未使用) |
| 第14面 | U+E0000〜U+EFFFF | ・追加特殊用途面(Supplementary Special‐purpose Plane:SSP) ・言語タグや異体字セレクタなどを収容 |
| 第15面 | U+F0000〜U+FFFFF | ・私用面(Private Use) ・外字などで使用できる |
| 第16面 | U+100000〜U+10FFFF | ・私用面(Private Use) ・外字などで使用できる |
| Unicodeの面番号とその用途 | ||
基本多言語面(BMP)の文字の例を次に示しておく。
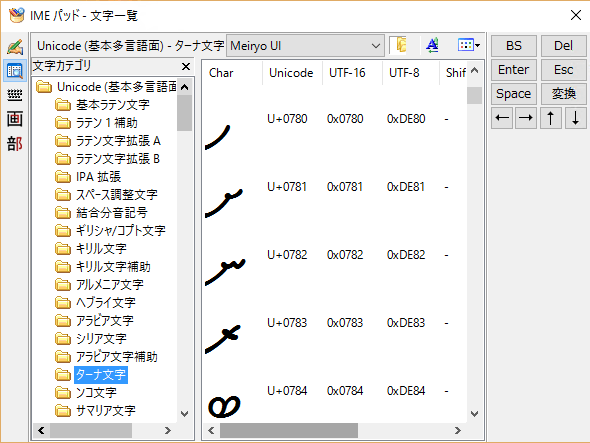 Unicodeの基本多言語面(BMP)の例
Unicodeの基本多言語面(BMP)の例これはWindows 10のMS-IMEに付属するIMEパッドでUnicode文字を検索、入力しているところ。各面にどのような文字が定義されているかを簡単に知ることができる(「文字コード表」アプリはBMP面のUnicodeしか表示、入力できない)。BMPには現在よく使われる欧米圏のアルファベット類のほか、JIS X 0201/JIS X 0208(第1、第2水準漢字)、JIS X 0212(補助漢字)が含まれている。ほとんどの場合はこの面だけで足りるだろう。
CJK(Chinese、Japanese、Korean)統合漢字
CJK統合漢字とは、世界中の全ての文字コードを16bit幅に収容するために考案された、漢字文字の符号化方法である。
漢字文化圏(日本と中国、韓国。後にベトナム圏での漢字も含めることになる)で利用されている漢字は、現在利用されているものだけでも何万文字もある。そのため、各国が既に国内で利用していた漢字コードを全て合計すると、とても16bitには収容できない数に達していた。
そこでCJK統合漢字では、漢字をその形状に基づいて再分類し、同じ由来や形状の漢字は、1つだけ収容する、という方針を採用した。
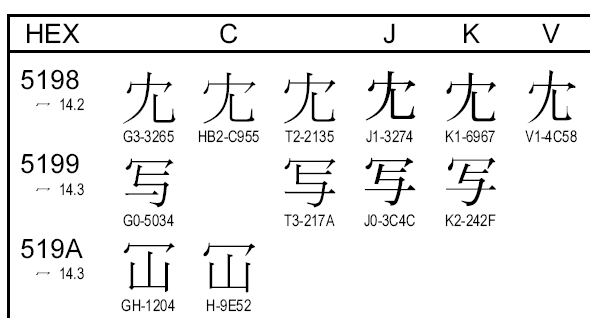 CJK/CJKV統合漢字の例
CJK/CJKV統合漢字の例統合漢字の例(Unicodeの仕様書より引用)。Cは中国、Jは日本、Kは韓国、Vはベトナム(漢越)でそれぞれ利用されている漢字。それを1つに統合している。国ごとに少しずつ書体が異なるものの(例:U+5199の「写」)、これは例示図形であり、書体/デザインの違いは文字コードでは関与しない、としている。日本語として正しく表示させるには、日本語向けのUnicodeフォントを利用する必要がある。Windowsでいうと、MS明朝なら上の「J0-3C4C」のように表示されるが、SimSunフォントなら「G0-5034」のように表示される。
CJK統合漢字を使うことにより、当初のUnicode規格では約2万の漢字を収容し、全体としては16bit内に納めることができた。だがその後、追加漢字面(SIP)にも新たに補助漢字を追加するなどした結果、現在ではトータルで約8万文字程度の漢字が収容されている。
なお、日中韓の漢字を統合したため、文字コードの順番は元のJIS規格とはかなり変わってしまっている。そのため単に文字コード順にソートしても、あまり意味のある結果は得られない。ソートするには、漢字とその読みを記録した補助的なデーターベースを利用するなどの工夫が必要になる。
サロゲートペア(代用対)
「サロゲートペア(代用対)」とは、Unicodeに第1面(SMP)以降を追加したときに導入された、新しい符号化方法である。16bit幅の文字コードを2つ使って、U+10000〜の文字を表現できるようにしている。
当初のUnicodeでは、文字コードを全て16bitで表現しており、1文字当たり16bit幅の変数が1つあればUnicode文字を収容できた。だがU+10000〜の文字コードではこれは不可能である。
そこで、16bit×2ペアで全ての文字コードを扱う方法が考案された。これがサロゲートペアである。BMPの未使用領域にあったコードの内、U+D800〜U+DBFF(1024文字分)とU+DC00〜U+DFFF(1024文字分)のペアを使って、1024×1024=約100万文字分のコード領域を確保し、これをU+10000〜U+10FFFFに割り当てることにしている。
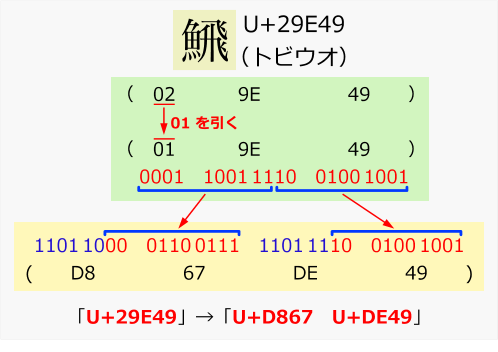 サロゲートペアの例
サロゲートペアの例「U+29E49」(「トビウオ」という漢字)というUnicode文字をサロゲートペアで表現した例。サロゲートペアに変換するには、まず文字コードからU+10000を減算して20bitの数値に変換する。それを上下10bitずつに分割し、それぞれの値をU+D800とU+DC00に加えるとサロゲートペアになる。
UnicodeのラウンドトリップとCJK互換漢字
CJK統合漢字には、その基となった各国別の文字コード規格があり、それらと相互変換できるようになっている。これをラウンドトリップ(往復変換)という(これができないと、既存のシステムとの相互データ交換が困難になる)。
だが元の規格自体のもつ曖昧性や規格制定時のミスなどにより、CJK統合漢字に収容されていない文字などが存在している。これを補助するために、幾つかの漢字をCJK互換漢字として収容している。CJK互換文字を経由することにより、確実にUnicodeと元の漢字コードとの間で相互変換ができるようになる。
結合文字
Unicodeでは、2つ以上のUnicode文字を組み合わせて1つの文字を表現する、「結合文字(combining character)」が利用できる。簡単なものでは、例えばドイツ語のウムラウトなどのように、母音の上に「¨」が付いた文字を作成する、といった用途に使用できる(ウムラウト付きの文字もすでに定義されているが)。日本語でも、「は」と「゛」で「ば」にする、といった使い方ができる(文字データとしては、Unicodeで2文字分を占有している)。言語によっては、前後に置かれる文字などによって全体の形状が大きく変わるものがあり、このような言語ではあらかじめ文字コードを多数定義しておくのは困難なので、結合によって文字を表現する。
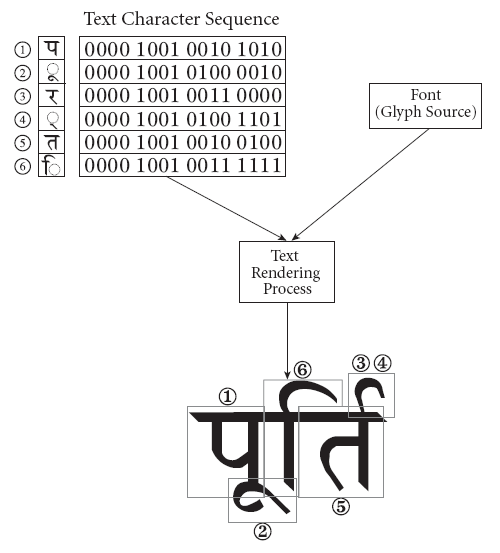 結合文字の例
結合文字の例これはデーヴァナーガリー文字を結合文字として表現している例。Unicodeの仕様書から引用。6つのUnicode文字を入力すると、最終的にはこのような文字が表示される。単純に左から右へ並んでいるというわけはなく、あらかじめフォントとして定義しておくのは難しい。
文字以外でも、例えば絵文字フォントにおいて、カラー属性を指定するために、この複数のUnicode文字を使って文字の修飾を表すことがある。
結合文字を利用すると、元のUnicodeにないさまざまな文字や記号などを表現できるが、システムやフォントによってはうまく扱えないこともある(例えば複数のUnicodeコードからなる文字をうまく編集できないなど)。また結合文字を使うと文字のソートなどが難しくなるので、基準となる文字だけを対象にしてソートする方法や、最初に「正規化」処理してからソートする方法なども規格で定義されている。
異体字セレクタ
例えば東京都「かつしかく」と奈良県「かつらぎし」のように、同じ漢字でも書体が異なるものがある(葛飾区の公式サイト『「葛」の字の不思議』、葛城市の公式サイト『「葛」の字について』参照)。これを異体字という。Unicodeやその基となっているJISコードでは、これらの異体字に同じ文字コードを割り当てているため区別できない。
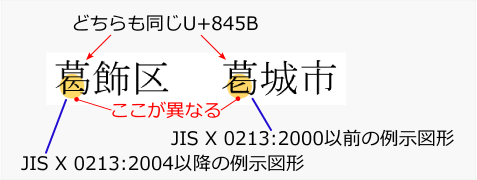 異体字の例
異体字の例U+845B(JISコードでは336B、Shift_JISでは8A8B)の文字には2つの異体字がある。それぞれの自治体は異なる字体を正式な書体/ロゴとしており、使用するシステムやフォントによって表示が変わってしまうという不都合に困惑している。
このような場合には、Unicodeでは「異体字セレクタ(Ideographic Variation Selector:IVS)」という値(漢字用はU+E0100〜U+E01EF)を該当する文字の直後に置くことによって、どの異体字を利用するかを選択できるようにしている。
 異体字のサポート
異体字のサポートUnicodeの符号化方式:UTF(UCS Transformation Format)
Unicode文字を符号化してストレージに格納したり、通信路を使って送受信したりするには、何らかの方法で、バイトストリーム(1byteごとのデータの並び)に変換する必要がある。Unicodeではこのための方法も規定しており、UTF-8やUTF-16、UTF-32などがある。これらについては、Tech Basics「UTF-8」を参照のこと。
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。