UTF-8:Tech Basics/Keyword
Unicodeのテキストをファイルに保存する場合、UTF-8という形式がよく使われる。システムのログや構成ファイル、XML/HTMLファイル、プログラムコードなど、UTF-8が使われる場面は非常に多い。UTF-8とは何か、どのような特徴を持つのかを解説。

「UTF-8」とは、Unicode文字の符号化(エンコード)方法の1つ。Unicodeの文字コード(コードポイント)を、1〜4bytesの可変長のバイトデータのストリームとして表現する方式である。Unicode文字列をファイルに保存したり、ネットワーク経由で送信したりする場合にはこのUTF-8がよく用いられる。近年では、HTMLコードやプログラムのソースコードなどをファイルに保存する場合は、このUTF-8形式を使うことが多い。
Unicode文字の符号化とは?
Unicodeは、世界中のさまざまな言語で使われる文字を、統一された固定長のコード(数値データ)で扱えるようにした文字コードセットである。文字に対して21bitの文字コードを割り当て、言語や国別にいちいち文字コードやフォントなどを切り替える必要がなく、全ての文字を同じように扱うことができる。Unicodeの概要については以下の解説を参照していただきたい。
- Tech Basics「Unicode」
Unicodeで定義されている文字には「U+0000〜U+10FFFF」(16進数表記)という文字コードが割り当てられているため、これをコンピュータのデータとして扱う場合は、通常は32bit(4bytes)の整数型が必要になる(16bitデータ×2で表現することもある。詳細は後述)。
またファイルに保存したり、ネットワークで通信したりする場合は、バイトデータに分解して1byteずつ順番に書き込んだり、送信したりする必要がある。
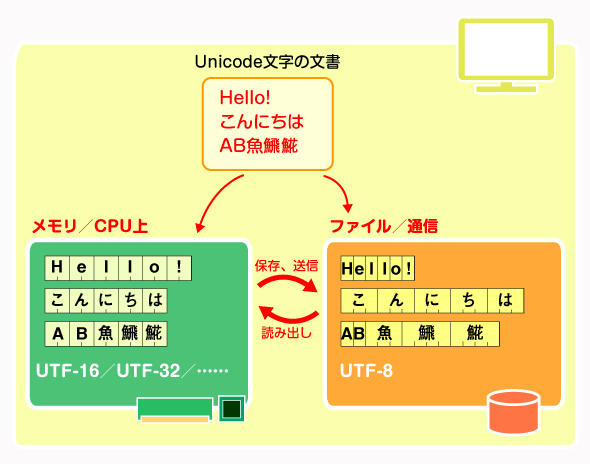 Unicode文字と符号化
Unicode文字と符号化Unicode文字は21bitのデータ幅があれば表現できるが、コンピュータ上では8bitや16bit、32bitのデータ型を使って処理される。一般的には、メモリ上では(プログラムコード上では)速度を重視して16bitか32bitの固定長データとして取り扱い、ファイルへの保存時や外部との通信時には、無駄な領域を省くために8bitの可変長型であるUTF-8形式が使われる事が多い。
このとき、4bytesもしくは2bytesのデータを、1byteずつのデータの並び(バイトストリーム)に変換することを「符号化(エンコード)」といい、その具体的な手順を符号化方法という(逆に、バイトストリームから元のUnicode文字に戻すことを「復号(デコード)」という)。
Unicodeの文字コードを単純に1byteずつに分割してファイルに保存したとすると、制御文字コードなどとバッティングして、元の文字に復元できなくなる。
例えば「U+300A」という文字(“』”)を単純に2つに分けると「U+0030(“0”)」と「U+000A(LF、改行記号)」になり、テキストエディタでは後者を単なる改行として扱ってしまう可能性がある。
このようなことが起こらないように、Unicodeではいくつかの符号化方法を決めており、その1つが「UTF-8」である。
Unicode文字を可変長バイトデータで表現するUTF-8
「UTF-8(Unicode Encoding Forms 8)」は、文字コードの値によって長さが1〜4bytesに変化する可変長の符号化方式である。これは既存のASCII文字(いわゆる半角文字)しか使えない通信路やシステムなどでも、大きな変更なしにそのまま使えるようにするためである。
●UTF-8の符号化の仕組み
UTF-8の仕様は、Unicodeの仕様書や以下のRFCなどで定義されている。
UTF-8では、Unicodeの文字コードの値に応じて次のように符号化する。
| Unicode文字コード | 符号化後のバイトストリーム(bit表現) |
|---|---|
| U+000000〜U+00007F | 0xxxxxxx |
| U+000080〜U+0007FF | 110xxxxx 10xxxxxx |
| U+000800〜U+00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| U+010000〜U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| Unicode文字のUTF-8符号化による表現 「x」は元の文字コード中のbitデータをそのまま埋め込むことを表す。UTF-8では文字コードに応じて符号化後の長さが変わり、よく使われる文字ほど短いデータになる。BMP面(U+0000〜U+FFFF)以外のUnicode文字は4bytesに変換される。符号化する場合は、一番短いデータになるようにすること。例えばU+0041(「A」)を2行目のルールを使って2bytesの「11000001 10000001」に変換してはいけない。 | |
●効率を高める工夫が施されているUTF-8の符号化方式
UTF-8による符号化の特徴は次の通りである
- 最も頻繁に使われるU+0000〜U+007Fの文字(ASCII文字/半角英数字)は1bytesに収まるようにして、コード効率を高くしている
- アルファベット圏でよく使われる文字範囲(U+0080〜U+07FF)は2bytesで済むので、やはりコード効率がよい
- 基本的な漢字文字はほぼBMP面(U+0000〜U+FFFF)に収容されているため、ほとんどの日本語文字は3bytesになる
- 符号化後のバイトデータの上位bitのパターンを見ると、どこがUnicode文字の先頭かすぐに分かる(上位bitが00か01か11なら文字の先頭バイト、10なら非先頭バイト)
最後の特長(最上位bitのパターンによるバイト位置の判定)は、Unicode文字を扱うプログラムを単純化して性能を高めるのに役立つ。例えばUnicode文字列を末尾から逆にスキャンして文字数を数えたり、処理したりする場合に便利である。Shift_JIS(主にDOSやWindows)やEUC(Extended UNIX Code、主にUNIX)では、バイトストリームの途中からスキャンを始めると文字の境界を正しく判定できないことがあり、処理が面倒になりがちであった。
UTF-8による符号化方法の例を次に示す。
 UTF-8による符号化方法の例
UTF-8による符号化方法の例これはU+611Bという漢字文字「愛」を、UTF-8に変換した例。16bitの文字コードを4bit/6bit/6bitの3つに分解し、3bytesのデータに変換している。
●U+010000〜U+10FFFFのUTF-8に未対応のシステムに注意
ところでU+010000〜U+10FFFFのUnicode文字をUTF-8で符号化すると、長さが4bytesになるが、システムやアプリケーションによってはこの4bytesになるUTF-8に対応していないことがある。その場合は、「サロゲートペア」で表現した2文字の16bit Unicodeをそれぞれ個別にUTF-8に変換して、最終的に3bytes×2=6bytesのデータにする。
このような符号化方式を「CESU-8(8-bit Compatibility Encoding Scheme for UTF-16)」といい、一部のシステムで使われている。ただし、この方法は現在では非推奨となっている。
Unicodeを固定長データとして符号化するUTF-16とUTF-32
UTF-8はファイルへの保存や通信などでは便利だし、メモリの利用効率も高いが、1byte単位の可変長データなのでプログラムから操作するには不便である。そこで「UTF-16」と「UTF-32」という符号化方法も用意されている。
●UTF-16
「UTF-16」はUnicode文字を16bitで表現する方式である(以前はUCS-2とも呼ばれていた)。U+0000〜U+FFFFの範囲ならそのまま16bitデータとして格納する。だがU+10000〜U+10FFFFの文字はサロゲートペアを使って表現する。
●UTF-32
「UTF-32」は、サロゲートペアを使わずに、常に32bitでUnicode文字を表現する方法である(以前はUCS-4とも呼ばれていた)。BMP面以外のUnicode文字が使われることは非常に少ないため、実際にはほとんどの場合は上位16bitがゼロになり、メモリの利用効率はあまりよくない。
その一方で処理が容易になるため、最近ではUTF-32を内部処理に使う言語処理系も増えている。
BOMによる、符号化方法とエンディアンの判別
●UTF-16/32で各バイトの並び順を意識しなければならない理由
UTF-16やUTF-32では、2bytesもしくは4bytesで1つの文字コードを表現している。このようなデータをメモリ上に格納したり、ファイルに保存したりする場合は、その「バイトオーダー(エンディアン)」属性について考慮する必要がある。
データの最上位バイトから順に格納する方式を「ビッグエンディアン(BE)」、最下位バイトから順に格納する方式を「リトルエンディアン(LE)」という。
例えば「U+29E49」(「魚」へんに「飛」で「トビウオ」)というUnicode文字を、UTF-32 BEでメモリに格納すると「00 02 9E 49」という順になる。これがUTF-32 LEだと「49 9E 02 00」となる。
これをそのままファイルに書き込めばUnicodeで記述されたテキストファイルになるが、これだけだと問題がある。次回ファイルを読み出すときに、どの文字コードや符号化方法、バイトオーダーでファイルに書き込まれているかが分からず、間違った方法でデータを解釈してしまう(文字化けする)可能性があるからだ。
●各バイトの並び順を示す「BOM」
そこで符号化方法を簡単に判別できるように、「BOM(Byte Order Mark)」と呼ばれる特別なUnicode文字をファイルの先頭に書きこんでおく方法がよく使われるようになった。
BOMとして使われるのは「U+FEFF」というUnicode文字である。これは、もともとは「zero width no-break space」(改行しない、表示幅ゼロの空白文字)という特別な制御文字であった。現在では、これをBOMとして利用することになっている。これに伴い、本来のU+FEFFの機能は「U+2060」(word joiner。改行しないという指定)を利用することになっている。
U+FEFFというBOMを、さまざまな符号化方法で表現すると次のようになる。
| 符号化方法 | バイトの並び |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 BE | FE FF |
| UTF-16 LE | FF FE |
| UTF-32 BE | 00 00 FE FF |
| UTF-32 LE | FF FE 00 00 |
| 「BOM(U+FEFF)」のさまざまな符号化表現 符号化の方法によって、同じU+FEFFという文字がさまざまな形式のバイトデータになる。ファイルの先頭にこのBOMを1つ入れておくことにより、符号化方式やバイトオーダーを簡単に判別できるようになる。 | |
BOMはオプション機能であり、場合によっては付けないこともあるが、UTF-8以外では付けておく方がトラブルになりにくい。またUTF-8はもともとバイトストリーム型の符号化方式なので、BOMがなくてもエンディアン間違いで文字化けすることはない。だが一般的にはUTF-8でもBOM付きでファイルを保存することが多い。
●BOMの実例
UTF-8形式(BOMあり)で保存したファイルの例を次に示す。
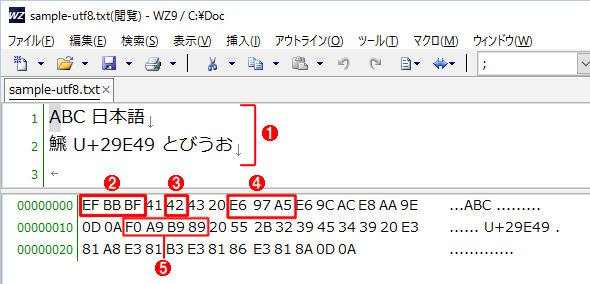 UTF-8で保存したファイルの内容例
UTF-8で保存したファイルの内容例メモ帳でUTF-8形式を指定して保存すると、先頭にBOMが付加される。これはそのファイル内容を16進数形式で表示したところ。
(1)入力したテキスト。
(2)UTF-8形式で符号化されたBOM。
(3)ASCII文字はそのまま出力される。
(4)BMP面の漢字文字は3bytesに符号化される。
(5)U+10000以上の漢字文字は4bytesに符号化される。
メモ帳で利用できるUnicodeの符号化方法
Windows OSの標準テキストエディタであるメモ帳には、Unicodeでテキストを保存する機能がある。だが上で解説した全ての符号化方法がサポートされているわけではない。このように、サポートされている符号化方法やBOMの有無などはソフトウェアによって変わる。
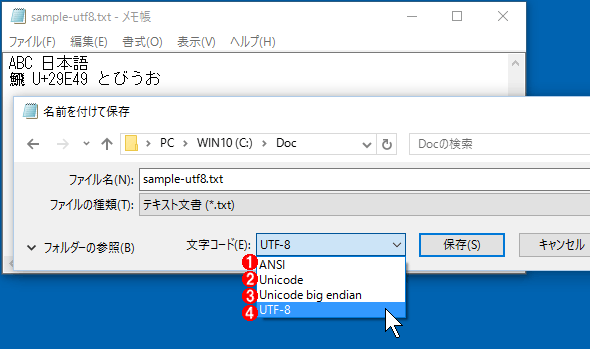 メモ帳のUnicodeサポート
メモ帳のUnicodeサポートメモ帳でもUnicodeで保存できるが、符号化の指定方法が分かりづらい。デフォルトでは「ANSI」になっている。
(1)ANSI/Shift_JISコードによる保存。BOMなし。ANSI/Shift_JISで表現できないUnicode文字が含まれていると、保存時に警告が表示される。
(2)UTF-16 LEによる保存。BOMあり。U+10000〜U+10FFFFはサロゲートペアで表現される。
(3)UTF-16 BEによる保存。BOMあり。U+10000〜U+10FFFFはサロゲートペアで表現される。
(4)UTF-8による保存。BOMあり。U+10000〜U+10FFFFはサロゲートペアでなく、正しく4bytesのUTF-8による符号化が行われる。
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。