Spark 2.0偺夞婣暘愅傾僾儕傪Scala偺SBT偱幚憰偟丄EMR偱幚峴丗Amazon EMR偱峔抸偡傞Apache Spark挻擖栧乮2乯乮2/3 儁乕僕乯
儊僀儞偲側傞幚憰僼傽僀儖傪婰弎偡傞
丂儊僀儞偲側傞幚憰僼傽僀儖偼丄乽src/main/scala/乿埲壓偵彂偄偰偄偒傑偡丅崱夞偼丄乽SparkExampleApp.scala乿偲偄偆僼傽僀儖傪嶌偭偰張棟傪婰弎偟偰偄偒傑偡丅
丂SparkExampleApp.scala傪嶌惉偟偰壓婰偺傛偆偵曇廤偟偰偔偩偝偄丅
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.feature._
import org.apache.spark.ml.regression.LinearRegression
object SparkExampleApp {
def main(args: Array[String]) {
// SparkSession僆僽僕僃僋僩偺嶌惉
val spark = SparkSession
.builder()
.appName("Spark Sample App")
.getOrCreate()
import spark.implicits._ // 僨乕僞僼儗乕儉傪埖偆偨傔偺偍傑偠側偄
// 偙偺屻偵張棟傪彂偄偰偄偒傑偡丅
}
}
丂忋婰偺僐乕僪偺夝愢偱偡丅
丂1乣4峴栚偱偼昁梫側僷僢働乕僕傪import偟偰偄傑偡丅
Spark 2偺SparkSession僆僽僕僃僋僩傪嶌惉
丂師偵丄SparkExampleApp偲偄偆僔儞僌儖僩儞僆僽僕僃僋僩傪掕媊偟偰乮6乣20峴栚乯丄偦偺拞偺main儊僜僢僪撪偵傾僾儕働乕僔儑儞偺張棟傪婰弎偟偰偄傑偡乮8乣19峴栚乯丅
丂main儊僜僢僪撪偱偼丄傑偢丄Spark 2.0.0偐傜捛壛偝傟偨SparkSession僆僽僕僃僋僩傪嶌惉偟偰偄傑偡丅偙偺僆僽僕僃僋僩傪捠偟偰丄僨乕僞偺張棟偑峴偊傑偡丅惗惉帪偵偼丄儊僜僢僪僠僃乕儞偱Session偺愝掕傪婰弎偱偒傑偡丅崱夞偼AppName儊僜僢僪偱傾僾儕働乕僔儑儞偺柤慜傪巜掕偟偰偄傑偡乮10乣13峴栚乯丅
丂懠偵傕偄傠偄傠巜掕偱偒傑偡偑丄幚峴帪偵捈愙巜掕偟偨傝config僼傽僀儖偵暿搑婰弎偟偨傝偡傞偙偲傕偱偒傞偺偱丄偦偪傜偺曽偑曋棙偱偡丅偦偺偨傔昅幰偼丄偙偙偱偼娙寜偵彂偔傛偆偵偟偰偄傑偡丅
丂15峴栚偱乽import spark.implicits._乿偲偄偆婰弎偑偁傝傑偡偑丄偙傟偼乽僨乕僞僼儗乕儉乿傪埖偆偨傔偺婰弎偱偡丅崱夞梡偄傞乽spark.ml乿偲偄偆婡夿妛廗偺僷僢働乕僕偼丄僨乕僞僼儗乕儉傪埖偆偺偱昁梫偵側傝傑偡丅
僨乕僞僼儗乕儉偲偼
丂娙扨偵愢柧偡傞偲丄慜夞愢柧偟偨乽RDD乮Resilient Distributed Dataset乯乿傪傛傝曋棙偟偨傕偺偱丄傛傝捈姶揑偵僨乕僞傪埖偊傞巇慻傒偱偡丅
丂SQL儔僀僋偵僨乕僞傪庢摼偱偒傞崅儗儀儖側API偑偦傠偭偰偄傞偺偱丄娙寜偵傛傝抁偄僐乕僪偱幚憰偟偰偄偔偙偲偑壜擻偱偡丅傑偨丄張棟偺嵟揔壔傕峴傢傟偰偄傑偡丅偦偺偨傔丄捈愙RDD傪埖偆傛傝傕儊儕僢僩偑偁傝傑偡丅
spark.ml傪娷傓乽MLLib乿偵偮偄偰
丂Spark偵偼乽MLlib乿偲偄偆婡夿妛廗偺僷僢働乕僕偑偁傝傑偡丅夞婣傗暘椶丄僋儔僗僞儕儞僌偲婎杮揑側傾儖僑儕僘儉傪旛偊偰偄傑偡丅
丂MLlib偵偼RDD儀乕僗乮spark.mllib乯偲DataFrame儀乕僗乮spark.ml乯偺2偮偑偁傝傑偡丅慜幰偼Spark 2.0.0偐傜儊儞僥僫儞僗儌乕僪偲側傝傑偟偨丅側偺偱丄spark.ml傪巊偆偙偲傪悇彠偝傟偰偄傑偡丅崱夞偼屻幰偺曽傪巊偭偰偄偒傑偡丅
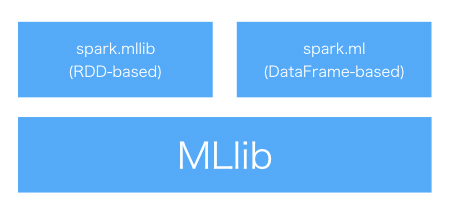 MLlib偺峔惉
MLlib偺峔惉AWS傊偺愙懕偲csv偐傜僨乕僞傪撉傒崬傓僨乕僞僼儗乕儉偺嶌惉
丂幚憰偺夝愢偵栠傝傑偡丅懕偗偰丄愭傎偳偺僐乕僪偺main儊僜僢僪撪偺17峴栚偵壓婰偺僐乕僪傪彂偄偰偄偒傑偡丅
// AWS偺AccessKey偺愝掕
spark.sparkContext.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "*********")
spark.sparkContext.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "*********")
// csv偐傜僨乕僞傪撉傒崬傓僨乕僞僼儗乕儉偺嶌惉
val filePath = args(0)
val df = spark.sqlContext.read
.format("com.databricks.spark.csv") // 僨乕僞偺僼僅乕儅僢僩傪巜掕偟傑偡丅
.option("header", "true") // 僇儔儉柤傪僨乕僞僼儗乕儉偺僗僉乕儅偵斀塮偟傑偡丅
.option("inferSchema", "true") // 宆偺帺摦曄姺傕峴偄傑偡丅
.load(filePath)
丂傑偢丄S3傊傾僋僙僗偡傞偨傔偺AccessKeyId傪愝掕偟偰偄傑偡乮1乣3峴栚乯丅偙偪傜偼奺帺偺娐嫬偵崌傢偣偰愝掕偟偰偔偩偝偄丅
丂師偵丄S3忋偺csv僼傽僀儖傪撉傒崬傫偱僨乕僞僼儗乕儉傪嶌惉偟偰偄傑偡乮5乣11峴栚乯丅filePath偼傾僾儕働乕僔儑儞幚峴帪偵堷悢偱巜掕偡傞憐掕偱偡丅
僷僀僾儔僀儞僆僽僕僃僋僩傪嶌惉
丂懕偗偰丄壓婰偺僐乕僪傪彂偄偰偔偩偝偄丅
// Pipeline偺奺梫慺傪嶌惉
// 亂1亃慺惈偺儀僋僩儖傪惗惉偟傑偡
val assembler = new VectorAssembler()
.setInputCols(Array("x")) // 愢柧曄悢傪巜掕偟傑偡丅
.setOutputCol("features") // 曄姺屻偺抣傪features偲偄偆柤慜偱僨乕僞僼儗乕儉偵捛壛
// 亂2亃慺惈偺儀僋僩儖傪懡崁幃偵偟傑偡
val polynomialExpansion = new PolynomialExpansion()
.setInputCol(assembler.getOutputCol) // features偺暥帤楍偱偡丅
.setOutputCol("polyFeatures") // 曄姺屻偺抣傪polyFeatures偲偄偆柤慜偱僨乕僞僼儗乕儉偵捛壛
.setDegree(4) // 4師偺懡崁幃偱偡丅
// 亂3亃慄宍夞婣偺梊應婍傪巜掕偟傑偡
val linearRegression = new LinearRegression()
.setLabelCol("y") // 栚揑曄悢偱偡丅
.setFeaturesCol(polynomialExpansion.getOutputCol) // polyFeatures偺暥帤楍偱偡丅
.setMaxIter(100) // 孞傝曉偟偑100夞
.setRegParam(0.0) // 惓懃壔僷儔儊乕僞
// 亂1亃乣亂3亃傪尦偵僷僀僾儔僀儞僆僽僕僃僋僩傪嶌傝傑偡
val pipeline = new Pipeline()
.setStages(Array(assembler, polynomialExpansion, linearRegression))
丂忋婰偼僷僀僾儔僀儞僆僽僕僃僋僩傪惗惉偟偰偄傑偡丅
乽Pipeline乿偲偼
丂Pipeline偼僨乕僞偺惍宍偐傜梊應儌僨儖偺惗惉傑偱偺堦楢偺張棟傪丄娙寜偵彂偔偙偲偑偱偒傞巇慻傒偱偡丅
丂Pipeline偺僐儞億乕僱儞僩偼乽曄姺婍乿乽梊應婍乿偺2偮偱峔惉偝傟偰偄傑偡丅曄姺婍傪巊偭偰僨乕僞傪惍宍偟丄偦傟傪尦偵梊應婍偱儌僨儖傪嶌惉偟傑偡丅
- 曄姺婍乮Transformer乯
僨乕僞僼儗乕儉傪暘愅壜擻側抣偵曄姺偱偒傞丅椺偊偽丄暋悢偺僗僇儔乕抣偐傜儀僋僩儖僆僽僕僃僋僩傊偺曄姺丄宍懺慺夝愅丄暥帤悢僇僂儞僩側偳偑壜擻 - 梊應婍乮Estimator乯
儘僕僗僥傿僢僋夞婣側偳偺暘椶丄夞婣暘愅側偳偺悇掕丄僋儔僗僞儕儞僌側偳偑偱偒傞
丂忋婰僐乕僪偺夝愢偵栠傝傑偡丅
丂傑偢丄僐乕僪撪偺亂1亃偺晹暘偱偼丄csv僨乕僞偺拞偐傜暘愅偵巊偆僇儔儉傪巜掕偟偰偄傑偡丅
// 亂1亃慺惈偺儀僋僩儖傪惗惉偟傑偡
val assembler = new VectorAssembler()
.setInputCols(Array("x")) // 愢柧曄悢傪巜掕偟傑偡丅
.setOutputCol("features") // 曄姺屻偺抣傪features偲偄偆柤慜偱僨乕僞僼儗乕儉偵捛壛
丂崱夞偼丄愢柧曄悢偑1偮側偺偱丄x僇儔儉偩偗傪巜掕偟偰偄傑偡偑丄傕偟懡曄検偺暘愅偑偟偨偄応崌偼setInputCols(Array("x1", "x2", "x3", "x4"))側偳偺傛偆偵暋悢巜掕偡傞偙偲傕偱偒傑偡丅
丂師偵丄僐乕僪撪偺亂2亃偱偼丄忋偱巜掕偟偨僇儔儉乽x乿偺抣傪4師偺懡崁幃壔偟偰偄傑偡丅
// 亂2亃慺惈偺儀僋僩儖傪懡崁幃偵偟傑偡
val polynomialExpansion = new PolynomialExpansion()
.setInputCol(assembler.getOutputCol) // features偺暥帤楍偱偡丅
.setOutputCol("polyFeatures") // 曄姺屻偺抣傪polyFeatures偲偄偆柤慜偱僨乕僞僼儗乕儉偵捛壛
.setDegree(4) // 4師偺懡崁幃偱偡丅
丂嬶懱揑偵偼丄僇儔儉乽x乿傪僀儞僾僢僩偵偟偰丄(x, x^2, x^3, x^4)偺儀僋僩儖傪乽polyFeatures乿偲偄偆怴偟偄僇儔儉偵僙僢僩偟偰偄傑偡丅
丂僐乕僪撪偺亂3亃偱偼梊應婍偵偮偄偰掕媊偟偰偄傑偡丅愭傎偳惗惉偟偨儀僋僩儖傪愢柧曄悢偵丄僨乕僞僼儗乕儉乮偮傑傝csv撪乯偺僇儔儉乽y乿傪栚揑曄悢偲偟偰妛廗儌僨儖傪嶌傝傑偡丅
// 3. 慄宍夞婣偺梊應婍傪巜掕偟傑偡
val linearRegression = new LinearRegression()
.setLabelCol("y") // 栚揑曄悢偱偡丅
.setFeaturesCol(polynomialExpansion.getOutputCol) // polyFeatures偺暥帤楍偱偡丅
.setMaxIter(100) // 孞傝曉偟偑100夞
.setRegParam(0.0) // 惓懃壔僷儔儊乕僞
丂崱夞偼丄孞傝曉偟夞悢傪乽100乿偵丄惓懃壔僷儔儊乕僞乮setRegParam乯傪乽0.0乿偵巜掕偟偰惓懃壔偼乽側偟乿偵愝掕偟偰偄傑偡丅
丂僷儔儊乕僞偺愝掕偼儌僨儖偺嶌惉偵偍偄偰廳梫偱偡丅
丂孞傝曉偟夞悢偼戝偒偔愝掕偡傟偽偡傞傎偳丄惛搙偺岦忋偑婜懸偱偒傑偡偑丄寁嶼帪娫偑憹偊偰偟傑偄傑偡丅傑偨丄惓懃壔僷儔儊乕僞偼丄戝偒偔偡傟偽偡傞傎偳儌僨儖偺暋嶨偝傪夝徚偱偒傑偡偑丄戝偒偔偟夁偓傞偲丄慺惈偺岠壥偑敄傟夁偓偰偟傑偄傑偡丅
丂偙傟傜偺僷儔儊乕僞偼嵟揔側抣傪愝掕偡傞昁梫偑偁傝傑偡丅嵟揔側抣傪媮傔傞曽朄偲偟偰乽僌儕僢僪僒乕僠乿偑偁傝傑偡偑丄Spark偱偼偦傟傕娙扨偵偱偒傑偡乮師夞埲崀偵愢柧偡傞梊掕偱偡乯丅
丂嵟屻偵丄pipeline僆僽僕僃僋僩傪嶌惉偟偰偄傑偡丅曄姺婍傗梊應婍偑僗僥乕僕偛偲偵張棟偝傟傞傛偆偵丄setStage儊僜僢僪偱偦傟傜傪巜掕偟偰偄傑偡丅
僨乕僞偺巜掕偲幚峴寢壥偺曐懚
丂懕偗偰丄壓婰偺僐乕僪傪彂偒傑偡丅
val Array(trainingData, testData) = df.randomSplit(Array(0.7, 0.3))
val model = pipeline.fit(trainingData) // 妛廗僨乕僞傪巜掕偟傑偡丅
// csv偵曐懚
val outputFilePath = args(1)
model.transform(testData) // 僥僗僩僨乕僞傪巜掕偟傑偡
.select("x", "prediction")
.write
.format("com.databricks.spark.csv") // 僨乕僞偺僼僅乕儅僢僩傪巜掕偟傑偡丅
.option("header", "false") // 僿僢僟乕偵僇儔儉柤傪偮偗傞偐
.save(outputFilePath) // 僼傽僀儖偺曐懚愭偱偡丅
丂傑偢丄嵟弶偵惗惉偟偨僨乕僞僼儗乕儉傪妛廗梡偲僥僗僩梡偵暘偗偰偄傑偡丅師偵丄pipleline僆僽僕僃僋僩偐傜儌僨儖傪嶌惉偟偰偄傑偡丅偦偟偰丄偦偺儌僨儖傪尦偵僥僗僩梡僨乕僞偺曄姺乮梊應乯傪峴偄丄csv偲偟偰彂偒崬傒傑偡丅
SparkExampleApp.scala偺姰惉僐乕僪
丂姰惉偡傞偲壓婰偺傛偆側僐乕僪偵側偭偰偄傞偐偲巚偄傑偡丅GitHub偵忋偘偰偍偒傑偟偨丅
娭楢婰帠
 抦傜側偄偲戝懝偡傞丄Apache Spark偺婎慴抦幆偲3偮偺儊儕僢僩
抦傜側偄偲戝懝偡傞丄Apache Spark偺婎慴抦幆偲3偮偺儊儕僢僩
幮夛堦斒偐傜戝偒側拲栚傪廤傔偰偄傞IoT乮Internet of Things乯丅偩偑丄偦偺嬶懱憸偼傑偩怹摟偟偰偄傞偲偼偄偊側偄丅崱夞偼丄IoT傗價僢僌僨乕僞偺僉乕僥僋僲儘僕偲偟偰拲栚偝傟偰偄傞乽Apache Spark乿偵偮偄偰丄Spark傪惢昳偵庢傝崬傫偱偄傞擔杮IBM偺搚壆撝巵偲丄悢懡偔偺婇嬈偺僨乕僞暘愅傪扴偆僽儗僀儞僷僢僪偺壓揷椣戝巵偵榖傪偆偐偑偭偨丅 Spark偺僄儞僞乕僾儔僀僘懳墳偑乽惉弉乿乗乗Cloudera偑愰尵
Spark偺僄儞僞乕僾儔僀僘懳墳偑乽惉弉乿乗乗Cloudera偑愰尵
Hadoop僨傿僗僩儕價儏乕僞乕傕偁傜偨傔偰Spark傊偺拲椡傪傾僺乕儖丅婛偵800僲乕僪挻偺Spark僋儔僗僞乕傪塣梡偡傞儐乕僓乕傕懚嵼偡傞偲偄偆丅 Spark偼乬扤乭偵椺偊傜傟傞丠劅劅懡條壔偲恑壔傪懕偗傞乽Hadoop乿丄恖婥媫忋徃乽Spark乿
Spark偼乬扤乭偵椺偊傜傟傞丠劅劅懡條壔偲恑壔傪懕偗傞乽Hadoop乿丄恖婥媫忋徃乽Spark乿
愭擔丄擔杮Hadoop儐乕僓乕夛庡嵜偺僀儀儞僩偑奐嵜偝傟傑偟偨丅僨乕僞儀乕僗偲娭學惈偑怺偄僨乕僞暘嶶張棟僾儔僢僩僼僅乕儉偱偁傞乽Hadoop乿偲乽Spark乿偺嵟嬤帠忣偵敆傝傑偡丅
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅