LSTMとResidual Learningでも難しい「助詞の検出」精度を改善した探索アルゴリズムとは:Deep Learningで始める文書解析入門(終)(1/2 ページ)
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。今回は、Long Short Term MemoryとResidual Learningの概要、「助詞の検出」精度を改善した探索アルゴリズムについて。
日本語は「助詞の識別」が極めて困難
本連載「Deep Learningで始める文書解析入門」では、Deep Learningの中でも時系列データを扱う「Recurrent Neural Network」(以下、RNN)と、その応用方法としてリクルートグループ内で取り組んでいる原稿校正(誤字脱字の検知)の実現方法について解説してきました。
連載第1回ではRNNの概要や活用例について述べ、第2回の前回では、「誤字脱字の検知」というタスクの概要を紹介し、それに対してRNNをどのように活用したかを紹介しました。
前回の最後でも述べましたが、誤字脱字の検知という課題に対して始めからRNNがうまく機能したかというと、答えは「ノー」です。「文字の系列から次の単語を予測するRNNを“異常検知”的に利用する」こと自体は、うまく機能しているようでした。
しかし、英語に比べ日本語の文法は思った以上に複雑で、特に、前回『「誤字脱字」の3つの定義』の1つとした「助詞の識別」は困難を極めました。また、助詞以外では、名詞において、「その単語数の多さから誤った検出をしてしまう」などの問題がありました。第3回となる今回は、それらの課題を乗り越えるために行った精度向上の工夫を紹介します。
RNNを発展させた「Long Short Term Memory」とは
そもそも、これまでの連載で「今回のタスクに用いていたのはRNNだ」と繰り返してきましたが、厳密には、連載第1回でも触れたように、RNNを発展させた「Long Short Term Memory」(以下、LSTM)を使用しています。LSTMもRNNの一種なので、インプット(入力層)となるデータやアウトプット(出力層)の目的は変わりません。
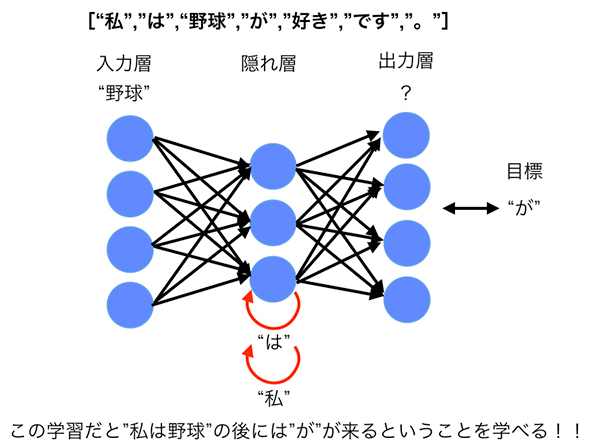 RNNによる学習(連載第1回の図4の再掲)
RNNによる学習(連載第1回の図4の再掲)LSTMとRNNの違いには、「勾配消失問題」があります。これについて、詳説します。
RNNにおける勾配消失問題
ニューラルネットワークでは「重みの更新」に「誤差逆伝播法(Back Propagation)」という、入力層からではなく、出力層からさかのぼって誤差を伝播(でんぱ)するアルゴリズムを用います。特にRNNでは、「重みの更新」に時間の概念が加わることで正確な“勾配”を利用する「Back Propagation Through Time」(以下、BPTT)を用います。
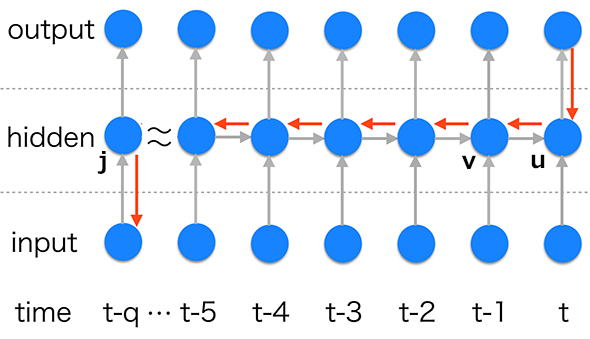 図1 RNNにおけるBPTT
図1 RNNにおけるBPTTRNNでは、時刻「t」の中間層(隠れ層:図1のhidden)ユニット「u」の重み計算の際に、時刻「t-1」の中間層ユニット「v」を利用するようなモデルになっています。このとき、時刻「t-1」の中間層ユニット「v」の重みを更新するためには、時刻「t」の中間層ユニット「u」での誤差が伝播される必要があります。これが1つの連鎖分であれば問題ないですが、時刻「t-1」のユニット「v」は時刻「t-2」のユニットを利用しており、さらにそのユニットは時刻「t-3」の……というようにどんどん深いネットワークを形成しています。そのため、時刻「t」の中間層ユニット「u」で発生した誤差を時刻「t-q」の中間層ユニット「j」にまで伝播させる必要が出てきます。
このように、「t」から「t-q」のユニットにたどり着くまでにq回の“勾配”計算があるため、「q」の値が大きいと、「t-q」の中間層ユニット「j」にたどり着く誤差が非常に不安定になります。これが「勾配消失問題」と呼ばれています。
人間の脳の仕組みと似ている「input gate」と「output gate」
この問題を解決するための構造の1つがLSTMです。LSTMは、1997年にSepp Hochreiter氏とJurgen Schmidhuber氏によって提案されました(参考PDF)。
その後、LSTMにはさまざまな派生構造が発表されていますが、今回は1997年に発表されたオリジナルの構造を図2に記載します。LSTMはRNNの中間層ユニットに組み込まれる1つのブロックのようなものだと考えてください。
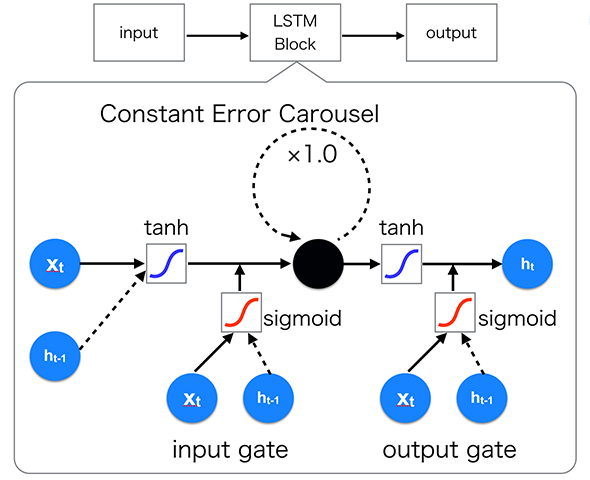 図2 Long Short Term Memoryの構造
図2 Long Short Term Memoryの構造ここで重要となるのは、「input gate」「output gate」と呼ばれる2つのゲートと「Constant Error Carousel」(以下、CEC)の存在です。CECについての詳細を書くとかなり専門的になってしまうので省略しますが、CECは前述した勾配消失問題を解決するために「誤差の不安定性を調節する役割を担っている」とだけ覚えておいてください。
「input gate」「output gate」は、“必要な誤差信号だけを伝播させる”ように入力と出力を制限する役割を果たしています。これは人間の脳の仕組みと極めて似ています。人間の脳は、普段の暮らしの中で触れるあらゆる情報を全て保存することはせず、自分が必要とする情報を取捨選択して保存をしています。上記の2つのゲートは、「情報の取捨選択」の役割を果たしていると考えてください(実際には、この2つのゲートの他に、もう1つ「Forget gate」と呼ばれるゲートが存在しているモデルが主流です)。
LSTMはPythonライブラリ「chainer」を利用すると簡単
このようにRNNの問題点を解決するLSTMですが、実際に逆伝播の計算を追おうとするとなかなか大変です。しかし、今回筆者が利用しているPythonのライブラリである「chainer」を利用すると簡単に実装が可能となります。
画像認識イベントで大きな成果を上げた「Deep Residual Learning」の導入
さらに、今回の校正のタスクにおいては、「Deep Residual Learning」を取り入れることで、精度の向上が見られました。
もともと、Deep Neural Network(DNN:多層構造のニューラルネットワーク)においては、「より層を増やせば増やすほど精度が向上するわけではない」ということが共通認識的に大きな問題とされてきました。
特にRNNにおいては、時系列方向への伝播などがあるため、一見少ない層構造に見えても時系列の長さが長ければ長いほど、実際としてはかなり深い層数となっていると考えることができます。「層数が多い場合は学習が非常に困難になり、かえって精度が悪くなる」などの問題が起きていました。
そこで登場したのが、「Deep Residual Learning」(深層残差学習:ResNet)と呼ばれるモデルです(図3)。Deep Residual Learningでは、ある隠れ層の出力に、その層の入力をそのまま加算します。
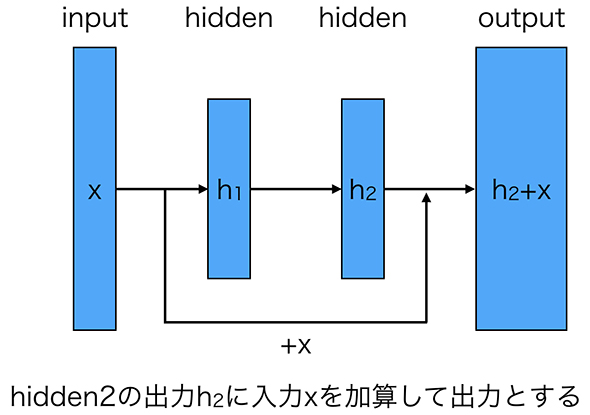 図3 Deep Residual Learningのネットワーク構造
図3 Deep Residual Learningのネットワーク構造これは、これまでの「深い層を持つネットワークにおいては、余分なレイヤをスルーするような学習をすることが難しい」という問題に対して有効な解決策となりました。このモデルは、「ILSVRC(Large Scale Visual Recognition Challenge) 2015」というイベントで152の深い層を持ちながらも、ImageNetのテストセットに対し、2位以下を大きく突き放す精度を誇り優勝しました。
関連記事
 「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか。GPUコンピューティングを推進するNVIDIAが、これらの違いを背景および技術的要素で解説した。 AlpacaDBがDeep Learningを使った自動取引アプリを公開
AlpacaDBがDeep Learningを使った自動取引アプリを公開
米AlpacaDBは、為替市場での自動取引アルゴリズムを設計できるiPhone向けモバイルアプリ「Capitalico(キャピタリコ)」の提供を開始した。 2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
人気連載を1冊にまとめてダウンロードできる@ITの電子書籍。第16弾は、「いまさら聞けないDeep Learning超入門」だ。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。