「Deep Learningをサービスに導入したい!」人が泣かないために知っておきたいこと:機械学習活用プロジェクト大解剖(1)(1/2 ページ)
サイト内検索のランキングアルゴリズムに機械学習を活用した事例を通じて、Deep Learningをはじめとした機械学習の強みと限界を探る連載。
機械学習活用に求められるスキル・環境とは何なのか
本連載「機械学習活用プロジェクト大解剖」では、リクルートテクノロジーズにおける「サイト内検索改善」プロジェクトの事例を紹介します。このプロジェクトは、機械学習を導入するために、分析担当者にとって仕事がしやすい環境を構築したものです。
本連載では、このプロジェクトを通じて得た気付きである「機械学習活用に求められるスキル・環境とは何なのか」をテーマに、「検索のランキングアルゴリズムを継続的に改善するためのTips」「統計学や機械学習の知見をどのように活用したのか」「検索の改善に重要な機械学習以外の方法」などについてお伝えします。
一方で、統計学や機械学習の理論、ミドルウェアやツールの使い方、検索エンジン全体のアーキテクチャや開発体制・監視の仕組みは、本連載ではお伝えしません。検索エンジン全体のアーキテクチャや開発体制・監視の仕組みについては、連載「Elasticsearch+Hadoopベースの大規模検索基盤大解剖」を参考にしてください。
また、本連載で紹介する事例のオチを先に書いておきます。
- 「Deep Learningを使ってみたい」という、趣味優先のプロジェクトがスタート
- Deep Learningそれ自体よりも、実際にサービス導入するためのいろいろな準備の方がサービス改善効果が大きかった
- ただ使いたかっただけのDeep Learningよりも、サービス改善に本当に重要だったことが見えた(なので後悔はない)
本連載は、検索ランキング改善や機械学習プロジェクトの立ち上げ期の話です。そのため、既にそのようなプロジェクトを無事立ち上げられた方よりも、下記のような方々に、少しでも参考になれば幸いです。
- 「サービスの検索機能を改善したい」が、方法が分からない方
- 「プロジェクトにDeep Learningが使えるか」を検証してみたい方
- 自分でDeep Learningなど、はやりの機械学習をサービスに導入しようとしている方
まず、先ほど紹介した連載「Elasticsearch+Hadoopベースの大規模検索基盤大解剖」では軽く触れるだけにとどめた「QueryRewriter」を紹介します。このQueryRewriterの検索を改善したのが、本連載で紹介するプロジェクト施策の中枢です。
検索改善のためのアーキテクチャ
リクルートテクノロジーズはリクルートグループ各社が運営するサービスに「Qass(Query analyze search system)」と呼ぶ検索改善基盤を提供しながら、サービス運用者と一体となってサイト内検索機能の継続的改善を行っています。
われわれのチームでは、検索ランキングアルゴリズム改善に「QueryRewriter」と呼ぶツールを利用しています。このQueryRewriterを導入することで、10年以上安定稼働している数々のWebサービスに対して、既存比で検索導線由来のCVRを数十%も改善できました。2017年1月現在の本稿執筆時点でも改善を続けています。
Apache Solrの検索クエリをリライトしてUXを高める
QueryRewriterは名前の通り、検索クエリをリライトすることが主な仕事です。つまり、WebサービスからのApache Solr(以下、Solr)検索クエリを途中で書き換えてカスタマー(本連載では、リクルートグループのサービスを使うエンドユーザーのことを指します)にとって良い検索結果を返すことを目的としています。QueryRewriterは、小さなフットプリントと高パフォーマンスを実現するGo言語で開発しています。
QueryRewriterでは、ユーザー属性やフリーワードからインテントを推定しています。具体的には、検索フィールドのブースト値を調整したり、FunctionQueryをアドインしたりしてクエリを書き換え、動的なランキングアルゴリズムを実現しています。それ以外にも、QueryRewriterには以下の特徴があります。
- 安定稼働中のサービスへの導入を念頭においた、プロキシ型アーキテクチャ
- 高速なA/Bテスト実現する、無停止更新機能
- 検索結果比較機能
ここから、これらの特徴をどのように実現しているかを紹介します。
安定稼働中のサービスへの変更を最小限にするアーキテクチャ
リクルートグループのサービスにおいて、多くのユーザーが利用するサイト内検索機能はマッチングビジネスのビジネスモデルの根幹に関わる重要機能です。
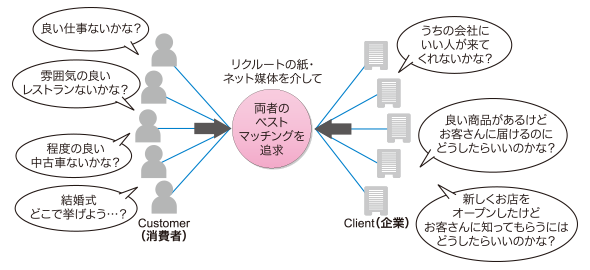 リクルートのビジネスモデル(記事「Elasticsearch+Hadoopベースの大規模検索基盤大解剖(1):リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか」から引用)
リクルートのビジネスモデル(記事「Elasticsearch+Hadoopベースの大規模検索基盤大解剖(1):リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか」から引用)そのため検索機能の改修には、パフォーマンスや検索結果の劣化、バグによる検索機能の停止などが起こらないように、改修の影響が広ければ広いほど手厚いテストが必要になってきます。
そんな重要機能への改修の影響を最小限とするために、QueryRewriterは既存アプリケーションサーバと検索サーバの間に差し込んでSolrのリバースプロキシとして動作するように設計しています。つまり、アプリケーションから見るとSolrと全く同じインタフェースで透過的に動作するようにしています。これで、Webアプリケーション側は検索サーバに投げるクエリを全く変更せず、ただ接続先を変更するだけで利用できるようにしています。また、これによってWebアプリケーション側の改修の影響範囲が限定されるため、テスト工数が低くなり、イニシャルコストを抑えることができます。

このような既存の検索サーバへのリバースプロキシ側アーキテクチャを採用することで、万が一QueryRewriterにバグがあって停止した場合でも、LB(Load Balancer)に死活監視とフェイルオーバーの責務を持たせることで、すぐにQueryRewriterを介さないSolr直接検索方式への切り戻しを可能にしています。この仕組みにより、検索アルゴリズム開発者が既存と同等のサービスレベルを保ったまま、思い切って複雑な検索アルゴリズムを導入することが可能となっています。

高速なA/Bテストを可能にするアーキテクチャ
検索改善の効果を定量的に評価するためには、A/Bテストによるオンラインテストが重要な位置を占めます。また効率が良いオンラインテストを実施するためには、数日〜数週間単位での検索ロジックの差し替えができることが望ましいです。
ただし、多くのカスタマーが利用しているWebサービスでは、サービス停止は大きな機会損失を生みます。よって、頻繁に検索アルゴリズムを改修するには、サービスを停止させずに検索アルゴリズムだけを差し替える仕組みが必要です。
QueryRewriterは「クエリを高速にさばくためのフロント機能」と「クエリを書き換えるためのロジックモジュール」を分離し、ロジックモジュールをサービス停止なしで更新する機能を持たせています。つまり、「Solrクエリをさばく処理」のように「稼働中にあまり変更しない部分」と「頻繁に変更するロジックの部分」を分離しています。
さらにロジック内でも、ランキングアルゴリズム部分は別設定ファイルに外部化し、設定ファイルの変更だけでアルゴリズムの変更ができるようにしています。

この特徴により、「検索改善のための分析者が分析に集中し改善ロジックの開発のみに集中できる」という利点を実現しています。ロジックモジュール内部で複数のランキングアルゴリズムを管理しているため、複数のランキングアルゴリズムを並列に競わせてA/Bテストを実現できます。
検索結果比較機能
また、QueryRewriterと組み合わせて使う、「GABU」とわれわれが呼んでいる検索結果比較ツールも重要な意味を持っています。
GABUを用いることで、分析者は「自らが開発したランキングアルゴリズムが、実際にどのような検索結果ランキングになるか」を可視化しているため、「既存のランキングアルゴリズムと新しいランキングアルゴリズムの挙動を実際にユーザーが体験する」のと近い形で即座に比較できるようにしています。

この結果、機械学習で構築したロジックを人間の感性でも確認できます。GABUを用いることで、もろもろの事情で機械学習だけに任せにくい要素でのアドホックなチューニングも円滑に行えます。
またGABUは、分析担当者だけが利用するものではありません。特に威力を発揮するのが、企画・営業部署など開発・分析を専門外としている部署の人とのコミュニケーション時です。安定運用中のシステムにおいては、ステークホルダーが多く実サービスの検索結果に多くの方が強い関心を持っていることが多いため、複数の部署間でのコミュニケーションが重要になってきます。
GABUを用いることで、検索改善の結果比較を目で見える形でデモできます。この目に見える形でのデモを行うと、新しい検索ロジックで「改善されること」の実感を共有でき、複数の部署をまたいだプロジェクトを推進しやすくなります。
以上が、本連載で紹介するプロジェクト施策の中枢であるQueryRewriterの概要です。次ページでは、「どのような経緯で本プロジェクトを始めたのか」「なぜ検索のランキング改善に機械学習が有用なのか」を述べていきます。
関連記事
 事例で分かるデータ分析プロジェクトの進め方の基本
事例で分かるデータ分析プロジェクトの進め方の基本
ビジネスのデータ分析業務に12年ほど関わる筆者の経験に基づきデータ分析のプロジェクトがどのようなものかをお話しします。 リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。初回はユーザー体験(シナリオ)の良しあしの検証と、改善するABテストの基本的な考え方、サービス改善PDCAプロセス、チーム体制について。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。