「人間行動」と「検索」の関係に見る、機能改善に本当に必要だったもの:機械学習活用プロジェクト大解剖(終)(2/2 ページ)
人間行動の結果極端な偏りのある分布に注意
こういった予想効果を計算する際に注意すべきは、人間の行動が引き起こす、非常に偏った行動の分布です。よく知られている例としては、「極端によく検索されるキーワードの検索数」が、「他の検索数が少ないキーワードの検索数」を圧倒的に凌いでしまう、というケースがあります。試しに1つ例を出しましょう。求人情報サイトでよく検索されているキーワードを検索頻度が多い順に横軸に並べ、その検索数を縦軸に取ると、その検索数は順位のべき乗に比例する分布になります。
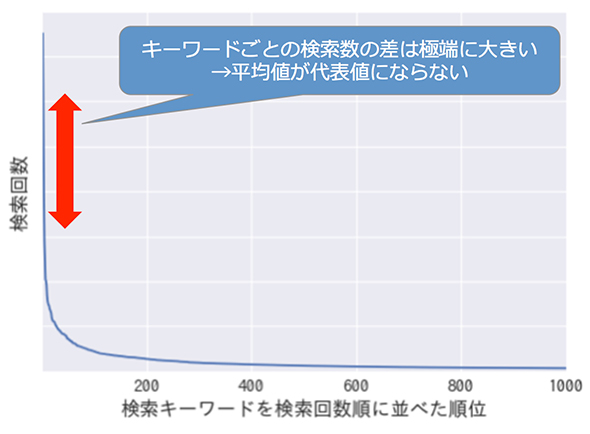 図4 検索数が多い順に並べた、検索キーワードとその検索数
図4 検索数が多い順に並べた、検索キーワードとその検索数このような分布をする変数は、平均値を元に期待値を求めても「正しい見立て」にはなりません。全ては紹介しきれないので詳細は省きますが、「正しい見立て」を行うためには、キーワード検索ユーザーの行動をさらに分解して仮説を立ててモデル化し、モデルごとに適切な代表値を用いて期待値を求めることが必要になります。
ランキング改善
ここまで来れば、機械学習を使ってランキングアルゴリズムを改善することができます。
前述の求人情報サイトの例でいえば、適合率の計算で使った「キーワードの検索意図」をそのまま反映する方法が最もシンプルです。検索キーワード「ホテル」の場合、「ホテル業界の求人情報」が上位に表出されるよう、単一属性のブースト値を調整するのです(ブースト値の調整方法については、前回記事をご覧ください)。
弊社内でこうした「単一属性の重み調整」を実施したところ、実際にKGI改善効果がありました。さらに、ブーストすべき属性が複数ある場合、パラメーターの最適化手法としては「RankSVM(Support Vector Machine for Ranking)」という機械学習の手法を使えます。
RankSVMによるパラメーター最適化
RankSVMによるパラメーター最適化とは、簡単に言うと、「適合率を目標関数として、検索エンジンの各フィールドのスコアの重みを学習させていくこと」となります。以下はRankSVMの概要です。
- 検索結果内のアイテム全ての組み合わせについて順序付きのペアを作り、全属性数と同じ次元数の空間に配置する。多次元空間での座標はペアのお互いのアイテムの「属性値の差」を用いる
- 適合率が「1→2」の順で正順になっているペアと逆順になっているペアをうまく分離するような平面を求める→その分離平面の法線ベクトルが各属性の重みを決めるパラメーターとなる
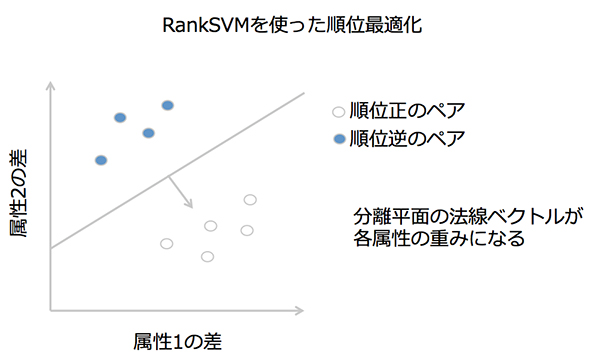 図5 RankSVMの模式図
図5 RankSVMの模式図検索適合率以外の改善
今回は適合率を向上させるためのランキングアルゴリズムの最適化を紹介しましたが、もちろん同様の手法は再現率向上(検索漏れの削減)にも使えます。
再現率を同じように仮説を立てて定量化し、機械的に計算できる形にして、再現率を向上させる機械学習を実施すればいいだけです。再現率の向上には検索エンジンでは「シノニム(同義語)機能」を使うことができます。
本連載を通して、検索改善のために必要な準備を紹介しました。前回までに紹介した、QueryRewriterによるアーキテクチャ面のサポート、今回紹介した現状分析・施策立案のために必要な準備があることで、機械学習の効用を享受し、効果を振り返ることもできます。
さらにその後、人間の能力を超えるものとしてDeep Learningを導入することが、Deep Learningを真に活用していく方法だと考えます。
筆者紹介
小田 充志(おだ あつし)
リクルートテクノロジーズ ITマネジメント統括部 テクノロジープラットフォーム部 APプロダクト開発グループ
SI企業でWebアプリケーションフレームワークなどの研究開発を経て、2014年9月リクルートテクノロジーズに入社。
現在は検索ユニットで、検索UX向上のための分析・ロジック開発・アーキテクチャ設計に従事している。
関連記事
 事例で分かるデータ分析プロジェクトの進め方の基本
事例で分かるデータ分析プロジェクトの進め方の基本
ビジネスのデータ分析業務に12年ほど関わる筆者の経験に基づきデータ分析のプロジェクトがどのようなものかをお話しします。 リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
リクルートの有名サイト事例に見る、シナリオベースABテストの基本的な考え方と改善プロセス、チーム体制
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。初回はユーザー体験(シナリオ)の良しあしの検証と、改善するABテストの基本的な考え方、サービス改善PDCAプロセス、チーム体制について。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。