Text Analytics API:Dev Basics/Keyword
Text Analytics APIは、入力されたテキストを基にそれがどの言語で書かれたものか、肯定的か否定的か、テキストに含まれるキーフレーズなどを取り出してくれるWeb API。
Text Analytics APIは、マイクロソフトのCognitive Servicesが提供するAPIの1つで、入力されたテキストを基にそれがどの言語で書かれたものか、肯定的か否定的か、テキストに含まれるキーフレーズなどを取り出してくれるもの。本稿執筆時点(2017年6月5日)では本APIの機能の幾つかはプレビュー版となっている。
Text Analytics APIとは
Text Analytics APIは、入力されたテキストから以下の情報を抽出してくれる。キーフレーズとはテキストに含まれている語の中で重要と思われるもので、トピックとは100以上のテキストレコードを入力した場合に、そのテキストで語られているトピックとしてText Analytics APIが識別するものである(キーフレーズは一文の入力でも抽出される)。
- 言語
- 肯定的か否定的か
- キーフレーズ
- トピック
ただし、現段階では抽出できる情報はそのテキストの言語によって異なる。例えば、日本語のテキストをAPIに与えた場合、抽出できるのは言語情報とキーフレーズ情報となる。Text Analytics APIがサポートしている言語と、それらの言語でどの情報を抽出できるかについては「Text Analytics API」ページを参照のこと。
なお、LUIS(Language Understanding Intelligent Service)のように、ユーザーの側で言語モデルを独自に作成するといった機能は本APIでは提供されていない。シンプルにテキストを与え、そこから上に挙げた情報を抽出するためのAPIである。より高度な処理が必要であればLUISを使うといった切り分けになるだろう。
Text Analytics APIの使い方
Text Analytics APIを使用するには、Azureのポータル画面でサブスクリプションを追加しておく必要がある。Cognitive Servicesが提供するAPIなどのサブスクリプションを追加する詳しい手順は「Dev Basics/Keyword: Microsoft Translator Text API」を参考にしてほしい。
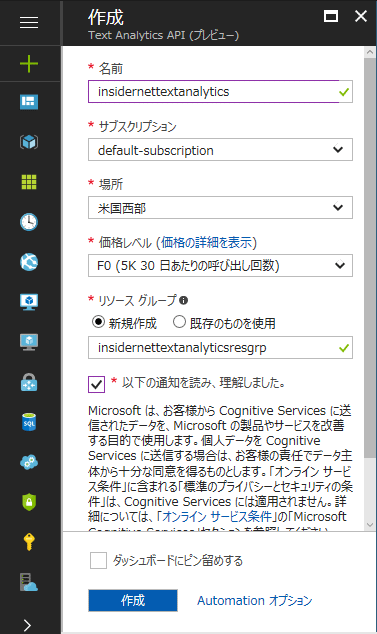 Text Analytics APIのサブスクリプションを追加
Text Analytics APIのサブスクリプションを追加Text Analytics APIの価格レベルについては「Cognitive Services の価格 - Text Analytics API」ページを参照されたい。上の画像では1カ月で最大5000トランザクションまで無料で使えるプランを指定している。
APIの呼び出しには、追加したサブスクリプションで与えられているアクセスキーが必要となるので、これをコピーしておく。

Text Analytics APIが提供するAPIは「Azure Machine Learning - Text Analytics」ページで一覧、試用できる。インタラクティブなAPIドキュメントの使い方については「Dev Basics/Keyword: Bing Image Search API」も参照されたい。以下では簡単に使い方を紹介する。
その前に簡単にこのAPIについてまとめておこう。言語/キーフレーズ/肯定的か否定的か/トピックはそれぞれ異なるURLで提供されるAPIを呼び出して抽出する。それらのURLはText Analytics APIのベースとなるURLに、それぞれ以下を付加したものになる。
- 言語: languages
- キーフレーズ: keyPhrases
- 肯定的か否定的か: sentiment
- トピック: topics
言語の抽出については検出する言語の数を指定するnumberOfLanguagesToDetectパラメーターを、トピックの抽出については語句の出現回数によってその語を無視するかを指定するminDocumentsPerWordパラメーターとmaxDocumentsPerWordパラメーターを指定可能だ。なお、日本語テキストではトピックの抽出はサポートされていないので、本稿では取り上げない(肯定的か否定的かの抽出もサポートされていないのだが、これらについては以下で述べるようにリクエストボディーが同一であることから最後のサンプルコードでは呼び出し例を示す)。このAPIの使い方については「Quick Start Guide」ページの該当部分やDetect Topics APIの説明を参照されたい。
言語/キーフレーズ/肯定的か否定的かを抽出する3つのAPIについては、リクエストボディーは以下のような形式になる。
{
"documents": [
{
"language": "言語(ja、enなど)",
"id": "ユニークなID その1",
"text": "テキストその1"
},
…… 省略 …・
{
"language": "言語(ja、enなど)",
"id": "ユニークなID そのn",
"text": "テキストそのn"
}
]
}
このJSONデータを見れば分かるように、一度のリクエストで複数のテキストを送信できる。idプロパティはAPIが返送した抽出結果が、どのテキストのものかを区別するために使用する(返送結果にもidプロパティの値が含まれるので、この値を使用して元データと照合する)。languageプロパティはオプションであり、英語以外の言語でキーフレーズ/肯定的か否定的かを抽出する場合には、このプロパティを指定してもよい(言語を抽出する際には不要だろうが指定は可能だ)。そして、textプロパティに各種の情報を抽出する対象となるテキストを指定する。
以上を前提として、インタラクティブなAPIドキュメントで実際にAPI呼び出しを行ってみる。インタラクティブなAPIドキュメントには左側にText Analytics APIが提供する各種APIが一覧される。以下の画像ではDetect Language APIのドキュメントが表示されている。

ここにはおおよそ上に述べたような情報(リクエストURL、指定可能なパラメーター、戻り値)が掲載されている。実際に使用する際には、必要に応じて各APIの概要を調べるようにしよう。ここで[Open API testing console]ボタンをクリックすると、インタラクティブにリクエストを組み立てて、API呼び出しを行う画面が表示される。ここで上で述べたidプロパティ、textプロパティに加えて、先ほど取得したアクセスキーを指定する。
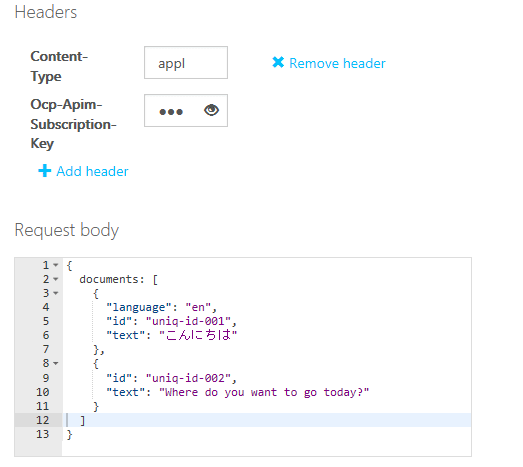 APIテストコンソールに必要な情報を入力したところ
APIテストコンソールに必要な情報を入力したところここでは2つのテキストから言語が何かを抽出している。最初のデータには試しにlanguageプロパティとして「en」を指定している点にも注意。最後に[Send]ボタンをクリックすると、下に検出結果が表示される。
 検出結果
検出結果見ての通り、最初のデータは日本語(Japanese、ja)、次のデータは英語(English、en)と判定されていることが分かる。iso6391NameプロパティはISO 639-1で定められている略称を示す。scoreプロパティは0〜1の間の数値であり、推測の確度を示す(1であれば、100%の確度)。
最後にこれをJavaScriptで呼び出すコードを以下に示す(npmのrequestパッケージを使用)。ここでは、言語の抽出に加えて、キーフレーズ抽出と肯定的か否定的かの抽出も行っている。ただし、コード再利用の方法が手抜きなのはご容赦願いたい。テキストについては先ほどの例よりも少し長めのものにしている。また、日本語テキストについてはlanguageプロパティに「ja」を指定している。
const request = require("request");
const key = "アクセスキー";
const url = "https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/";
const orgbody = {
documents: [
{
"id": "uniq-id-001",
"text": "It's easy to detect sentiment, key phrases, and languages in " +
"your text. You will programmatically get the same results as is " +
"shown in the demo experience."
},
{
"language": "ja",
"id": "uniq-id-002",
"text": "Text Analytics APIは、マイクロソフトのCognitive Servicesが提供" +
"するAPIの1つで、入力されたテキストを基にそれがどの言語で書かれたものか、" +
"肯定的か否定的か、テキストに含まれるキーフレーズなどを取り出してくれるもの"
}
]
};
function callapi(api, header, msg) {
opt = {
url: url + api,
headers: {
'Ocp-Apim-Subscription-Key': key
},
body: JSON.stringify(orgbody)
};
request.post(opt, (err, res, body) => {
console.log("\n" + header);
var jsondata = JSON.parse(body);
for (var item of jsondata.documents) {
var tmp = orgbody.documents.filter(x => item.id == x.id);
console.log(eval(msg));
}
});
}
callapi("languages", "言語抽出",
"`${tmp[0].text}:\n-> ${item.detectedLanguages[0].name}`");
callapi("keyPhrases", "キーフレーズ抽出",
"`${tmp[0].text}:\n-> ${item.keyPhrases}`");
callapi("sentiment", "肯定的か否定的か",
"`${tmp[0].text}:\n-> ${item.score}`");
やっているのは、変数optに必要な情報(各APIのURL、アクセスキー、idプロパティとtextプロパティを持った2つのデータで構成されるリクエストボディー)をまとめて、npmのrequestパッケージが提供するpostメソッドを呼び出すだけだ。最後に、返送されたデータに含まれているid値を使用して、元データと照合を行って、検出結果を表示するようにしている。実行結果を以下に示す(改行を適宜挿入している)。強調書体で表示したところが抽出結果だ。
> node textanalytics.js
キーフレーズ抽出
It's easy to detect sentiment, key phrases, and languages in your text. You will
programmatically get the same results as is shown in the demo experience.:
-> languages,demo experience,key phrases,sentiment,results,text
Text Analytics APIは、マイクロソフトのCognitive Servicesが提供するAPIの1つで、入
力されたテキストを基にそれがどの言語で書かれたものか、肯定的か否定的か、テキスト
に含まれるキーフレーズなどを取り出してくれるもの:
-> テキスト,もの,Text Analytics API,マイクロソフト,Cognitive Services,提供,入力,
キーフレーズ,言語
言語抽出
It's easy to detect sentiment, key phrases, and languages in your text. You will
programmatically get the same results as is shown in the demo experience.:
-> English
Text Analytics APIは、マイクロソフトのCognitive Servicesが提供するAPIの1つで、入
力されたテキストを基にそれがどの言語で書かれたものか、肯定的か否定的か、テキスト
に含まれるキーフレーズなどを取り出してくれるもの:
-> Japanese
肯定的か否定的か
It's easy to detect sentiment, key phrases, and languages in your text. You will
programmatically get the same results as is shown in the demo experience.:
-> 0.904624384846958
現状では日本語のテキストでは言語検出とキーフレーズ抽出のみがサポートされていることから「肯定的か否定的か」では出力がない(肯定的か否定的かの出力結果は0〜1の値であり、0.3よりも低ければ否定的、0.7よりも大きければ肯定的と判断されたことを意味する)。また、languageプロパティに「ja」を指定したことからキーフレーズの抽出が比較的うまく行えている。参考までに、このプロパティを指定しなかった場合の出力例を以下に示す(該当部分のみ)。比べると分かるが、languageプロパティを指定した場合の方がうまく抽出できている。
-> マイクロソフトのCognitive Servicesが提供するAPIの,つで,Text Analytics APIは,
入力されたテキストを基にそれがどの言語で書かれたものか
キーフレーズを抽出する場合、前もってテキストが何語で書かれているかが明確であれば、それをlanguageプロパティに、不明であれば、言語抽出APIをまず呼び出して、その結果を基にlanguageプロパティを指定するのがよいだろう。
Text Analytics APIを使用すると、テキストを与えるだけで、その言語/キーフレーズ/肯定的な否定的かといった情報を簡単に取得できる。
参考資料
- Text Analytics API: Text Analytics APIのトップページ
- Quick Start Guide: APIの使い方の概要を説明したページ
- Azure Machine Learning - Text Analytics: インタラクティブなAPIドキュメントページ
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。