Computer Vision API:Dev Basics/Keyword
Computer Vision APIを使用すると、マイクロソフトが提供する画像処理アルゴリズムを使って、APIに渡した画像ファイルの解析を行い、さまざまな情報をそこから得られる。
Computer Vision APIは、マイクロソフトのCognitive Servicesが提供するAPIの1つで、画像の分析、画像内のテキストの読み取り、有名人やランドマークの識別、サムネイル生成などを行える。
Computer Vision APIが提供する機能
Computer Vision APIを使うと次のような処理を行える。
- 画像の分類やタグ付け
- 画像内の文字認識(手書き文字も可能)
- 画像を説明するキーワードの列挙
- 画像の種類の識別
- 画像に顔が含まれているかの判定
- アダルトコンテンツかどうかの判定
- ランドマークや有名人の識別
これらの機能が幾つかのAPIを介して提供される。提供されるAPIについては「Computer Vision API - v1.0」ページで一覧できる。このページはインタラクティブなAPIドキュメントとなっていて、APIテスト用のコンソールを表示することで、実際のデータ(画像ファイルのURL)を指定してAPIの挙動を確認できる。ただし、試してみるだけでもAzureポータルでComputer Vision APIのサブスクリプションを追加して、そのアクセスキーを前もって取得しておく必要がある。

AzureポータルでのCognitive Servicesが提供する各種サービスのサブスクリプションの追加方法については「Dev Basics/Keyword: Microsoft Translator Text API」を参照されたい(ただし、Computer Vision APIではアクセス用のトークンを生成する必要はない。サブスクリプションの[キー]セクションで表示されるアクセスキーをそのまま使用する)。

また、Computer Vision APIでは「5000トランザクション/月、20トランザクション/分」を上限として無料で使える価格レベルがあるので、試してみるだけであれば、この価格プランを使用するとよい。価格についての詳細は「Cognitive Services の価格 - Computer Vision API」ページを参照されたい(2017年6月12日時点ではComputer Vision APIを使用できるリージョンはそれほど多くない。また、リージョンによっては無料の価格レベルを選択できない場合もあるので注意しよう)。
以下ではサブスクリプションを追加して、そのアクセスキーを取得したものとして、実際にAPIを使用してみる。
Computer Vision APIの使い方
APIを試用するには、先にも述べたインタラクティブなAPIドキュメントページが簡単だ。

上の画像を見ると分かる通り、Computer Vision APIは以下のAPIを提供する。
- Analyze Image: visualFeaturesパラメーターおよびdetailsパラメーターの指定に応じて、画像の各種解析を行う
- Describe Image: 画像を説明する文を取得する
- Tag Image: 画像に関連するキーワードを取得する。Describe Image APIとの違いは、こちらは単語レベルの結果を取得し、Describe Image APIはこのキーワードをベースに「説明文」を取得するところ
- Get Thumbnail: 画像のサムネイルを取得する
- Recognize Domain Specific Content: Computer Vision APIでサポートされているDomain Specific Modelを利用して、画像についての情報を取得する
- List Domain Specific Models: Computer Vision APIがサポートしているDomain Specific Modelを取得する(本稿執筆時点でサポートされているのは有名人とランドマークの2つだけ)
- Recognize Handwritten Text: 手書き文字認識を行う
- Get Handwritten Text Operation Result: 手書き文字認識を行った結果を取得する
- OCR: OCRによって画像に含まれているテキストを認識する
ここでは例として、Azure上にアップロードした画像ファイルを使用し、Analyze Image APIを実際に呼び出してみよう(AzureでストレージアカウントやBLOBコンテナを作成し、そこに画像ファイルをアップロードする手順については割愛)。
Analyze Image APIのドキュメントにはAPIの仕様が記述されている。簡単には以下のような情報が読み取れる。
- URL: https://[location].api.cognitive.microsoft.com/vision/v1.0/analyze
- パラメーター: visualFeatures、details、language(全てオプション)
- リクエストボディー: 画像ファイルのURLもしくは画像ファイルそのもの
Computer Vision APIでリクエストを行うURLは、Azureポータルで追加したサブスクリプションのリージョンによって異なるものになる点に注意。例えば、リージョンを「米国西部」とした場合には、URLは「https://westus.api.cognitive.microsoft.com/……」のようなものになる。アクセスキーに加えて、この情報も覚えておく必要がある。
URLに含める3つのパラメーターは全てオプションである。このうち、visualFeaturesパラメーターでどんな情報を取り出すかを指定できる。複数の処理を行う場合にはカンマ区切りでこれらを指定する。
- Categories: 画像の分類
- ImageType: どんな画像か(クリップアートか線画かなど)を判断
- Faces: 画像に顔が含まれているか
- Adult: アダルトコンテンツかを判断
- Tags: 画像のタグ付け
- Description: 画像を説明する英文の取得
- Color: カラースキームの取得
detailsパラメーターは、有名人/ランドマークを判断する際に指定する。CelebritiesかLandmarksを指定可能(両方を指定する場合はカンマで区切る)。
languageパラメーターにはAPIの処理結果を返送する言語を指定する。現状では英語か簡体字のどちらかなので、本稿では省略する。
インタラクティブなドキュメントページでは、画像ファイル自体をリクエストボディーに含められないので、ここでは前述したようにAzure上にアップロードした画像ファイルのURLを指定することにする。実際の画像を以下に示す(宮城県の松島湾の写真だ)。

また、visualFeaturesパラメーターに複数の処理を指定している。テストコンソールでは、デフォルトでドロップダウンが表示されるようになっているので、[Remove parameter]リンクをクリックして一度このパラメーターを削除した上で、[Add parameter]リンクをクリックして、複数の値を指定する。上でも述べたが、リージョンごとにAPIのURLが異なるので、APIのテスト用コンソールを開くときには、自分が追加したサブスクリプションのリージョンに対応するコンソールを開くようにしよう。以下に実際にこれらの指定を行っている画面を示す。
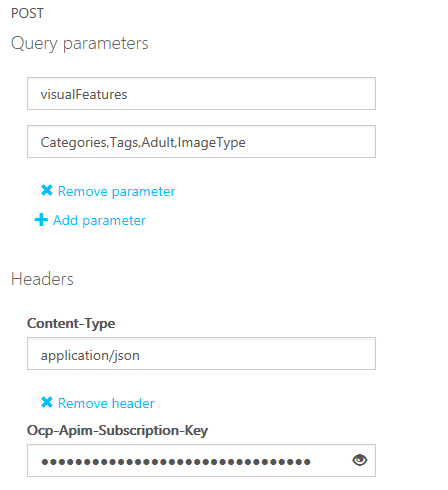
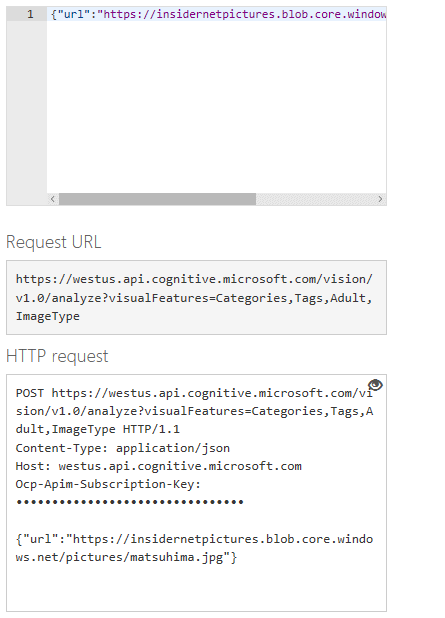 パラメーターとリクエストボディーの指定、組み立てられたHTTPリクエスト
パラメーターとリクエストボディーの指定、組み立てられたHTTPリクエスト上の画像ではvisualFeaturesパラメーターを指定している。下の画像ではリクエストボディーに画像のURLを指定している。また、最下部には最終的なHTTPリクエストが表示されている。
ここではカテゴリー(画像の分類)、タグ付け、アダルトコンテンツかの判定、画像の種類の判別を行うように指定している。最後に[Send]ボタンをクリックすれば、結果が返送される。以下にこの結果を示す。
{
"categories": [
{
"name": "outdoor_",
"score": 0.00390625
},
{
"name": "outdoor_waterside",
"score": 0.68359375
}
],
"adult": {
"isAdultContent": false,
"isRacyContent": false,
"adultScore": 0.0066425465047359467,
"racyScore": 0.0087167257443070412
},
"tags": [
{
"name": "water",
"confidence": 0.99987697601318359
},
{
"name": "outdoor",
"confidence": 0.99969041347503662
},
{
"name": "sky",
"confidence": 0.99210923910140991
},
{
"name": "boat",
"confidence": 0.85895222425460815
},
{
"name": "shore",
"confidence": 0.26391658186912537
},
{
"name": "day",
"confidence": 0.18799528479576111
}
],
"requestId": "d56a8f35-c1fb-4036-ab69-e5269770e086",
"metadata": {
"width": 4000,
"height": 2250,
"format": "Jpeg"
},
"imageType": {
"clipArtType": 0,
"lineDrawingType": 0
}
}
詳しくは見ないが、visualFeaturesパラメーターで指定した種類ごとに、APIが処理した結果がまとめられている。categoriesプロパティを見ると「outdoor_」「outdoor_waterside」となっていてサンプル画像が海を撮影したものであること、tagsプロパティには「boat」が含まれていることから船があること、adultプロパティはfalseがあることからアダルトコンテンツではないこと、imageTypeプロパティを見るとクリップアートでも線画でもないことが分かる。
最後に、このAPIを呼び出すJavaScriptコードの例を以下に示す。やっていることはこれまでに見てきたことと同じなので、説明は割愛する。
const request = require("request");
const fs = require("fs");
const key = "アクセスキー";
const url = "https://westus.api.cognitive.microsoft.com/vision/v1.0/analyze";
const body = {
url: "https://insidernetpictures.blob.core.windows.net/pictures/matsuhima.jpg"
};
const param="?visualFeatures=Categories,Tags,Adult,ImageType"
var opt = {
url: url + param,
headers: {
"Ocp-Apim-Subscription-Key": key,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
};
request.post(opt, (err, res, body) => {
console.log("URL");
console.log(JSON.parse(body));
});
// ローカルの画像ファイルを渡す場合
const image = fs.readFileSync("matsuhima.jpg");
opt = {
url: url + param,
headers: {
"Ocp-Apim-Subscription-Key": key,
"Content-Type": "application/octet-stream"
},
body: image
};
request.post(opt, (err, res, body) => {
console.log("local file");
console.log(JSON.parse(body));
});
実行結果は上と同様なので、省略する。
Computer Vision APIは画像ファイルをアップロードするか、そのURLを指定するだけで、マイクロソフトが提供する画像処理アルゴリズムを使って画像解析を行い、さまざまな情報をそこから得られる。前述のように、サムネイルの作成やランドマークの識別なども行えるので、上の手順あるいは上のコードをサンプルにこれらの機能も試してみてほしい。
参考資料
- Computer Vision API: Computer Vision APIのトップページ
- Computer Vision API Version 1.0: Computer Vision APIの概要
- Computer Vision API - v1.0: インタラクティブなAPIドキュメント
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。