機械学習の前に重要なデータ抽出・加工に便利なPythonライブラリ「pandas」の基本的な使い方のチュートリアル:Pythonで始める機械学習入門(6)(2/4 ページ)
データの抽出
1次元にデータが並んだ「Series」型
次に、始値だけを抜き出してみましょう。次のようにします。
同じようにデータの先頭部分を表示してみます。
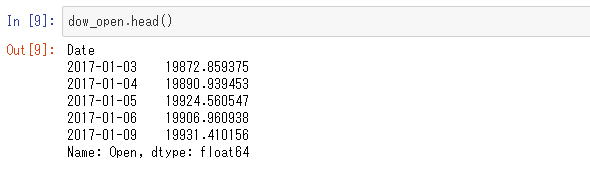
dow.head()を表示したときと表示形式が変わっていますが、実はデータ型が異なるのです。確認してみましょう。

今度はSeries型というデータ型になっていることが分かります。DataFrame型が2次元的な広がりを持つ表であるのに対し、Seriesは1次元にデータが並んだものです。DataFrameは各行にインデックスが付与されていますが、Seriesも同様に各要素にインデックスが付与されています。上記で見たように、DataFrameから1列を抽出するとSeries型になります。
DataFrame型から複数の列を取り出す
[]の中にリストを入れることでDataFrameから複数の列を取り出すこともできます。その場合、戻り値の型はDataFrameになります。
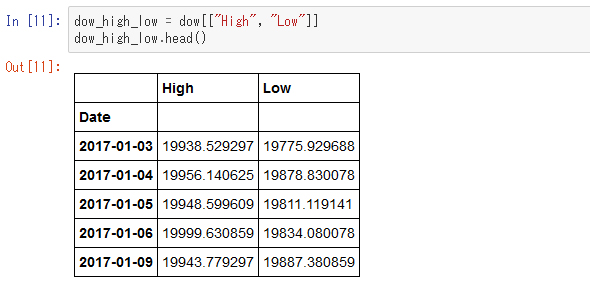
条件による行の抽出
次に、条件による行の抽出を行ってみましょう。連第4回で紹介したNumPyのブロードキャスティングとインデクシングの組み合わせと同様にできます。
次の例では高値が2万4000ドルを超えている行を抽出します。

ラベルによる指定の「loc」メソッドと位置による指定の「iloc」メソッド
以降の説明のために簡単な人工データを用意します。

「loc」メソッドを使って行と列を指定して次のような抽出もできます。

この[]の中の3:5はインデックスが3〜5であることを意味し、["B", "C"]はB列とC列を意味します。このようにlocだとDataFrameに付与されたインデックスと列名で指定しますが、「iloc」メソッドを使って数値で指定することもできます。次がその例です。
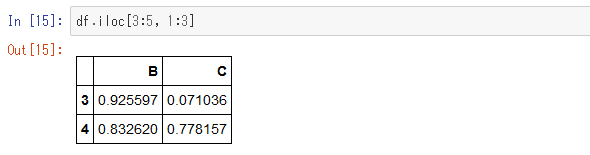
locのときの3:5はインデックスが3〜5だったのに対し、ilocでの3:5は3〜4になっていることに注意してください。ilocの仕様はリストや配列でのインデックス指定と同じになっています。このようにlocはラベルによる指定なのに対し、ilocは位置による指定になってます。
データの加工
既存のDataFrameに対して何らかの計算を行ってデータを付加したいことがよくあります。試しに、C列とD列を足し算したものをE列として追加してみましょう。
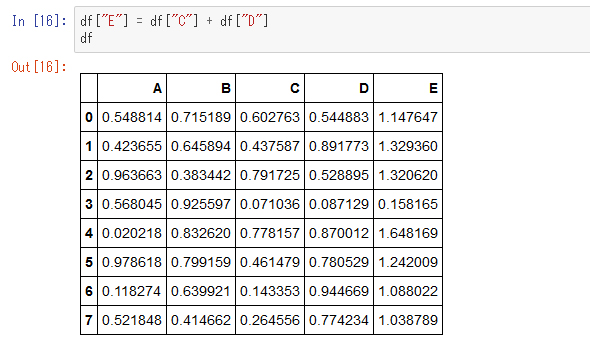
この足し算はNumPyのブロードキャスティングと同じです。このようにして列を増やすことができますが、同じような書き方で列を上書きすることもできます。例として、B列を2倍したものをA列に上書きしてみましょう。
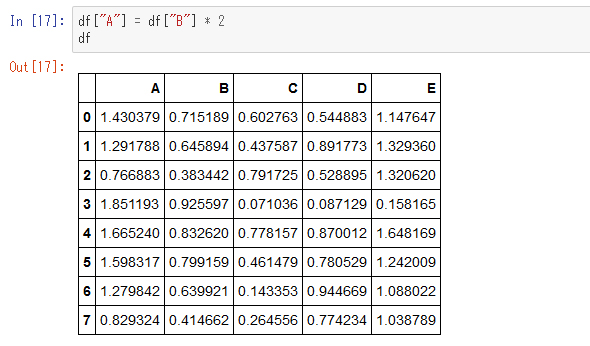
1つのセルを書き換える「at」メソッドと「iat」メソッド
1つのセルを書き換えるのには「at」や「iat」を使います。
atはラベル指定版で、例えば次のように使います。
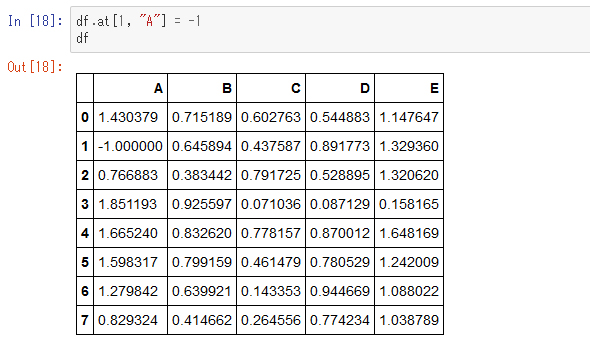
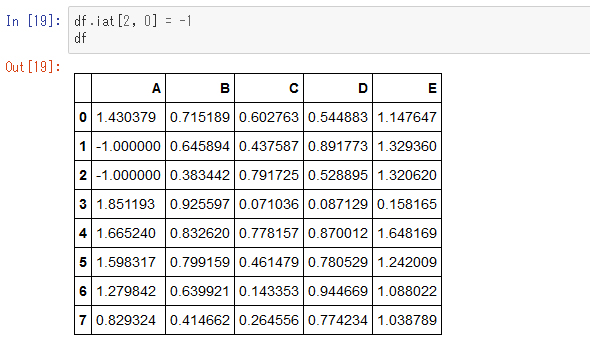
1つのセルが-1に置き換わりました。位置を指定してセルを書き換えるにはiatを使います。
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。