インフラ基盤がWebサービスを進化させる――クラウド全盛の今、リクルートが新インフラ基盤をオンプレミスに作った理由:SREの考え方で“運用”を変えるインフラ基盤 大解剖(1)
本連載では、「インフラの、特に基盤寄りの立場からSRE(Site Reliability Engineering)の活動を行い、Webサービスの価値を高めるためにはどうしたらいいか」について、リクルートの新たなインフラ基盤を例に見ていきます。
従来、リクルートはオンプレミスに巨大なインフラを抱えており、そのインフラ上でさまざまなサービスを提供してきました。昨今、世の中にはAWS(Amazon Web Services)やGCP(Google Cloud Platform)、Microsoft AzureをはじめとしたさまざまなIaaS(Infrastructure as a Service)があり、システム開発者はそれらを自由に選択することができます。それにもかかわらず、リクルートでは従来のインフラ基盤を刷新して、新たなインフラ基盤をオンプレミスに構築することになりました。それには理由があります。
「インフラ基盤ごと作る」という手段は、非常にコストと時間がかかる選択肢ですが、この手段が「必要なものである」として採用するに至った背景があります。
本連載では、「インフラの、特に基盤寄りの立場からSRE(Site Reliability Engineering)の活動を行い、Webサービスの価値を高めるためにはどうしたらいいか」に悩んでいる方々に向けて、リクルートの新たなインフラ基盤である「RAFTEL Fleetサービス(以下、Fleet)」を作ることになった背景と狙い、そして「いかにしてFleetを作り上げたのか」について順に紹介していきます。
基盤インフラの将来と、見えてきたRAFTELの限界
Fleetを紹介する前に、リクルートのインフラ基盤の歴史を振り返るとともに、従来のインフラ基盤で抱えていた課題を明らかにします。
リクルートのインフラ基盤の前身となる「RAFTEL」の歴史
リクルートはさまざまなWebサービスを提供していますが、そのうちの主要なWebサービスは大半が、この「RAFTEL」というオンプレミスのインフラ基盤上で稼働しており、その数は2018年現在でおよそ250に上ります。
RAFTELの歴史は古く、2006年頃にリクルートのインフラ基盤として誕生しました。それからインフラの更改を挟みつつ現在に至るまでさまざまなWebサービスを支え続けています。

古くから多くのWebサービスを支えてきたRAFTELですが、時代の変化とともに課題も数多く生まれてきました。
【課題1】インフラ設定作業にかかるリードタイム
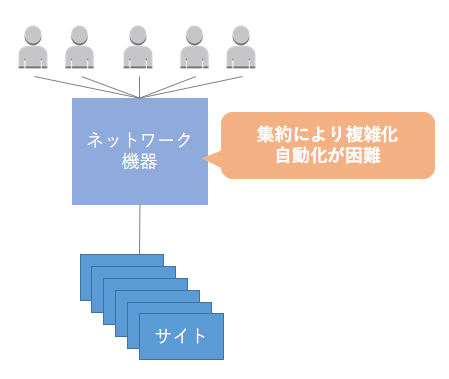
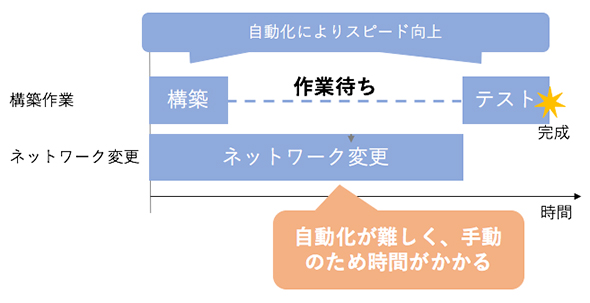
これまでのRAFTELは、機器を集約し、設定を共通化することでトータルコストを抑えてきました。しかし一方で、機器の集約によってロードバランサーやファイアウォールをはじめとしたネットワーク機器の設定が複雑化しており、自動化の足かせとなっていました。
そのため、サーバ構築、運用など他の作業をいくら自動化したとしても、ネットワークの変更が足かせとなり、トータルのリードタイムの短縮には貢献できずにいました。結果的に、さまざまなWebサービスの突発的な環境変更にも対応できず、Webサービスの運用に不満を抱えている状態となっていました。
【課題2】Webサービスごとの個別要件の対応
上述の通り、RAFTELではさまざまな設定の共通化を行うことでトータルコストを抑えてきました。しかし、Webサービスの構成も個別に進化してきており、かつWebサービスごとのエンジニアが増加するに伴って、Webサービスごとにサイト開発者が自ら技術を選定できるようになってきました。
設定の共通化に伴うコスト削減よりも個別の進化を促すことによる価値の創造が必要になるにつれて、これまでの共通化だけでは対応し切れないケースが発生してきました。

【課題3】インフラ設定作業の「申請」という行為と管理情報の分散
設定の共通化を行うことは、設定作業を行う人員を共通化することでもあります。従って、各Webサービスの開発者は、中央組織に対してインフラ設定を「申請」する運用フローとなっていました。
申請には申請書が必要となり、その申請書を元にして依頼者と作業者間でコミュニケーションが図られます。しかし、依頼側が管理する設定情報の管理台帳と実機上のズレが顕著になり、本来不要な確認、合意、意識を擦り合わせるためのコミュニケーションが多発していました。
従来のRAFTELの課題を解決する「Fleet」という選択肢
これらの課題を抱えたまま、従来のインフラ基盤を踏襲しつつ解決へと導くことは、もはや不可能でした。なぜなら、上述の課題のどれもが、インフラ基盤の根幹に関わっており、かつリクルートのWebサービスを支える重要な基盤でもあるため、抜本的な変更を行うことの影響が大き過ぎるためです。
従ってリクルートテクノロジーズは、RAFTELに代わる次世代のインフラ基盤として、「Fleet」という基盤を一から作ることを決めました。
Fleetは、先述の課題を下記の通りに解決しています。
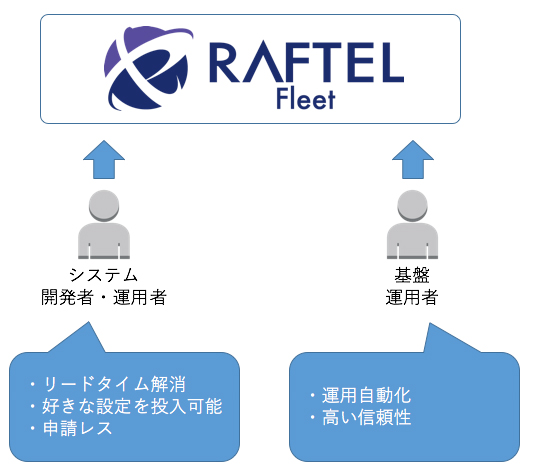
- 即時提供によるリードタイムの解消
- 開発者が希望する好きな設定を可能に
- そもそも依頼者が自らオーダーすることで申請を不要な世界観に
SREの考え方でインフラ基盤の運用を変える
Fleetは、Webサービス開発者向けの課題を解消するためだけに作られたものではありません。リクルートの数多くのWebサービスを支えるインフラを運用するに当たり、従来の運用手法では限界が来ていたのも事実です。今後、どんなWebサービスが、どんな規模でやってきたとしても、インフラ基盤としてはそれをさばき切る必要があります。
しかし、それは単に基盤の性能を上げれば良いという話ではありません。どんなに機器の性能を上げたとしても、その機器に対する変更作業が数多く発生し、常に人的リソースを多く消費したり、その作業が非常に危険なものであったり、常にヒューマンエラーによる停止のリスクと隣り合わせであったりしては本末転倒です。
「運用作業をより効率的にし、障害に強くあるところまでを見据えるべきだ」と私たちは考えました。
これらを解決するためには、ハードウェアの選定と、それを制御するソフトウェアエンジニアリングの2つが必要でした。高い信頼性と性能を持ち、自動化の受け口を持つハードウェアを、ソフトウェアエンジニアリングの力をもって制御、解決し、運用そのものを変える。これは、まさに「SRE(Site Reliability Engineering)」という考え方に基づいて行われています。
結果として、ソフトウェアの知見をもって、設定の自動化による省力化とリスク低減という大幅なメリットを得られるようになりました。
Fleetの構成要素:FleetコンソールとFleetインフラ基盤
先述のようなソフトウェア/ハードウェアの2つのアプローチは、そのままFleetの構成要素になっています。すなわち、Fleetは以下の2つで構成されています。
- Fleet Management Console(Fleetコンソール)
- Fleetインフラ基盤

Fleetコンソールは、Fleetのソフトウェア制御の部分を担っています。後述のハードウェアに対して、一連の自動化やチェックを行い、運用作業を高速かつ安全に行うようになっています。利用者に対してのインタフェースはWeb GUIとCLIの2つを提供しており、利用者からの直観的な操作はもちろん、コマンドラインによるCI(Continuous Integration:継続的インテグレーション)への組み込みも可能にしています。
Fleetインフラ基盤は、高いパフォーマンスと高い信頼性を備えた構成になっていることに加え、それぞれのコンポーネントは自動化を前提に選定、設計されています。
このソフトウェア/ハードウェアの2つの観点での取り組みは、次回以降に順次紹介していきます。
クラウドサービスでは解決が難しい理由
さて、こうした取り組み紹介すると、詳しい方であれば「AWS(Amazon Web Services)やGCP(Google Cloud Platform)、Microsoft Azureなどのクラウドサービスでは解決できないのか」と思うかもしれません。
その認識の通り、これらの課題に対して、IaaSのソリューションは素晴らしい解決策となり得ます。しかし、これまでオンプレミス上に共通的に作られたインフラ、そしてその上にデプロイされる巨大で歴史のあるWebアプリケーションが、理想的な土台を提供されたとして、簡単に移行できるのでしょうか?
その問いに対してリクルートテクノロジーズが下した判断は「No」でした。
確かに、クラウドサービスを利用した理想的なシステムというものがあったとしたら、それは素晴らしいものになるでしょう。しかしその理想は、「インフラ基盤を入れ替えれば全てが解決する」という安易なものではなく、システムアーキテクチャやアプリケーション、そして開発・運用フローなど、システムを取り巻く全てのものを変えないことには、理想的な状態にたどり着くことはできません。
しかし理想的な状態にたどり着くには、そのWebサービスの規模が大きければ大きいほど、莫大なコストと長大な期間を要することは想像に難くありません。インフラ基盤の入れ替えは理想に向けた一歩目にすぎないのです。
その点、Fleetは既存のインフラ基盤であるRAFTELとの親和性を重視して設計されています。既にRAFTEL上で稼働しているサービスが、先述の課題を解決しつつ、アプリケーションへの影響を極力低減させることで、Webサービスの価値を高める土台に「移りやすい」ことを重視しています。
具体的には、以下のような特徴があります。
- RAFTELと同じNFSストレージをマウント可能
- RAFTEL〜Fleet間で相互通信可能
- RAFTELと同じ仕様を踏襲して便利な部分の使い勝手は同じに(認証方法、名前解決)
- リクルートのセキュリティルールにのっとった設定「セット」をあらかじめ提供(ログ保管、通信)
Fleetによって目指す世界:インフラ基盤がWebサービスを進化させる
本稿では、Fleetを作るに至った背景を説明してきました。Fleetを利用することによって、リクルートのWebサービスは前述の「リードタイム」「個別要件」「管理情報」といった課題を解決することができました。加えて、インフラ基盤に関わる運用作業も効率化し、省力かつ低リスクでの運用を可能にしました。
しかしリクルートテクノロジーズは、新しいインフラ基盤を整備することで、単に「システム従事者の利便性の向上を図った」わけではありません。
Webサービスにとって、インフラ基盤の持つ責任は重大です。パフォーマンス、信頼性、保守性など、サービスにとって必要不可欠な要素を担っています。これらのどれもが、損なわれることによって基盤上のWebサービスの価値を著しく下げる要因となることは間違いありません。それでは、上記のような「パフォーマンス」「信頼性」「保守性」を保ち、そして現時点で見えている課題を解決したインフラ基盤を作れば問題は解決するのでしょうか?
技術はより高度に、そして便利になっていきます。現時点で理想的なシステム、そしてインフラであったとしても、数年もすれば色あせていきます。2018年現在においては、コンテナ技術を中心にしたアーキテクチャが流行しており、それによりインフラの抽象化、ポータビリティー、Infrastructure as Code、オートスケーリング、自動復旧、サービスディスカバリなどさまざまなメリットを享受しています。今後、さまざまな技術によってこれらがより発展することは間違いないでしょう。
しかし前述のように、インフラ基盤は時として足かせにもなります。インフラ基盤上に設計されたWebアプリケーションは、何らかの形でインフラ基盤の設計、構成に依存しており、決して無関係ではありません。そんな時、インフラ基盤ができることは、「新しいインフラ基盤にアプリケーションをロックインさせる」ことではなく、「さらに次世代のインフラに向けて移りやすい仕組み(=ポータビリティー)を用意する」ことではないかと考えています。
次世代のサービスの形がどんなものであったとしても、既存の形から最初は影響を与えず、しかし少しずつ進化しやすくするためにFleetは考えられています。Fleetは、単にインフラ基盤単体としてあるのではなく、「Webアプリケーションに寄り添って共に今後のWebサービスを支え、後押しする役割でありたい」と考えています。
次回は、こうして考えられたFleetの具体的な機能、そして実現策について具体的に紹介します。
筆者紹介
北野 太郎
株式会社リクルートテクノロジーズITエンジニアリング本部 サイトリライアビリティエンジニアリング部所属。
Apache Solrの普及と運用保守、全社検索基盤の展開、新規ミドルウェア検証を経て、新規インフラ基盤の開発と展開に従事。共著に『[改訂新版]Apache Solr入門』(技術評論社)『DevOps導入指南 Infrastructure as Codeでチーム開発・サービス運用を効率化する』(翔泳社)がある。趣味はインストゥルメンタル系音楽の鑑賞。
関連記事
 SREの現場はどうなっているのか――従来型の運用との決定的な違いとは
SREの現場はどうなっているのか――従来型の運用との決定的な違いとは
Site Reliability Engineering(以下、SRE)の現場はどうなっているのか。SREの日常的な仕事とはどのようなものなのか。開発エンジニアと運用担当エンジニアは、実際どのように役割分担し、協力し合っているのか。「SRE本」の監訳者などが語った。 エンジニア視点で説明する「メルカリ」、リリースから4年の道のり
エンジニア視点で説明する「メルカリ」、リリースから4年の道のり
2017年6月、執行役員 Chief Business Officer(CBO)に、元Facebookのバイスプレジデント ジョン・ラーゲリン氏を迎えるなど、国内はもちろんグローバル展開も加速させているメルカリ。世界に支持される同社サービスはどのように作られ、支えられているのか?――2017年9月に開催された技術カンファレンス「Mercari Tech Conf 2017」にサービス開発・運用の舞台裏を探った。 富士フイルムとメルカリSREが語る、「運用管理」という仕事の本当の価値と役割とは
富士フイルムとメルカリSREが語る、「運用管理」という仕事の本当の価値と役割とは
@ITは2017年12月12日に「@IT運用管理セミナー〜運用管理は『なくなる仕事』?」を開催した。本稿では、その内容をレポートする。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。