「AIで働き方改革」は本当に可能か――竹中工務店が挑んだ機械学習プロジェクトの成果とは:de:code 2018
日本マイクロソフトが開催した技術イベント「de:code 2018」で、竹中工務店が現場での「写真関連業務」の効率化を目指して機械学習の活用を図った事例が紹介された。登壇したのは、竹中工務店 技術研究所 先端技術研究部 主任研究員 博士 高井勇志氏だ。
近年、企業の「働き方改革」をサポートするために「AI」や「RPA(ロボット)」といったテクノロジーを取り入れようという機運が高まりつつある。しかし、参考にできる事例がまだまだ少ないといった理由などから「何から手を付ければいいのか」「どのように業務に組み込めばいいのか」がイメージできず、「最初の一歩が踏み出せない」という企業も多いのではないだろうか。
日本マイクロソフトが開催した「de:code 2018」では、竹中工務店が現場での「写真関連業務」の効率化を目指して機械学習の活用を図った事例が紹介された。
建設工事の現場で行われている「写真関連業務」をAI(機械学習)で効率化
 竹中工務店 技術研究所 先端技術研究部 主任研究員 博士 高井勇志氏
竹中工務店 技術研究所 先端技術研究部 主任研究員 博士 高井勇志氏大阪に本社を置く竹中工務店は、17世紀初頭に創業され、現在は「スーパーゼネコン」と呼ばれている日本を代表する総合建設会社の1社である。同社の技術研究所 先端技術研究部で主任研究員 博士を務める高井勇志氏は、建設業界全体が抱えている課題として「長時間労働」の常態化を挙げた。
日建協(日本建設産業職員労働組合協議会)が2015年に行ったアンケートによれば、建設業界において、建設工事全体で「工程表上の休日設定が4週8休以上」(週休
2日以上)に設定されている割合はわずか「5.7%」だという。高井氏は、業界としてこうした労働状況の改善が必要という認識はある一方で「現在の一般的なコストと工期では、全ての労働者が週に2日休むと建築物が完成しないという現実もある」とする。
【訂正:2018年7月20日午前14時10分】初出時、『建設工事に携わる人々のうち「4週8休」(週休2日)を守れている人の割合はわずか「5.7%」』という表現になっておりましたが、正確には『建設工事全体で「工程表上の休日設定が4週8休以上」(週休2日以上)に設定されている割合はわずか「5.7%」』でした。お詫びして訂正いたします(編集部)。
労働を通常の勤務時間内に収めていく取り組み
その解決に向けたアプローチとして、現在行われている業務を可能な限り効率化し、労働を通常の勤務時間内に収めていく取り組みが進められている。今回、同社が日本マイクロソフトと共同で取り組んだ機械学習による業務効率化プロジェクトも、その一端を担うものだ。
このプロジェクトでは、自動化が課題の解決に対して与えるインパクト、波及効果の大きさ、実現可能性などを検討した上で、ターゲットを建設工事の現場で行われている「写真関連業務」に設定した。建設工事の現場では、品質やコスト、安全性の管理などを目的として、大量の写真が撮影される。撮影枚数は1平方メートル当たり約10枚で、年間着工延べ床面積が1000万平方メートルに及ぶ同社の場合、実に約1億枚に上る写真が毎年撮影されていることになる。
「今までは、全ての写真を担当者が目で確認し、工事種別ごとに手作業で仕分けを行っていた。この写真の管理と整理にかかっている多大な時間を機械学習で削減することを目指した」(高井氏)
「データ」の選出が重要
機械学習プロジェクトにおいては、学習に利用する「データ」の選出が重要だ。同社では、技術面での要求を理解しているエンジニアが早い段階から介入しながら約1万枚の画像を選出してモデルの作成に利用した。その際には、並行して「撮影したデータの扱い」に対する関係各部署の意見などを聞きながら、主に情報漏えいなどに関する懸念事項の払拭(ふっしょく)を行ったという。
機械学習プロジェクトの成果
現在動いているシステムでは、担当者が撮影した画像を特定のフォルダに入れると、その画像が業務で使われる19のカテゴリー別に自動でタグ付けされるようになっているという。タグはExifデータとして付与されるため、Windowsのエクスプローラーによる検索も可能だ。現段階で既に「現場の作業時間短縮」という観点でかなりの成果を挙げているとする。
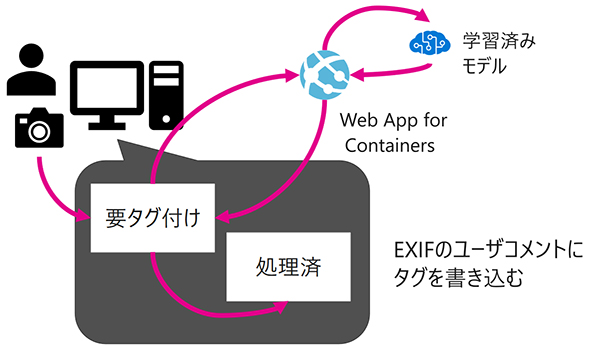
AIプロジェクトを進めるポイント
高井氏は「AIプロジェクトを進めるポイント」として、マーク・ザッカーバーグ氏による「完璧を目指すより、まず終わらせろ」、故スティーブ・ジョブズ氏による「人は形にして見せてもらうまで、何が欲しいのか分からない」といった言葉を引用しつつ、「まずは動くものを作ってみる」ことの重要性を指摘した。
その上でユーザーに話を聞くことで「そのシステムでやりたいこと、将来的なビジョンなどを引き出せるようになる」とする。そうしてユーザーを巻き込むことが、プロジェクトを推進する力になるとした。
「やってみなくては分からない」機械学習プロジェクトを効率的に進めるコツ
 日本マイクロソフト コマーシャルソフトウェアエンジニアリング本部 テクニカルエバンジェリスト 藤本浩介氏
日本マイクロソフト コマーシャルソフトウェアエンジニアリング本部 テクニカルエバンジェリスト 藤本浩介氏ここから、日本マイクロソフト、コマーシャルソフトウェアエンジニアリング本部テクニカルエバンジェリストの藤本浩介氏により、今回の竹中工務店のプロジェクトにおいて活用された機械学習の技術要素、チューニングのテクニックなどが紹介された。
藤本氏はセッションの中で、主に技術面でのテクニックとして、開発作業を効率化する方法と、モデルの精度を向上させるためのコツについて触れた。
開発作業を効率化する方法
今回のプロジェクト期間は約2カ月間。そのうちモデル生成に費やすことができた時間は2週間ほどだったという。限られた期間の中での開発作業をいかに「効率化」するかは、重要なテーマだった。
- 【1】Pythonライブラリ「Keras」と「Azure Machine Learning Services」の「Workbench」画面を活用
機械学習用のPythonライブラリとしては「Keras」が用いられており、利用したソースコードなどは藤本氏のGitHubリポジトリで公開されている。
「Keras」を採用した理由も「使いやすい高水準ライブラリであり、迅速なプロトタイプ作成が可能」「人気のあるOSSであり、参照できるサンプルコードが豊富」といった点で効率化が見込めたためだとする。
また、大量に実施される実験や学習のジョブ管理、生成されるログや出力ファイルの管理を効率化するに当たっては「Azure Machine Learning Services」の「Workbench」画面を活用したという。

- 【2】1万枚の画像を用途に分けて利用
モデルの生成には、竹中工務店が選別した1万枚の画像のうち、7000枚を実際の学習(トレーニング)に、2000枚をモデルのチューニング(バリデーション)に、1000枚を最終評価(テスト)に利用した。
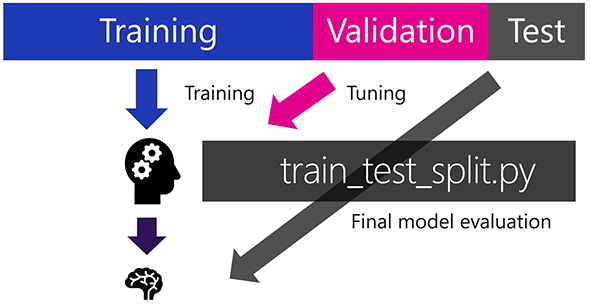
「実際には、これよりも少ないデータ量でも学習は可能。機械学習には大量のデータが必要だと思っている人も多いようだが、近年では学習にかかる時間とデータ量を減らす手法も研究が進んでいる」(藤本氏)
- 【3】「転移学習」(Transfer Learning)
「学習に必要な時間とデータ量を減らす」ために、今回のプロジェクトで活用されたのが「転移学習」(Transfer Learning)と呼ばれるテクニックだ。転移学習では、ある特定の領域で学習させた既存のモデルを、他の領域に適応させることで時間と必要なデータ量を削減できる。

今回は「建設現場で撮影された画像の19カテゴリーへの分類」を行うモデルを作成するために、一般に公開されている画像識別のモデルをベースとして、より深層の学習を、先ほどの7000枚の画像データを使って行ったという。
モデルの精度を向上させるためのコツ
転移学習の結果として得られたさまざまな指標は、Azure Machine Learning ServicesのWorkbench画面でグラフやテーブルとして一覧できる。ここで結果を確認しながら、より精度を高めるためのチューニングを進めていく。
- 【1】データセットのバランス
まず確認すべきポイントとして挙げられたのは「データセットのバランス」だ。実環境から用意したデータセットには、多くの場合、何らかの偏りがある。今回のケースでは、分類したい19カテゴリーのうち、特定のカテゴリーに属する画像が他のカテゴリーよりも多く学習用データセットに含まれていた。このため、出現率が多いカテゴリーのデータに係数で重みを付け、全体のバランスが平均化するような措置を施したという。
- 【2】エポック数の増加
データセットのバランスが調整できたら、次に試してみる価値があるのは「エポック数の増加」だ。エポック数とは、トレーニングのためのデータセットを繰り返して学習させる回数のこと。一般的に、エポック数を増加させることでモデルの精度は上がる傾向がある。しかし、当然のことながらトレーニングにかかる時間は増加する。
「この段階では、さまざまなパラメーターを細かく調整しながら学習を繰り返し、結果を比較検討するプロセスを、できるだけ多く実行したい。エポック数増加に伴って増加する学習時間を短縮するために、『GPUによる分散処理』を最大限に活用すべき」(藤本氏)
- 【3】複数GPUで分散処理
学習に使うGPUを強化するほど、リソースにかかるコストは上がる。しかし、学習時間は劇的に削減することができ、モデルの精度を高められる可能性も上がる
「機械学習においてGPUは正義。実質的に、GPUリソースに割いたコストは最終的な成果で十分に補えると感じている」(藤本氏)
- 【4】Data Augmentation
モデルのチューニングに当たって利用できる他のテクニックとして藤本氏は「Data Augmentation」を挙げた。これは、画像認識の場合には学習データを回転(Rotate)させたり、ひっくり返したり(Flip)することで、見掛け上のデータ量を水増しする手法だ。今回のプロジェクトでは、残念ながらData Augmentationによる精度の目覚ましい向上は見られなかったそうだ。

「モデルの精度がどう変化するかは、実際にやってみないと分からない。まずは試してみるべき」(藤本氏)
- 【5】「Learning Rate」(学習率)を調整
こうした過程を経て、ある程度まで精度の向上が確認できたら、最終的に「Learning Rate」(学習率)を調整し、過学習による結果の不安定さを解消する段階に進む。プロジェクトでは、転移学習直後にはトレーニングデータに対して60%弱だった識別精度を、最終的に、トレーニングデータに対しては97%、未知のデータに対しては92%にまで向上させ、実用可能と判断したという。
「これ、AIで何とかならないの?」は絶好のチャンス
セッションの最後には、再び竹中工務店の高井氏が登壇し、藤本氏とそれぞれに、機械学習に取り組もうとしているエンジニアへエールを送った。
「現在、多くの企業で『これ、AIで何とかならないの?』と言われるケースが増えていると思う。技術によって難しい課題の解決に結び付くブレークスルーを起こせるのは、ビジネス側のニーズと技術の双方を理解している人間、つまり社内のエンジニアだけ。もし、そうした機会があれば、「絶好のチャンス」と捉えて問題の解決に前向きに取り組んでほしい」(高井氏)
「機械学習を業務に取り入れていくためには、ビジネスとテクニカルの両面で取り組みを行う必要がある。特にテクニカルな面では、やってみなければ分からないことも多いので、やると決めたら、まずは走り出してほしい。このセッションが、そのためのヒントとなることを願っている」(藤本氏)
関連記事
 オランダの企業が、サッカーのデータ化で選手の移籍に影響力を及ぼし始めている
オランダの企業が、サッカーのデータ化で選手の移籍に影響力を及ぼし始めている
サッカー選手に焦点を当てたアナリティクスを通じ、選手の移籍に影響力を与え始めている企業がある。また、同社はさらに試合をリアルタイムにデータ化するシステムを構築、サッカーに新たな世界をもたらそうとしている。 約1000人の機械学習/AI人材を育成、パナソニックの全社展開における課題とは
約1000人の機械学習/AI人材を育成、パナソニックの全社展開における課題とは
パナソニックは、事業のデジタル化でディープラーニング/AIにどう取り組んでいるか。パナソニックビジネスイノベーション本部AIソリューションセンター 戦略企画部部長の井上昭彦氏が、DataRobotのイベントで語った内容をお届けする。 データサイエンティストと東京電力グループのデジタライゼーション
データサイエンティストと東京電力グループのデジタライゼーション
「世界でここでしか手に入れることのできないデータがあるから」という理由で東京電力グループに入ったデータサイエンティストの大友氏は、巨大な組織の中でいわゆるMVP、小さな成果を積み重ねる活動を進めようとしている。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。