ニューラルネットワークライブラリTensorFlow/Kerasで実践するディープラーニング:Pythonで始める機械学習入門(8)(3/3 ページ)
定義したネットワークの構造の確認
summaryメソッドを使って定義したネットワークの構造を確認できます。
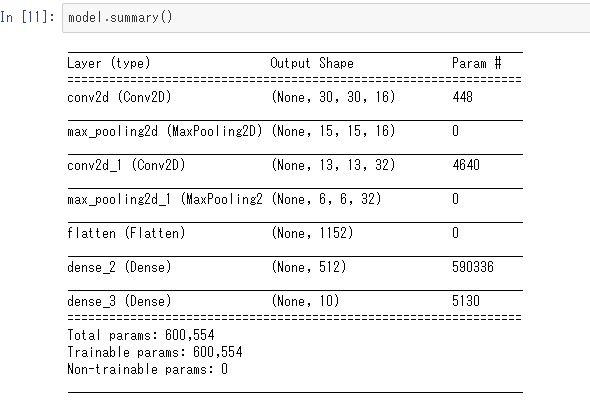
各層の出力のサイズとパラメーターの数が表示されました。最適化アルゴリズムと損失関数の指定はあやめデータの場合と変わらず、次のように指定します。

学習の実行
次に、学習させます(この実行には数分かかります)。

こうして学習させたものをファイルに保存することもできます。「HDF5」という形式で保存します。
このときに次のようなエラーが出ることがあります。
ImportError: `save_model` requires h5py.
このときは「h5py」(HDF5 for Python)ライブラリをインストールします。シェルから次のように入力するとよいでしょう。
> pip install h5py
次に保存したファイルを読み込んでみます。
変数model_loadedにファイルから学習済みモデルが読み込まれました。
実行結果
テスト用データに適用してみて、どのくらい当てることができるかを調べてみます。

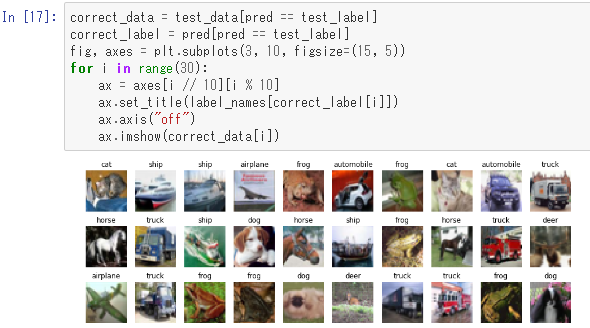
約66%の正解率になりました。では実際に正解したデータと不正解のデータの中身を見てみましょう。まずは正解データの最初の30個をラベル付きで可視化してみます。
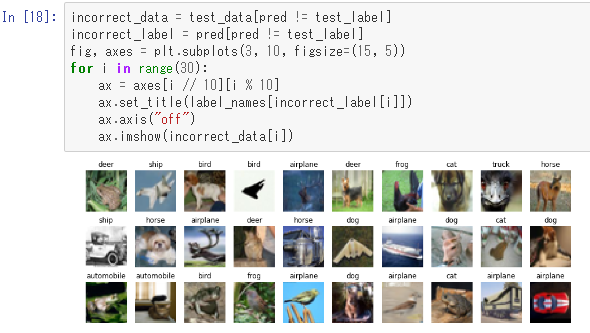
次に、不正解データをラベル付きで表示してみます。ここで付いているラベルは間違って付けたラベルです。
説明用のサンプルとしてはここまで
以上、cifar10の画像データの分類をTensorFlowで実装してみました。ここでの実装は説明のためシンプルなものを採用し、計算時間もそれなりに短時間に終わるようにしているため、正解率は約60%台にとどまっています。実際にこれ以上の精度を出そうとするとネットワーク構造やアルゴリズムをさらに工夫した上で計算リソースもそれなりに消費する(つまり長時間計算するかまたはGPUのようなパワフルな装置を利用する)ことになります。
最高精度を出したアルゴリズムがこのページで確認できますが、2018年10月の本稿執筆時点だと2015年に96.53%の正解率を達成したのが最高記録として記載されています。どのようなモデルで、そのような記録を達成できたのかについては、該当ページから論文へのリンクが貼ってありますので参考にしてください。
まとめ
今回は、あやめデータの分類と画像の分類を例に、TensorFlow/Kerasの使い方を説明してきました。
ディープラーニングはこれ以外にも多くの分野に適用できますが、画像認識は典型的な例の一つであり、ディープラーニングの威力をすぐに感じることができる分野になっています。
それぞれのアプリケーションに対して、どのようなモデル(ネットワーク)を構築すべきかについては、さまざまな論文や書籍で情報を得て利用することになります。
関連記事
 Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intelは、「Intel Xeonスケーラブルプロセッサー」上で「TensorFlow」を使用するデータサイエンティスト向けに、フレームワーク非依存のディープニューラルネットワークモデルコンパイラ「nGraph Compiler」のパフォーマンスを高めるブリッジコードを提供開始した。 NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
「NVIDIA TensorRT」とオープンソースソフトウェアの機械学習ライブラリの最新版「TensorFlow 1.7」が統合され、ディープラーニングの推論アプリケーションがGPUで実行しやすくなった。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。