機械学習の適用範囲を大幅に拡張、理研が手法を確立:自社商品を購入しなかった人のデータも推定
理化学研究所の研究チームは、いわゆる「負のデータ」を収集できないために機械学習の分類技術を適用できなかった分野でも、分類技術が利用可能になる手法を確立した。「正のデータとその信頼度情報」だけから、分類境界を学習する。
理化学研究所(理研)は2018年11月26日、データを「正」(当てはまる)と「負」(当てはまらない)の2つに分ける機械学習の分類問題について、正のデータとその信頼度(正信頼度)の情報だけから、分類境界を学習する手法を開発したと発表した。
これまで負のデータを収集できないために機械学習の分類技術を適用できなかった幅広い分野でも、分類技術が利用可能になる。
開発したのは同研究所の革新知能統合研究センター不完全情報学習チームに所属する研修生の石田隆氏(東京大学大学院新領域創成科学研究科博士課程)と研究員のガン・ニュー氏、チームリーダーの杉山将氏の研究チーム。
弱い「教師あり学習」を改善
機械学習の分類技術とは、手書き文字認識や画像認識、迷惑メール検知、文章の意味認識などに用いられる技術。一般に、値が分かっている教師データを使ってあらかじめ学習させておき、値が未知のデータを分類する(教師あり学習)。例えば乗用車とトラックの画像を分類するには、あらかじめ教師データとして乗用車(正のデータ)とトラック(負のデータ)の画像を多数用意して学習させる。
このように、一般に機械学習の分類技術を用いるには、正と負の両方のデータを用意する必要がある。別の言い方をすると分類技術の学習とは、正のデータと負のデータの境界に引く「線」を、複数の教師データを使って決定することだ。その際、教師データをAIが分類した値と、実際の正しい値との差を、繰り返し処理によって最小化する。
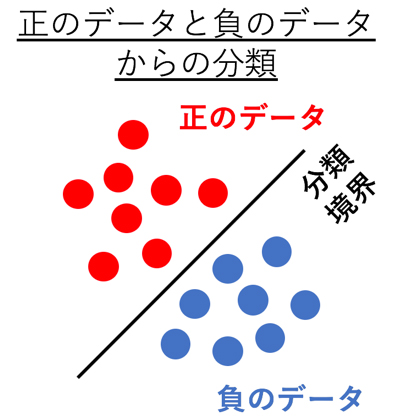 分類技術の学習では、正のデータと負のデータの間に分類境界(線)を決定する(
分類技術の学習では、正のデータと負のデータの間に分類境界(線)を決定する(だが現実の問題では、負のデータを収集できない場合がある。例えば購買予測では、顧客が過去に自社商品を購入したデータ(正のデータ)は集められるが、ライバル商品を購入したデータ(負のデータ)は集められない。石田氏らの研究チームが開発した手法は、こうした場合でも正信頼度情報さえあれば、分類境界を学習できるようにした。
信頼度とは、「正のデータがどれだけ正のデータらしいか」を示す情報で、そのデータが正のクラスに属する確率に相当する。例えば購買予測では、過去に自社商品を購入したときの顧客の購買意欲から得られる。
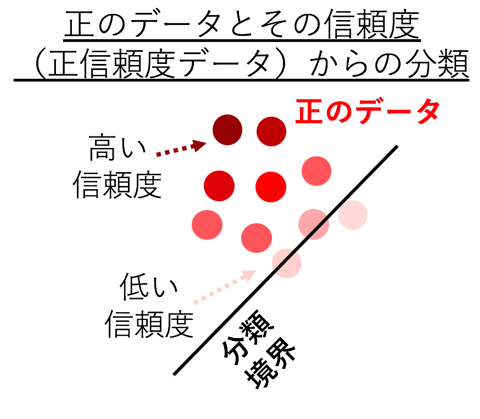 正のデータとその信頼度(正信頼度)だけから分類境界を決める(
正のデータとその信頼度(正信頼度)だけから分類境界を決める(正の信頼度から負の値を導く
正信頼度を利用して分類境界を学習させるに当たって、同研究チームでは、正と負の両方のデータを使って学習させた場合の分類リスク(あるデータに対してAIが予測した値と実際の値との誤差を求める関数の期待値)を、正のデータとその信頼度で表現した。
例えばあるデータの信頼度が90%の場合は、「正のデータ90%」と「負のデータ10%」の重みが付けられた正と負2つのデータに分解する。すると、分類リスクを正のデータとその信頼度だけで表すことができた。この分類リスクを最小化することで、正のデータとその信頼度だけから精度良く学習できる。
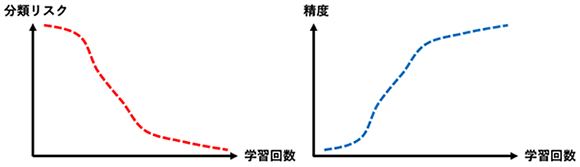 学習回数を増やすことで分類リスクが下がり、精度が高まる(
学習回数を増やすことで分類リスクが下がり、精度が高まる(さらに同研究チームは理論解析によって、この方法が統計的に望ましい性質(十分多いデータ数があれば最適な分類器が得られるという一致性など)を持つことを証明した。
理論だけでなく、データでも手法の有効性を確認している。ベンチマークとなるデータセットを用いた実験によって、うまく学習できることも示した。開発した学習アルゴリズムは、線形モデルや深層学習モデル(ディープラーニング)など、あらゆる分類モデルと容易に組み合わせられるという。
研究チームでは、分類技術は自然言語処理やコンピュータビジョン、ロボティクス、バイオインフォマティクスなど、さまざまな研究分野で活用されており、今回開発した正信頼度を用いた分類に対しても、今後さまざまな応用研究が行われることを期待している。そのため、実験で使用したPythonによるアルゴリズムの実装コードを、Webサイト上で公開する予定だ。
関連記事
 機械学習向け教師データ作成ツール、TISがオープンソースで公開
機械学習向け教師データ作成ツール、TISがオープンソースで公開
TISは機械学習に向けた教師データ作成ツール「doccano」をオープンソースソフトウェアとして公開した。テキスト分類、系列ラベリング、系列変換という3つの基本的なタスクで使用するデータを作成しやすいという。 少ない学習データでも機械学習の効果を高める、NECが機械学習向け技術を開発
少ない学習データでも機械学習の効果を高める、NECが機械学習向け技術を開発
NECは、学習データが少ない場合の機械学習効果を高める技術を開発した。データ収集の初期段階やデータ収集コストが高い環境のように十分な学習データが得られない状況でも、機械学習技術を活用できるという。 人工知能はどうやって「学ぶ」のか――教師あり学習、教師なし学習、強化学習
人工知能はどうやって「学ぶ」のか――教師あり学習、教師なし学習、強化学習
Pepperや自動運転車などの登場で、エンジニアではない一般の人にも身近になりつつある「ロボット」。ロボットには「人工知能/AI」を中心にさまざまなソフトウェア技術が使われている。本連載では、ソフトウェアとしてのロボットについて、基本的な用語からビジネスへの応用までを解説していく。今回は、人工知能つまりコンピュータが「機械学習」という技術を使って、どうやって学習していくのかについて具体例を交えて解説する。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。