勉強会で明らかになった医療向けOSSの多様な活用法──電子カルテ、臨床試験データ解析、日本語医学用語プラットフォーム、画像DB:ヘルスケアだけで終わらせない医療IT(6)(3/4 ページ)
2015年7月4日に東京で開催された「第10回 医療オープンソースソフトウェア協議会セミナー」の講演を基に、医療分野でOSSがどのように重要な役割を担いつつあるのかをリポートする。
【Myna】OSSを駆使して日本語医学用語プラットフォームの構築に挑む
愛媛大学 医療情報部の木村映善氏が「医療ターミノロジー Web Services」と題して行った報告では、米国に大きく後れを取ってきた国内の医学用語プラットフォームの整備を迅速に進めることを目指して、OSSを駆使した日本語医学用語プラットフォーム「Myna」の構築に向けた取り組みを開始していることが明らかにされた。
Mynaの特徴は、米国の医学用語プラットフォームとは異なり、UbuntuやVagrant、MySQL、Ruby、Rails、GrapeなどのOSSや、OSSの開発・公開手法を徹底的に活用して構築を進めていることだ。2015年秋には、英語〜日本語の機械的照合を行った用語を数十万語レベルで公開する予定で、コミュニティの力を結集して洗練化作業を進めていく。ただし、ライセンス・著作権関係の問題がクリアになるまでは、クローズドな管理者登録制による公開となる。

Mynaは、大きく三つのコンポーネントで構成されている。一つは、国際医学用語データベース「SNOMED CT」を基に英語と日本語をマッピングしたSNS指向のターミノロジ(用語体系)データベースである。木村氏は「このデータベースを公開し、コミュニティの力でブラッシュアップしていく」と説明している。
コンポーネントの二つ目は、医療プロセスと直結する情報参照モデルを提供する「OpenEHR」や、REST/JSONベースで構築された医療情報リソース「FHIR(Fast Healthcare Interoperability Resources)」などとAPI連携できるターミノロジー・サービス。そして三つ目は、一般ユーザーが利用できる医学辞書として提供するデータ配布サービスである。
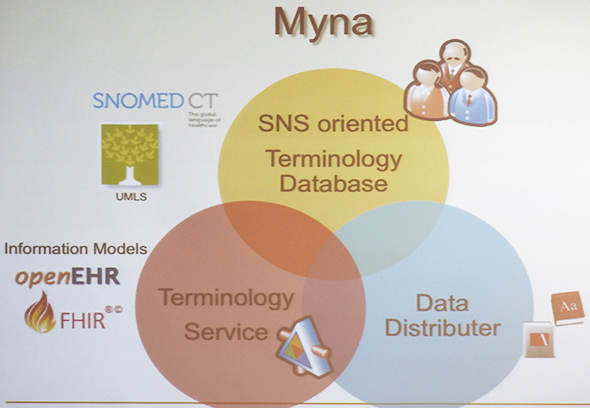
ちなみに、Mynaという名称は、言葉を話せるムクドリ科の鳥を由来としており、世界中で見られる鳥であることから採用されることになったという。
米国に後れを取る日本の医学用語環境
Mynaの開発が始まった背景には、医学用語プラットフォームの構築および活用で米国に大きく後れを取っているという現実がある。米国では、すでに20年も前から、NLM(米国国立医学図書館)が医学用語を統一的に網羅する統合医学用語システム「UMLS(Unified Medical Language System)」を構築しており、毎年およそ2000万ドル規模の予算が投じられてきた。UMLSでは、2015年現在、純粋な概念で311万個、言葉の揺れを含む医学用語で1200万個に上っている(図)。
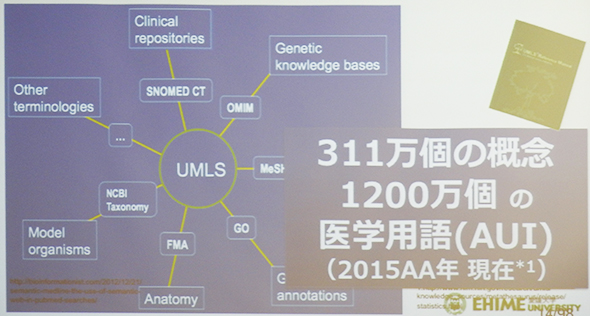
一方、日本の事情はどうか。木村氏によると、国内でも過去に、厚生労働科学研究の一環として、シソーラス(概念分類辞書)の整備が進められ、日本医学用語辞典という形で公開されているが、プロプライエタリなデータベースにすぎず、OSSでの活用はできないという。

医学用語プラットフォームにおける、20年で累計数億ドルという大きな後れをどのように取り戻せばいいのか。木村氏は、「Bazzarモデルを採用して、コミュニティの力を結集すれば後れを取り戻せる可能性がある」と強調する。
木村氏の言うBazzarモデルとは、OSS開発思想を論じたEric S. Raymond氏の論文『The Cathedral and the bazzar(伽藍とバザール)』を参考にしたもので、OSSの開発モデルを指す。一方、プロプライエタリな開発モデルはCathedralモデルということになる。
UMLSは、データこそ公開されているが、開発モデルで見ると、特定分野の専門家集団が国家的なインフラとしてプロプライエタリな環境で開発を進めるCathedralモデルであり、Bazzarモデルによって専門の医師を引き込みながら、コミュニティが力を結集して取り組めば十分に対抗できるというわけだ。
木村氏によると、オープンソースのモデルをベースとするBazzarモデルによって概念・知識データベースを構築する取り組みとしては、すでに二つの先例があるという。一つは、有志が集まって医学用語のセマンテック・ネットワークを構築・公開している欧州の「OpenGALEN」。もう一つは、医療情報をアークタイプという情報単位にまとめて公開している同じく欧州の「OpenEHR」である。OpenEHRでは、クリエイティブ・コモンズに基づいて、コミュニティの成果物であるアークタイプを一般の利用者に使用許諾するライセンシングが行われている。
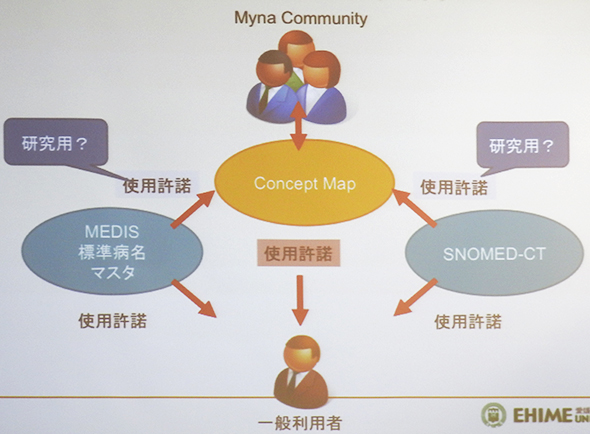
木村氏によると、Mynaプロジェクトでは、MEDIS(医療情報システム開発センター)の標準病名マスターや国際医療用語集の「SNOMED-CT」という異なるライセンシの成果物を基にコミュニティの手でコンセプトマップを構築することを予定している。Mynaを正式に公開するに当たっては、これらのライセンスの問題を解決しておく必要がある。現在、クリエイティブ・コモンズなどの取り組みを参考にできるか、権利をどこに帰属させるのかなど、ライセンスの問題の解決に向けた取り組みを進めているという。
用語環境の整備がWatsonの医療活用を後押し
医学用語プラットフォームの後れは日本の医療IT全体の発展にマイナスの影響を与えている。その代表例が、人工知能(AI)の活用である。
米国では、すでにIBMが開発した「Watson」が医療分野で用語システムと連携する形で本格的に活用され始めている(詳細は「Watsonはスマートフォン/ウェアラブル端末で収集したユーザーデータの活用で医療ITを革新できるのか」を参照)。木村氏は、「IBM Watsonが、実際に電子カルテ上でがん患者に投与するのに適切な抗がん剤をマッチングさせているのを見て、“黒船来航”のような衝撃を受けた。日本でのAIの活用は20年ほど前から失敗の連続で、実際に使えるとは思っていなかった」と説明する。
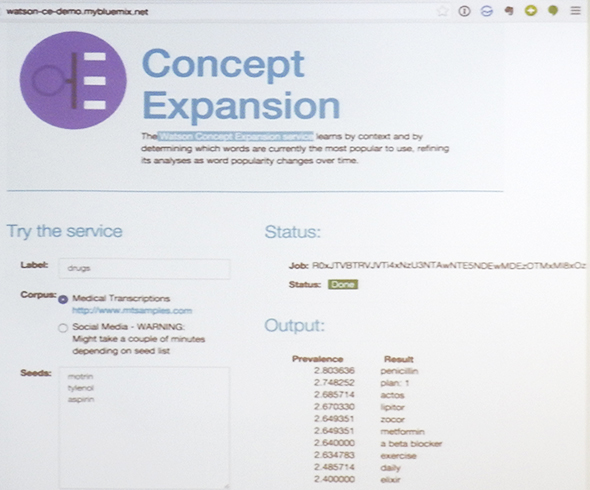
Watsonがクラウド上で提供しているサービスのうち、木村氏がとりわけ注目しているのが、「Concept Expansion」というサービスである。これは、自然言語の文を解析する際に、概念的に近い単語を自動的に収集する機能を提供するものだ。木村氏は、一定量の英語文を流し込んで、「drag」という単語に近い概念を解析させてみたところ、「ペニシリン」が薬に関係するものだということをまったく教えていないにもかかわらず、高いスコアで「penicillin」という結果が導き出されたというデモ事例を紹介した。
しかし、木村氏によると、Watsonのサービスは「それぞれの単語を概念として理解する『強いAI』ではなく、質問されたキーワードに近い単語を共起(同時に出現する距離)または出現頻度を基に、概念的に近い単語を導き出す『弱いAI』にすぎない」という。当然、臨床現場においても、臨床概念を理解するわけではないため、医師の“臨床判断に必要な情報”は提供できるものの、“臨床判断そのもの”は代替することはできない。
強いAIは、概念をキチンと理解して、類推/推論、問題解決する「オントロジ(Ontology)」機能を使って、あらゆる単語や概念の関係を、細かく追求していくことによって、人間に近い臨床判断を可能にするものだ。日本でも20年も前から研究が進められきたが、実用化には至っていない。
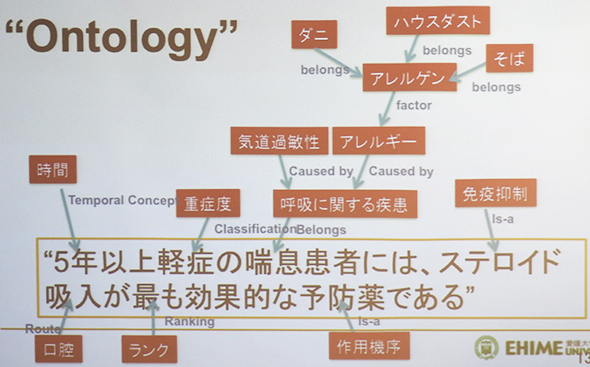
Watsonは、弱いAIの機能と、統合医学用語システムのUMLSや生物医学系文献データベースのMEDLINE、ライフサイエンス特許文書などを連携させることによって、強いAIに匹敵する高いAI性能を引き出し、高度な診断支援を実現している。残念ながら、日本にはこのような語彙・概念リソースは整備されておらず、医療ITで大きな後れを取っているのが現状だ。Mynaプロジェクトによって、こうした後れが早急に克服されることが期待される。
関連記事
 Apple Watchやゲノム解析とも連携――「クラウド型電子カルテ」をプラットフォームとする新しい「医療」の可能性
Apple Watchやゲノム解析とも連携――「クラウド型電子カルテ」をプラットフォームとする新しい「医療」の可能性
日本で構築が急がれている「地域包括ケアシステム」の重要な基盤と考えられている「電子カルテ」システム。クラウド型電子カルテが医療データ蓄積のためのプラットフォームとなることにより、医療そのものの進化を後押しする可能性も生まれているという。 Watsonはスマートフォン/ウェアラブル端末で収集したユーザーデータの活用で医療ITを革新できるのか
Watsonはスマートフォン/ウェアラブル端末で収集したユーザーデータの活用で医療ITを革新できるのか
「IBM Watson」は、スマートフォンやウェアラブル端末などのデバイスから収集したデータと、電子カルテや遺伝子情報などの膨大な医療情報とを有機的に結び付けて医療現場の活動を支援できる認知システムとして注目を集めている。本稿では、2015年5月19日、20日に東京で開催された「IBM XCITE SPRING 2015」での講演内容を基に、IBM Watsonがどのように進化し、医療やライフサイエンス分野で活用されようとしているのかを紹介する。 スマートデバイスからのログ、病院DB、医療機器から得る画像――医療現場のビッグデータ活用を実践する3社の事例
スマートデバイスからのログ、病院DB、医療機器から得る画像――医療現場のビッグデータ活用を実践する3社の事例
医療、ヘルスケアに関連したテクノロジビジネスやスタートアップの動向を、エンジニアやビジネスマンに対して紹介するイベント「Digital Health Meetup Vol.2」のピッチセッションから3社の医療ベンチャーが開発したサービスやアプリの事例をお伝えする。 現役医師や医療ベンチャーが語る、医師会、IT活用、超高齢者、そして未来へ
現役医師や医療ベンチャーが語る、医師会、IT活用、超高齢者、そして未来へ
医療、ヘルスケアに関連したテクノロジビジネスやスタートアップの動向を、エンジニアやビジネスマンに対して紹介するイベント「Digital Health Meetup Vol.2」のパネルディスカッション「医療革命! 医師のIT活用とその未来について」の模様をお伝えする。 2025年問題、マイナンバー、改正薬事法――開発者が「唯一の成長市場」ヘルスケア/医療に参入する際の課題とは
2025年問題、マイナンバー、改正薬事法――開発者が「唯一の成長市場」ヘルスケア/医療に参入する際の課題とは
医療、ヘルスケアに関連したテクノロジビジネスやスタートアップの動向を、エンジニアやビジネスマンに対して紹介するイベント「Digital Health Meetup Vol.2」の講演「医療政策の動向から読み解く、これからの医療・介護業界」の模様からヘルスケア/医療業界に横たわる課題をまとめてお伝えする。 医療×IT 医師はプログラミングで医療の仕組みを変えられるか
医療×IT 医師はプログラミングで医療の仕組みを変えられるか
プログラミングはプログラマーだけの特権ではない?――ITを活用して自身の専門分野をより良くしていこうとチャレンジしている人たちにお話を伺うインタビューシリーズ、本日始動。 アップルがGitHubに公開した医療の研究調査用OSSフレームワーク「ResearchKit」の基礎知識
アップルがGitHubに公開した医療の研究調査用OSSフレームワーク「ResearchKit」の基礎知識
米アップルが2015年4月14日にGitHubに公開した医療の研究調査用OSSフレームワーク「ResearchKit」について、概要や機能、現時点でできないこと、どのようなアプリが作れるかについて紹介する。 医者はIT技術を学び、エンジニアは医学を学ぶ時代
医者はIT技術を学び、エンジニアは医学を学ぶ時代
2013年8月31日、「10年後の医療」をテーマに日本各地から1000人の医学生が都内に集結。「Medical Future Fes 2013」が開催された。
Copyright © ITmedia, Inc. All Rights Reserved.