
共有メモリ型並列処理システムにおける並列化
共有メモリ型並列処理システムとは、すべての演算器が共通のメモリ空間にアクセスできるシステムで、Symmetric Multiprocessing(SMP)システムと呼ばれることもあります。
Quad Coreプロセッサを2ソケット搭載したサーバ製品はSMPシステムであり、この場合OSからは共通のメモリ空間に接続された演算器が8個見えることになります。大規模なスーパーコンピュータなどでは、CPUの数が64個や128個になるものもありますが、ハードウェアの構成上、それ以上の数のCPUを接続し、共通のメモリ空間にアクセスさせるのは難しいようです。
現在はSMPシステムのPCが一般的ですので、実際上は、分散メモリ型が複数の計算機間の並列化なのに対して、共有メモリ型は計算機内部のCPU間の並列化であると考えておけばよいでしょう。
MPIがデファクトスタンダードといえる分散型システムとは異なり、共有メモリ型では、並列化するためのツールやフレームワークはさまざまです。代表的なものをいくつか挙げてみましょう。
- プロセス間通信インターフェイス
- スレッドライブラリ
- OpenMP
- Intel Threading Building Block
このほか、前節で示したように通常分散メモリ型で使われるMPIを、1つの計算機内部の共有メモリ型の並列化にも使うことも可能です。
以下では、このうち、並列化を比較的簡単に実装でき、一般的にも広まっているOpenMPを紹介します。
OpenMP
OpenMPとは、共有メモリ型システムにおける並列化を効率よく行うことができるフレームワークです。1997年にOpenMP Version 1.0の仕様が策定されてから、徐々に進化を続け、最新の仕様書は2008年5月に公開されたVersion 3.0になります。
現在では、GCC、Intel C/C++、IBM XLC、Microsoft Visual C++など、主要なコンパイラによってOpenMPがサポートされています。MPIのように、別途ライブラリなどをインストールする必要はありません。
OpenMPでは、オリジナルのコードに対してプログラマが#pragmaで始まる指示文(Directive)を挿入し、コンパイラに対して並列化部分を明示的に指示します。コンパイラは指示文の指示どおりに並列化部分をスレッド分割し、並列処理を行うコードに変換してコンパイルします。本来、並列スレッドプログラミングを自分でやる場合は、スレッドの生成・消滅やデータの分割は自分で管理する必要がありましたが、OpenMPがその負担を削減します。
ただし、OpenMPは並列化部分のロジックやデータの依存関係を分析しているわけではありません。あくまでも、指示文のとおりにスレッド分割するだけです。よって、プログラマが間違った指示文を使っている場合は、結果も意図しないものになります。
OpenMPの特徴の1つに、通常の逐次処理コードと並列化されたコードを同一のコードで管理できることがあります。例えば、MPIを使ってオリジナルの逐次処理コードを並列化する場合、逐次処理コードを大幅に書き換えて、並列処理用のソースを別途書くことになりますが、OpenMPの場合、並列用と逐次用という2つのソースコードを書く必要はなく、コンパイラスイッチのオン・オフで出力の実行形式ファイルを逐次処理と並列処理に切り替えることができます。
つまり、コンパイルオプションでOpenMPのサポートをオフにした場合は、単に#pragma文が無視されて通常の逐次処理を行う実行形式を生成し、OpenMPのサポートをオンにした場合は、並列化された高速な実行形式を生成します。
では、リスト1のサンプルプログラムを、今度はOpenMPで並列化してみましょう(リスト3)。
001: /*
002: * Array のインクリメント(OpenMP版)
003: */
004:
005: #include<stdio.h>
006: #include<stdlib.h>
007: #include<omp.h>
008: #define N 16
009:
010: int main (int argc, char *argv[])
011: {
012: int i;
013: int *rootBuf;
014: int num_of_threads;
015:
016: if(argc!=2){
017: printf("usage: a.out <number of threads>\n");
018: return(1);
019: }
020:
021: num_of_threads = atoi(argv[1]);
022: omp_set_num_threads(num_of_threads);
023:
024: rootBuf = (int *)malloc(N * sizeof(int));
025:
026: /* 配列Initialize */
027: for(i=0;i<N;i++){
028: rootBuf[i] = i;
029: }
030:
031: /* 並列処理の開始 */
032: #pragma omp parallel
033: printf("Exec by thread 0 (total 0 threads)\n",omp_get_thread_num(), omp_get_num_threads());
034: #pragma omp for
035: /* Incriment */
036: for (i = 0; i < N; i++) {
037: rootBuf[i] = rootBuf[i] + 1;
038: }
039:
040: /* 演算結果の出力 */
041: printf("\n");
042: for (i = 0; i < N; i++) printf("rootbuf[%d] = %d\n",i,rootBuf[i]);
043:
044: /* 終了処理 */
045: free(rootBuf);
046:
047: return(0);
048: }OpenMPに関しても、今後の連載で1記事設けて詳しく説明したいと思っていますので、ここでは簡単なコメントのみ挙げます。
- 007行目:
- "omp実行時ライブラリ関数"を使うために必要なインクルードファイルです
- 022行目:
- この関数の呼び出し以降の並列領域におけるスレッド数を規定します。この関数は、コードの逐次実行部分から呼び出された場合にのみ有効です
- 032行目:
- このpragma文以降が並列化されます
- 033行目:
- 各スレッドで、総スレッド数と各スレッドのスレッド番号をprintfします
- 034行目:
- このpragma文直後のforループが適切なループサイズで並列実行されます
MPIと比べると修正量は大幅に少なく、直観的にも分かりやすいかと思います。OpenMPオフィシャルサイトで、日本語に翻訳された仕様書が手に入りますので、詳しくはそちらを参照下さい。
また、より本格的に勉強したい方には、『Using OpenMP: Portable Shared Memory Parallel Programming』(Barbara Chapmanほか著)をお勧めします。こちらは洋書になってしまいますが、OpenMPのチューニングにフォーカスした秀逸な教科書です。リスト3の処理の概念図を図5に示します。あわせて参考にして下さい。
●リスト3(OpenMP)の処理の概念図
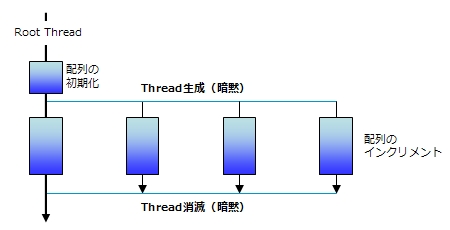
実際にコンパイルして実行するには、リスト3のソースコードファイルをlist3.cとして、以下のようにします。
適宜、最適化オプションなども併用してください。021行目を見ていただければ分かるように、コマンドライン引数として生成するスレッド数を取ります。実際にスレッド数を変えたり、Nを大きくしてみたりしながら、実行時間が変化することを確認してみてください。
以上、「Think Parallelで行こう」の第1回、いかがだったでしょうか。今回の記事は、「並列化とは」からスタートして、分散型並列処理システム、共有型並列処理システム、それぞれで代表的な並列化フレームワークであるMPIとOpenMPを紹介しました。
詳細な説明は省きましたが、両フレームワークの違いについては理解いただけたかと思います。しかしながら、実験されると分かるのですが、MPI版もOpenMP版も、今回の課題では演算処理が軽すぎて、並列実行しても実行速度はほとんど改善できません。
もし余力のある方は、ループ内部の処理をより複雑な処理に変えてみてください。十分な計算負荷がある場合は、スレッド数に従って計算速度が改善されていく様子が分かると思います。MPIとOpenMPのより具体的な高速化手法については、本連載の今後の記事をお待ちください。
次回は「マルチプロセッサ概説」と題して、最新のマルチコアプロセッサの特徴について、解説します。では、また次回までごきげんよう!
3/3 |
| Index | |
| 並列処理を体感してみよう | |
| Page1 いまだからこそ“Think Parallel” 並列処理手法とは何か |
|
| Page2 分散メモリ型並列処理システムにおける並列化 Message Passing Interface |
|
| Page3 共有メモリ型並列処理システムにおける並列化 OpenMP |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





