
Single Instruction Multiple Data
スーパースカラーでは、実行ユニットの並列化にあわせて命令デコーダも並列化する必要がありました。実行を高速化したいだけなのに、命令デコーダも並列化する必要があるのは少し無駄なように思われます。なんとかならないのでしょうか。
デコーダを並列化しなければならない理由は、複数の処理を実行するには複数の命令が必要だからです。それならば、一命令で複数の処理をしてしまえば命令デコーダを並列化する必要がなくなるのではないか、という気がします。
この一命令で複数の処理をしてしまうというのを実現したハードウェアがSIMD(Single Instruction Multiple Data)です。SIMDは実行ユニットだけを並列化したものです。このブロック図を図3に示します。
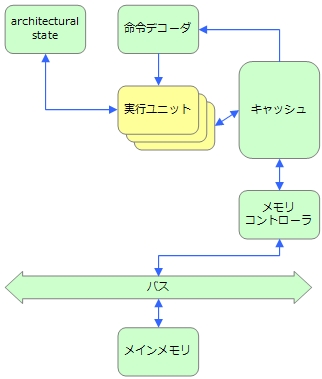
SIMDを実装したハードウェアでは、SIMD命令と呼ばれる「1つの命令で複数のデータを処理する命令」が用意されています。例えば、x86のSIMD実装であるSSEの加算命令addpsを使うと、4個の単精度浮動小数値に対して加算を行うことができます。
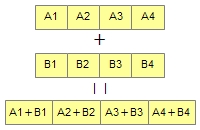
この処理のイメージ図を図4に示します。画像処理などでは複数のデータに対して同じ処理を行うことが多いため、SIMDを使えば効率良く処理することができます。
ただし、SIMDは明示的にSIMD命令を使わなければ活用することはできません。この命令を使うようにソフトウェアを書き換える必要があります。標準のC言語では、これらの命令を使う方法がないので、SIMD命令を使うようにソフトウェアを書き換える場合は、コンパイラの拡張機能を使うか、もしくはアセンブリプログラムを直接書く必要があります。
x86のSIMD命令であるSSEを使うプログラム例をリスト3に示します。配列に含まれる32ビット単精度浮動小数値の加算をしています。
001: #include <emmintrin.h>
002: void add_array(__m128 *out, __m128 *x, __m128 *y, int n) {
003: for (int i=0; i<n; i++) {
004: out[i] = _mm_add_ps(x[i], y[i]);
005: }
006: }- 001行目:
- SSEを使うために必要なコンパイラ拡張ヘッダです
- 002行目:
- __m128はSSEで使うデータ型を示す型です
- 004行目:
- _mm_add_psは4つの浮動小数値の加算を行う関数です。コンパイラによってSIMD命令addpsに変換されます
実際のSIMDプログラミングについては次回以降詳しく解説する予定ですので、しばらくお待ちください。
マルチコア・マルチプロセッサ
SIMDやスーパースカラーは、1つのタスクの中の処理を並列化するもので、まったく違うタスクを並列実行するのには向いていません。例えば、1000回のループを行う処理と3回のループを行う処理を同時に実行するのはかなり困難です(不可能ではないですが)。
ループ回数の違う処理を並列に実行するには、それぞれのタスクが独立してループ処理を行う必要があります。また、複数のタスクをそれぞれ独立したOSのプロセスとして実行する場合は、各タスクはOSによって保護される必要があります。
例えば、動画の再生とウィルススキャンを並列に実行する場合に、動画プレイヤーのバグがウィルススキャンの動作に障害を起こすようなことがあってはいけません。
つまり、複数の処理を実行する場合、それぞれのタスクごとに独立したループ制御やメモリ保護が必要な場合があるのです。
そこで、ループ制御やメモリ保護なども含めて、1つのプロセッサと同じ機能を持つものを並列化したものがマルチコア、マルチプロセッサになります。
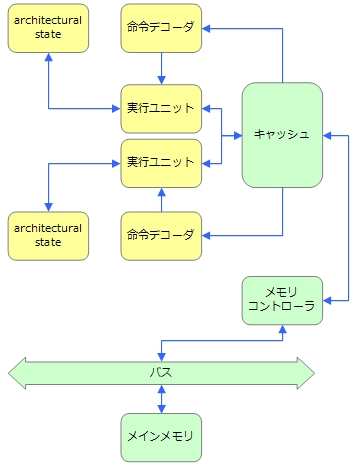
マルチコアは、architectural state、命令デコーダ、実行ユニットを並列化したものです。
マルチプロセッサは、architectural state、命令デコーダ、実行ユニット、キャッシュ、メモリコントローラ、バスを並列化したものです。
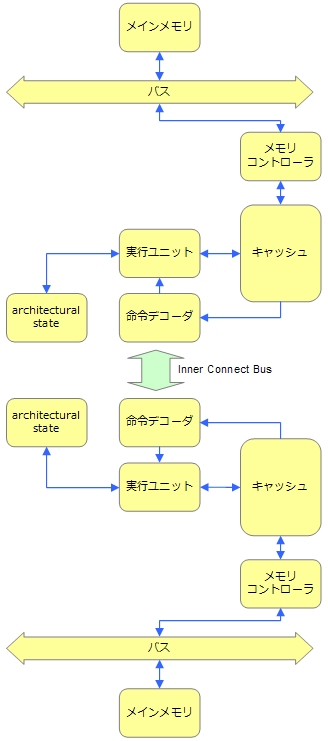
ただし、これらの分類はきちんとした定義に基づくものではありません。例えば、マルチコアでもキャッシュを並列化する場合もありますし、マルチプロセッサでもバスやメモリコントローラが並列化されないことがあります。
AMDのPhoenomが出たころ、対抗のCore2Quadと比較して「ネイティブクアッド」「真のクアッド」であるなどと宣伝されましたが、これはプロセッサメーカーによって、マルチコアの定義が違うことから出た言葉であるといえます。
ソフトウェアから見た場合にはマルチコアとマルチプロセッサは同じように見えますが、並列化されているハードウェアが違うために、性能に少し違いがあります。
NUMAマルチプロセッサと呼ばれるマルチプロセッサ環境では、メインメモリとの通信部分が並列化されているため、シングルプロセッサと比べてメインメモリとの通信性能は向上します。
しかし、キャッシュを別々に持っているため、プロセッサ間の通信を行う場合は、Inter Connect Busと呼ばれるプロセッサ間を接続するバスを通してデータ通信を行う必要があります。
マルチコアの性能はこの逆で、メインメモリとの通信は並列化されておらずコア数が増えてもメインメモリとの通信性能は上がりませんが、共有データをキャッシュ内に置いておくことができ、コア間の通信は、高速なキャッシュ内で行うことができます。
このマルチコア・マルチプロセッサの性能を活用するには、ソフトウェアを書き換える必要があります。一般的には、OSがこれを実現するためのインターフェイスを用意しており、それを通してプログラムを行います。
これがいわゆるマルチスレッドプログラミングになります。実際のマルチスレッドプログラミングについては次回以降詳しく解説する予定ですので、しばらくお待ちください。
2/3 |
| Index | |
| 現代のプロセッサと並列実行 | |
| Page1 マルチプロセッサ概説 いまどきのプロセッサの構成 スーパースカラー |
|
| Page2 Single Instruction Multiple Data マルチコア・マルチプロセッサ |
|
| Page3 ハードウェアマルチスレッド |
|
| Think Parallelで行こう!/font> |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





