
Cell Broadband Engine
Cell Broadband Engine(以下、Cell/B.E.)は、PLAYSTATION 3向けに、Sony、東芝、IBMが共同で開発したプロセッサで、ヘテロジニアスマルチコアであることが特徴のプロセッサです。
ヘテロジニアスマルチコアというのは、1つのプロセッサの中に違った種類のアーキテクチャを持ったプロセッサコアを実装したマルチコアプロセッサのことです。
Cell/B.E.には1つのプロセッサの中に「PPE(PowerPC Processsing Element)」と「SPE(Synergistic Processing Element)」という2種類の違ったアーキテクチャを持つプロセッサコアが実装されています。
なお、1種類のアーキテクチャで実装されたマルチコアはホモジニアスマルチコアと呼ばれます。Core2Quadなど、現在のx86プロセッサはホモジニアスマルチコアです。
Cell/B.E.がヘテロジニアスマルチコアプロセッサとして実装されている理由は、ホモジニアスマルチコア以上の高い演算性能を実現するためです。
マルチコアプロセッサでは、1つのプロセッサ内に多くのコアを搭載することによって演算性能を高めることができますが、プロセッサの大きさは無限ではありません。限られた面積の中に多くのコアを搭載するには、コア1個あたりのサイズを小さくする必要があります。
コアの持つ機能を減らせば、コアのサイズを小さくすることができますが、すべてのコアが同じ機能を持つホモジニアスマルチコアプロセッサでは機能を削るわけにはいきません。
それに対して、ヘテロジニアスマルチコアプロセッサは、特定の機能に特化したプロセッサコアというものを実装することが可能です。このため、プロセッサのサイズが同じくらいであった場合、ヘテロジニアスマルチコアプロセッサはホモジニアスマルチコアプロセッサよりも高い性能を実現できるのです。
Cell/B.E.では、PPEがメモリ管理や割り込みなどのシステムの制御処理に、SPEが演算処理にそれぞれ特化したプロセッサとなっています。PPEは、Linuxなどの汎用OSを実装できる機能を持っていますが、数値演算命令のレイテンシはi7と比較して3〜5倍程あります。
一方、SPEは(それなりに巨大な)汎用プロセッサと同等の数値演算性能を持っていますが、メモリ保護や割り込みを制御する機能は持ちません。
ヘテロジニアスマルチコアであることからも分かるように、Cell/B.E.の思想は少ない面積で高い演算性能を持つことです。これを実現するため、Cell/B.E.向けに新規に設計されたプロセッサコアであるSPEは、汎用プロセッサには見られない、いくつかの特徴的な点を持っています。
IBMが提供するホワイトペーパー『Introduction to the Cell Broadband Engine』には、in-order実行であること、ハードウェア分岐予測を持たないことなどが挙げられていますが、いくつかここで簡単に説明しましょう。
●ほとんどの命令がSIMD命令である
一般的なプロセッサは、通常の命令とSIMD命令の両方を持っているものが多いのですが、どちらも処理内容には大差なく、処理するデータの数が1つか複数かの違いしかありません。複数のデータを処理できるのであれば、1つのデータを処理できるはずですから、単純に考えた場合、SIMD命令があれば十分です。
既存のプロセッサでは過去のソフトウェアを動作させる必要があるため、通常の命令をサポートする必要がありますが、過去のソフトウェアが存在しないSPEでは、通常の命令をサポートする必要がありません。
このため、SPEは算術命令およびロードストア命令など、ほとんどの命令がSIMD命令として実装されており、1つのデータだけを処理する命令の数はほかのプロセッサと比べ少なくなっています。
●プロセッサコアごとに専用のメモリを持ち、メインメモリとのデータ転送はDMA転送で行う
現代のプロセッサにおけるボトルネックはメモリ転送であり、計算ではないといわれています。このため、高速な処理を行うためには、計算だけでなくメモリ転送も高速化する必要があります。
メモリ転送を高速化する方法の1つは、一度に転送するデータ量を増やすという方法です。メモリアクセスはこれ以上速くすることはできないといわれますが、それはアクセスに必要な時間(レイテンシ)を短くすることができないという意味であり、遅いメモリであっても複数のメモリを並べることで一度に転送できるデータ量を増やすことは可能です。
例えば、1秒間に10MBのデータ転送を行う処理があった場合、これを0.5秒で10MBのデータ転送を行うように高速化するのは難しいのですが、1秒で20MBのデータ転送を行うように高速化することは可能なのです。
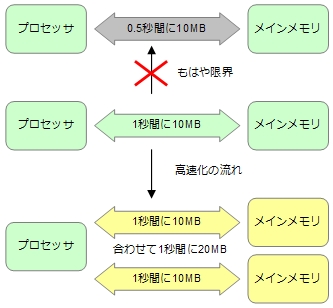
この方法を適用する場合は、1回のメモリ転送で多くのデータを転送する必要があり、既存のプロセッサのように、必要なデータはメインメモリから1個ずつ取ってくるという方法では、そのままでは適用できません。
実際のプロセッサコアにはハードウェアプリフェッチと呼ばれるプログラムの動きからデータアクセスを予測する仕組みが実装されていて、この仕組みを使ってメモリアクセス回数を減らすものがあるのですが、このハードウェアプリフェッチはプロセッサコアの複雑さの原因になるため、小さなコアを目指すSPEに実装するわけにはいきません。
そこで、SPEにはローカルストレージと呼ばれる各自のプライベートな記憶域に、必要なデータを一度にすべてDMA転送(Direct Memory Access Transfer)でコピーしたあと、少しずつ演算処理を行うという方法が採用されています。
DMA転送というのはメモリ転送を行うだけの専用ハードウェアを使ってデータのコピーを行うことです。SPEには、MFC(Memory Flow Controler)と呼ばれるメモリ転送専用ハードウェアが実装されており、これを使って、ローカルストレージとメインメモリ間のデータの転送を行います。
このMFCを使ったSPEでのプログラムの疑似コードをリスト1に示します。また、比較のために、同じ処理を一般的なプロセッサで行った場合の疑似コードをリスト2に示します。
mfc_get(data_local, data, 1024); // 1024個分のデータをメインメモリからローカルストレージに読み込み
for (i=0; i<1024; i++) {
func(data_local[i]); // 1個ずつ計算処理
}
mfc_put(data_local, data, 1024); // 1024個分のデータをローカルストレージからメインメモリに書き込み for (i=0; i<1024; i++) {
v = data[i]; // 1個のデータをメインメモリから読み込み
func(v); // 1個ずつ計算処理
data[i] = v; // 1個のデータをメインメモリに書き込み
}一般的なプロセッサでは計算処理単位ごとにメモリの読み書きを行いますが、SPEではDMAを使って一定以上の数のデータを一度にまとめて読み書きします。
2/3 |
| Index | |
| プロセッサ別に見る並列アーキテクチャ | |
| Page1 実際の並列プロセッサの特徴を知る Intel Core i7 |
|
| Page2 Cell Broadband Engine |
|
| Page3 NVIDIA Tesla 10 Intel Larrabee 適材適所という考え方 |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





