
データ並列で実装してみる
このプログラムをデータ並列で実装した場合、どのようになるでしょうか。
データでの分割としては、チェック対象となる一連の奇数を等分する、という考え方ができます。
各データには依存関係がないのでデータ並列によって並列化したのが次のコードです。
//#include <iostream>
//#include <iterator>
#include <vector>
#include <cmath>
#include <boost/thread.hpp>
#include <boost/progress.hpp>
class PrimeCalc
{
private:
int m_start_index;
int m_end_index;
std::vector<int> & m_prime_vector;
public:
PrimeCalc(int start_index, int end_index, std::vector<int> & prime_vector)
: m_start_index(start_index), m_end_index(end_index),
m_prime_vector(prime_vector) {}
~PrimeCalc() {}
void operator () (void)
{
for (int i = m_start_index; i <= m_end_index; i += 2)
{
bool prime_flag = true;
int square_root = static_cast <int> (sqrt(i));
for (int j = 3; j <= square_root; j += 2)
{
if (0 == (i % j))
{
prime_flag = false;
break;
}
}
if (true == prime_flag)
{
m_prime_vector.push_back(i);
}
}
}
};
int main(void)
{
std::vector < int > v0; /* prime vector */
std::vector < int > v1; /* prime vector */
PrimeCalc pc0(3, 499999, v0);
PrimeCalc pc1(500001, 999999, v1);
{
boost::progress_timer pt;
boost::thread th0(pc0);
boost::thread th1(pc1);
th0.join();
th1.join();
}
//std::copy(v0.begin(), v0.end(), std::ostream_iterator<int>(std::cout, " "));
//std::copy(v1.begin(), v1.end(), std::ostream_iterator<int>(std::cout, " "));
//std::cout << std::endl;
return 0;
}prime_data_parallel.cxxという名前でファイルに保存し、コンパイルします。
$ g++ prime_data_parallel.cxx -o prime_data_parallel.elf -lboost_thread
実行してみましょう。
$ ./prime_data_parallel.elf 0.96 s
プログラムの解説です。
main関数では、まず素数を判定した結果を保存するために、42行目で標準ライブラリのvectorクラスの変数を用意します。次に、45行目で素数の判定を行うPrimeCalcクラスの変数を、データ範囲と結果保存用vectorを引数にして定義します。そして、51行目でboost::threadにより新たなスレッドを生成して並列実行します。
18行目のPrimeCalcクラスのoperator ()関数では、指定された範囲内にある各奇数が素数であるかを判定し、素数だった場合には結果を保存するためのvectorに詰めていきます。
入力データは事前に用意されて変化せず、出力データはほかのスレッドとは完全に別の領域に出力するため、共有資源がないので特に排他制御を行っていません。そのため、この例ではキューから数字を取り出すときに排他制御を行うタスク並列に比べてオーバーヘッドがなく動作時間も短くなっています。
処理の流れを比べてみよう
タスク並列とデータ並列に関する処理概要の流れ図を参考までに示します。
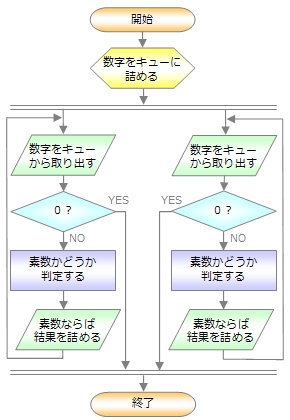
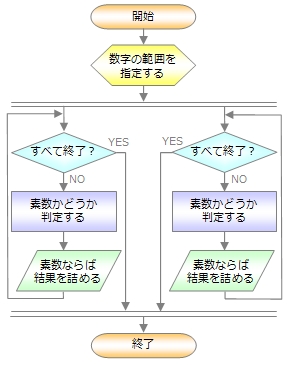
今回は、マルチスレッドプログラミングの説明として分かりやすいように、このようなアルゴリズムとしましたが、素数を見つけるという目的に注目すれば「エラトステネスのふるい」のようなより効率の良いアルゴリズムもあります。
実際には、並列化の前に、より良いアルゴリズムがないかという部分から検討を行う必要があります。
次回は、ベクトル演算を使った高速化について解説します。
マルチコアCPUのための並列プログラミング
Boost C++ Libraries Chapter 17. Thread
Patterns for Parallel Programming
3/3 |
| Index | |
| タスク並列とデータ並列の違い | |
| Page1 マルチスレッドプログラムの実際 分割と依存関係 並列化のためのアルゴリズム |
|
| Page2 スレッドによる並列化 |
|
| Page3 データ並列で実装してみる 処理の流れを比べてみよう |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





