
第1回 パフォーマンス問題解決の定石
ヒューレット・パッカード・ソリューションデリバリ
小野幸治
2003/7/30
|
今回の内容
|
いま、J2EEシステムの運用をいかに成功させるかが大きな課題となっている。J2EEは新しいテクノロジであり、運用ノウハウを確立している企業が少ないからだ。例えば、システムが問題なく稼働していると判断されていたにもかかわらず、ユーザーからのクレームで初めてWebシステムのパフォーマンスに問題が発生していることが分かるケースさえある。
現在、J2EEシステムの運用における課題は以下のように整理することができるだろう。
|
|
さらに、運用サイドから問題が報告され、解決を求められた開発者サイドの課題としては以下のように整理できるだろう。
|
|
第1回では、上記の問題点をどのようなルールで解決するかを解説する。次回以降でスループットとレスポンスタイムの管理、そしてボトルネックの管理ポイントまでを解説する予定である。
| パフォーマンス管理のルールとは |
「監視できないものは、管理できない」 「計測できないものは、パフォーマンスチューニングできない」この2点は、パフォーマンス管理の格言として肝に銘じるべきだ。
「パフォーマンスに問題がある」「サービスがダウンする」といった問題に取り組む際に、最初に行うべきことは「計測」だ。パフォーマンスの改善を行うには、まずその状態をきちんと把握する必要がある。状態が分からずに改善はあり得ない。それでは何を計測するべきだろうか?
計測はエンドユーザーの視点で行う。「パフォーマンスに問題がある」「サービスがダウンする」というのはエンドユーザーの体験であり、エンドユーザーからのクレームが報告される前に知っておきたい状態である。
J2EEは非常に複雑なコンポーネントで構成される。エンドユーザーにサービスを提供するこれらのコンポーネントについて計測を行う必要がある。
|
「ユーザーからのクレームが報告されて初めて問題を知る」という状態を改善するには、いままでのリアクティブな管理体制から脱却する必要がある。プロアクティブな管理の実現には「サービス」という観点からインフラストラクチャを管理するマインドが求められる。ここでいうサービスとは、ユーザーが実行するWebアプリケーションだ。ユーザーが実行するWebアプリケーションが常に満足のいくパフォーマンスでユーザーに提供されるためには、そのサービスを支えるすべてのコンポーネントの状態が関係してくる。
具体的には、ユーザーが利用するWebアプリケーションはインターネット、Webサーバ、J2EEアプリケーションサーバ、データベースサーバや、さまざまなネットワークデバイス(スイッチ・ルータ、ロードバランサなど)で構成されている。そのため、関係するすべてのコンポーネントの統合的な信頼性とパフォーマンスを管理するための「監視と測定」が必要となる。
第1に、プロアクティブな管理を実現するために、ユーザーの体験をシミュレートする「アクティブ監視」を実行する必要がある。アクティブ監視とは、ユーザーが実行するトランザクションをプローブ・ソフトウェアで擬似的に実行し、ユーザーと同様の体験を疑似的ではあるが定期的かつ、継続的に「測定し監視」する管理手法だ。
第2に、一度ユーザー体験に問題ありと認識された場合、「問題の解析と解決」が求められる。すなわち、Webシステム全体で、どの部分にボトルネックが存在するかの特定と問題の解析、診断とその報告である。
第3に、ボトルネックの特定と、根本原因が分かったところで、それがインフラストラクチャのリソースの調整で事足りるのか? Webアプリケーションのプログラムに問題があるのか? あるいは、物理的なリソースの新しい投資が必要なのか? を判断することにより適切な「最適化」を行う必要がある。
根本原因が明確にならない状態で「取りあえず、パフォーマンスを改善するためにCPUを足す」という対症療法的な対応は、結果として「パフォーマンスの改善が見られない」という最悪の事態を招くことも少なくなく、最も避けるべき行為だろう。最適化にはインフラ・コンポーネントのリソース使用率のトレンドやベースラインなどの情報が重要であり、定期的、継続的に収集されたデータをなくして、正確な予測と計画は不可能となる。
ここまで述べたパフォーマンス管理の手順を以下に整理しよう。
|
||||||||||||
上記のポイントを図にまとめると以下のようになる(図1)。
 |
| 図1 パフォーマンス管理のライフサイクル。「監視と測定」→「問題の解析と解決」→「最適化」を繰り返すのがパフォーマンス管理の基本だ |
| ボトルネックをどう発見するか |
エンドユーザーの体験という角度からエンドユーザーに提供されるサービス、そしてそれを支えるインフラストラクチャを見ると、図2のように「ユーザー視点」「トランザクション視点」「インフラストラクチャ視点」の3つの階層に区分して考えることができる。
ユーザーの視点での体験値を測定し問題が発生したときに、Webシステム全体のどこにボトルネックがあるのかをトランザクションの視点から分析し、分解する。そして、問題発生の分野を特定し、最終的には特定された分野のコンポーネントの詳細情報から根本原因を明らかにしていく。ここにユーザー・パフォーマンス劣化の発見から根本原因特定に至るまでのドリルダウンの図式が見られる。
 |
|
図2 パフォーマンス管理の3つの層 |
1-(a)「エンド・ツー・エンドのユーザー体験をシミュレートし測定する」はいわゆるシミュレーションという分野でくくられているが、ツールとしてはMercury InteractiveのTopazや、hp openviewのinternet servicesなどの製品がある。これらの製品はプローブというソフトウェアにより、ユーザーがブラウザから行う一連の動作を疑似的に実行するもので、スクリプト化された「Webサイトへアクセス」→「商品を検索」→「ショッピングカートに入れる」→「顧客情報を入力」→「決済」というユーザーの代表的なアクセスパターンをユーザーに成り代わって定期的(例えば5分間隔などで)、継続的に実行し、そのパフォーマンスの状態をプロアクティブに監視するというものである。このようなシミュレーション・ツールを使えば複数のURLをまたぐユーザー・アクセスのパフォーマンスを監視、そして測定し、ほぼリアルタイムでユーザー・パフォーマンスの近似値を得ることができる。もちろん、しきい値の設定によりユーザー・パフォーマンスに問題が発生する前にそれを予測し、対応することも可能である。
シミュレーション・ツールにより、比較的簡単に「ユーザーからのクレームが報告されて初めて問題を知る」という問題は減少させることができる。
しかし、ユーザー・パフォーマンスの問題を検知したら、トランザクション視点からトランザクションのどの区間に問題があるのかを、トランザクションを分解し、区間を特定しなければならない。
現在では、Webシステム・トランザクション(ユーザー・トランザクション)を可視化してディコンポジション(分解)するというツールの分野が確立されつつある。代表的なツールとしては、Precise Indepth J2EE、Wily4 Introscope、hp openview transaction analyzerなどが挙げられるが、われわれはhp openview internet servicesとの連携の利便性からtransaction analyzerを使用している。ディコンポジションという分野のツールはJ2EEアプリケーションをメソッドコール単位に分解し、パフォーマンス劣化の具体的なメソッドコールをピンポイントで指摘する機能を持つ。hp openview transaction analyzerは、「ユーザー」→「Webサーバ」→「J2EE アプリケーションサーバ」→「データベースサーバ」のどの区間でパフォーマンス劣化が見られるのかといった解析を可能にしている。これによって、根本原因の所在の見当をつけ(問題の切り分け)、そこから構成要素のデータを精査することでボトルネックの特定と、問題の診断を行う。
もちろん、hp openview transaction analyzerの機能としては、J2EEのServlet、EJB、JSP、JDBCなどのユーザー・メソッドコールレベルでのパフォーマンス状態を測定し、メソッドコール単位でのパフォーマンス劣化を特定することができる。
運用管理者は、サマリ画面で問題の切り分けを行うことができ、プロファイラ機能であるCall graphの詳細情報を開発者に提供することで、アプリケーション処理の詳細な状態を把握することができる。
これにより、まず問題の区間を特定し、さらにそれがJ2EEアプリケーションサーバの問題であればアプリケーション処理でボトルネックとなっているメソッドコールを特定し、正常値と異常値のデータを確認することができる。
前述した構成要素のパフォーマンス状態を定期的、継続的に計測する必要があるが、これらはすべてツールで可能である。J2EEアプリケーションサーバはJ2EE 1.3からJMX(Java Management eXtention)を正式にサポートしているため、JVM、キャッシュ、トランザクション、セッション、スループット、JDBC接続プールの使用率などの情報を取得できる。hp openview J2EE Server Smart Plug-inなどが代表的な製品で、J2EEアプリケーションサーバのJMXに対応し、必要な監視項目を網羅している。
| 開発と運用間での協力が重要 |
図3は、われわれが性能の改善、向上プロセスの提案で使用する資料の一部である。
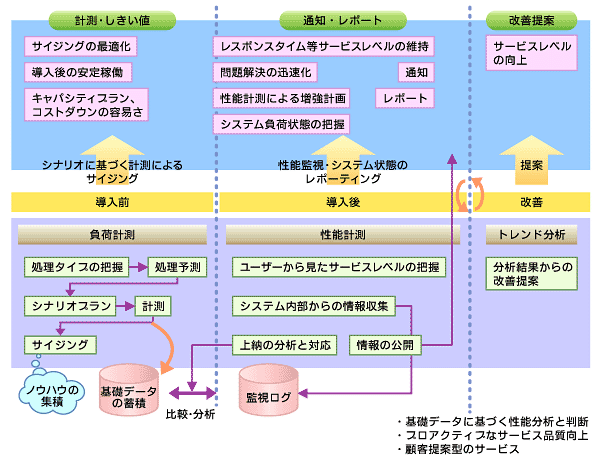 |
| 図3 性能の改善・向上のための手順 (クリックすると拡大します) |
システムの負荷限界値を把握し、負荷計測の「基礎パフォーマンスデータ」と、本番環境で定期的、継続的に取得した「実環境パフォーマンスデータ」の問題発生時の異常値をもって比較・分析を行う。
ここで重要なポイントは、開発側が考えるシステムのあるべき姿と運用側の理解そして、互いに共有されているかということである。すなわち、システムのパフォーマンスとして何を求めているのか、という点なのだが。レスポンスタイムとスループットは、どちらを求めるかによって環境の設定が異なる場合がある。最大同時ユーザー数がコントロールできる環境か否かにより、事前に考慮しなければならないことも変わるだろう。
一般的には、パフォーマンスが良いということは以下の点でまとめられる。
- 飽和点における最大同時ユーザー数が多い
- レスポンスタイムが短い
- スループットが高い
図4では、飽和点を超えてもスループットの限界値を保ちながらユーザーの増加に耐えていることが分かる。もちろん、レスポンスタイムは悪化するが、適切にチューニングされたシステムでは飽和点に達してもスループットは、ほぼ一定の値を示す。
 |
| 図4 適切にチューニングされたシステムでは飽和点を超えてもスループットはほぼ一定の値を示す |
ところが、チューニングされていない状況だと下図のように最大同時ユーザー数を超えると、スループットが急激に下がり始め、レスポンスタイムは急速に悪化する。
 |
| 図5 チューニングされていないシステムでは最大同時ユーザー数を超えるとレスポンスタイムは急激に下がる。最悪のケースではサービスダウンもたらす |
負荷限界値を把握し、過負荷状態でもシステムダウンしないチューニングが施されていないと予測以上の最大同時ユーザーのアクセスが発生した際に、システムダウンという状況に陥る可能性が高まることになる。残念ながら、チューニングされていればシステムダウンが100%防げるかということは断言できない。それはボトルネックの要因がさまざまであるからだ。しかし、負荷テストを行い負荷限界値を把握し、過負荷状態でも耐え得るシステムであれば、これらの情報を利用してプロアクティブな問題対応や、的確なキャパシティプランニングを行うことができる。
次回予定している、「スループットとレスポンスを管理する」では、具体的な測定方法などに触れながら運用側にとってのメリットなどを中心に解説する。
| INDEX | |
| J2EEパフォーマンス管理の勘所 | |
| 第1回 J2EEパフォーマンス管理の定石 | |
| 第2回 スループットとレスポンスタイムを管理する | |
| 第3回 ボトルネック管理の最適解 | |
| JavaSolution連載記事一覧 |
- 実運用の障害対応時間比較に見る、ログ管理基盤の効果 (2017/5/9)
ログ基盤の構築方法や利用方法、実際の案件で使ったときの事例などを紹介する連載。今回は、実案件を事例とし、ログ管理基盤の有用性を、障害対応時間比較も交えて紹介 - Chatwork、LINE、Netflixが進めるリアクティブシステムとは何か (2017/4/27)
「リアクティブ」に関連する幾つかの用語について解説し、リアクティブシステムを実現するためのライブラリを紹介します - Fluentd+Elasticsearch+Kibanaで作るログ基盤の概要と構築方法 (2017/4/6)
ログ基盤を実現するFluentd+Elasticsearch+Kibanaについて、構築方法や利用方法、実際の案件で使ったときの事例などを紹介する連載。初回は、ログ基盤の構築、利用方法について - プログラミングとビルド、Androidアプリ開発、Javaの基礎知識 (2017/4/3)
初心者が、Java言語を使ったAndroidのスマホアプリ開発を通じてプログラミングとは何かを学ぶ連載。初回は、プログラミングとビルド、Androidアプリ開発、Javaに関する基礎知識を解説する。
|
|





