もう1つの、DBのかたち、分散Key-Valueストアとは:分散Key-Valueストアの本命「Bigtable」(1)(2/3 ページ)
分散KVSが苦手なトランザクションの「ACID特性」
RDBのように、テーブルとテーブルを結合(SQLでいうJOIN文)して複雑な条件検索や集計処理を一発でこなすような芸当はできません。また、トランザクションによる「ACID特性」の確保も分散KVSが苦手な分野です。

RDBが不得意な分散/拡張
そのため、これらの不足をアプリケーション側で補うためのさまざまな工夫やフォローが必要となります。その一方で、分散KVSはデータストア全体をいくらでも多くのサーバに分散(スケールアウト)できるのが最大の特徴です。
一方でこれは、RDBが最も不得意とするところです。RDBでは、その長所であるテーブル結合やACIDの確保がボトルネックとなり、複数のサーバにスケールアウトさせることが「原理的」に容易ではありません。そのため、負荷分散や高可用性を低コストで実現することが困難です。
RDBで負荷分散させようとすると……
例えばMySQLを使う場合、1テーブルのレコード件数が数百万〜数千万件を超えるような規模になると、1台のDBサーバだけでは実用的なパフォーマンスが達成しにくくなります。そこで一般には、以下のような対策によってRDBのスケーラビリティを引き上げる努力が必要となります。
- RDBサーバのスケールアップ(大型サーバへの載せ替え)
- DBのレプリケーションやシャード(パーティション)分割によるクラスタ構築
- 分散キャッシュ(Oracle RACやmemcachedなど)によるクラスタ構築
経験者ならばお分かりいただけるとおり、このどれもが結果的に「高コスト」となるソリューションです。
大型サーバやOracle RACが高価なのは当然ですが、オープンソース実装を駆使してシャード分割を実装する場合も高い技術スキルを持つ人材が要求され、システム障害のリスクを抑えるためには周到な設計やテストが必要です。Oracle RACの詳細は、下記記事を参照してください。

レプリケーションやmemcachedも、検索処理のスケールアウトには効果がありますが、更新処理やテーブル結合のスケールアウトにはあまり効果がありません。memcachedの詳細は、下記記事を参照してください。

これらの理由により、RDBがある一定の規模に成長してクラスタ構築が必要になると、システム開発コストはけた違いに上昇していきます。
分散KVSは「グーグルのビジネスモデルそのもの」
そもそも、RDBのデータモデルは原理的にスケールしにくく、これらの対策は対症療法的な側面があります。一方で、分散KVSのデータモデルは原理的にスケールしやすく、実用上は無制限に近いスケーラビリティ(負荷分散と高可用性)を低コストで達成できます。
グーグルが検索サービスのデータストアとしてRDBを選ばなかった理由は、ここにあります。むしろ、機能豊富なRDBをあえて使わず、シンプルな分散KVSによって無制限なスケーラビリティを低コストで実現することこそが、「グーグルのビジネスモデルそのもの」といっても過言ではありません。
RDBが超えられない「CAP定理」のカベ
2000年にUC Berkley大学のEric Brewer教授が発表した「CAP定理」では、分散システムで以下の3つを同時に保証することは不可能であることが示されています。
- データの整合性(Consistency)
- データの可用性(Availability)
- データの分散化(Partition-tolerance)
RDBとは、そもそもスケールしにくいものだ
一般的なRDBでは、トランザクションに含まれるすべてのデータについて、ACID特性(CAPのC)を保証します。これはつまり、可用性(同じくA)と分散化(同じくP)の間にトレードオフが発生することを意味します。負荷分散と冗長化のためにRDBをクラスタリングすると、整合性確保のためにそれぞれのデータが高頻度でロックされ、スケーラビリティは頭打ちになってしまいます。これが、「RDBは原理的にスケールしにくい」理由の1つです。
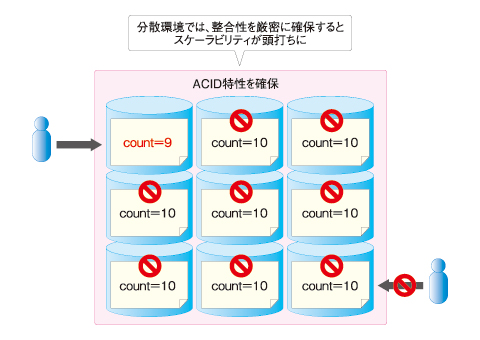 図2 CAP定理が示すRDBの限界
図2 CAP定理が示すRDBの限界アプリケーションが分散化対応するための必須条件
一方、例えばBigtableでは、可用性と分散化を損なわないために、ACID特性の保証が一定範囲に限定されています。よってプログラマは、個々のアプリケーションについてACID特性の要件を見定め、Bigtableの能力でそれに対応できるか判断したり、アプリケーションの設計を工夫したりする必要が生じます。また、決済業務など厳格なACID特性が要求される用途では、Bigtableを適用しにくいケースも少なくないはずです。
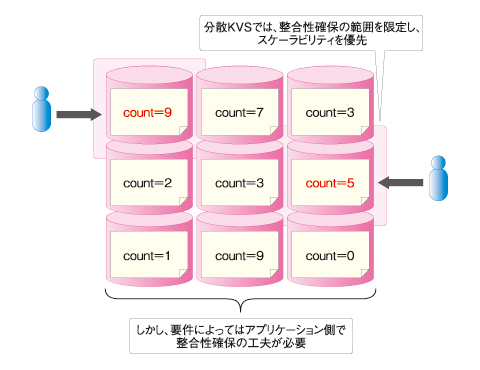 図3 分散KVSのスケーラビリティと「使いにくさ」
図3 分散KVSのスケーラビリティと「使いにくさ」こうしたさまざまな制約や実装の面倒さはRDBにはなかったものですが、それがアプリケーションの分散化に際して避けて通れないものであることは、CAP定理が証明するところです。
つまり、分散KVSのさまざまな「使いにくさ」(「ACID特性が限定される」「テーブル結合ができない」「検索・集計機能が貧弱である」など)をアプリケーション側でフォローすることは、裏を返せば「アプリケーションが分散化対応するための必須条件」なのです。
次ページで、その「使いにくさ」に対応することによって得られる2つの利点を解説し、最後に分散KVSとクラウドについてまとめます。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。