‘愛’で学ぶ文字コードと文字化けの常識:プログラマーの常識をJavaで身につける(6)(3/4 ページ)
文字化けには問題がこんなにたくさんある!
それでは次に、文字化けの常識を学んでいきましょう。皆さんはここまで文字コードについて学んできたので、文字化けのことが理解しやすくなっているはずです。逆に、文字コードのことを理解できていないと、文字化けについての理解は非常に困難になります。文字化けについて悩んだときは、いつも文字コードの基本に立ち返ることを忘れないでください。
さまざまな層の原因が複合的に組み合わさって起こる文字化け
私たちがコンピュータやそのほかの関連技術に従事していると、さまざまな文字化けに遭遇することがあります。文字化けはさまざまな要因によって引き起こされる可能性があります。プログラミングそのものに起因することもありますが、OS、ミドルウェアやそのほかのコンピュータ環境などの、さまざまな層によって複合的に引き起こされる場合も多いように感じます。
ここでは、よく発生する一般的な文字化けについて見ていきます。場合によっては、複数の原因が複合的に絡み合って文字化けを引き起こしている場合もあります。しかし、それらの原因を1つずつ見ていけば、おのずと原因を究明でき、解決できるものなのです。
国によって異なる文字が割り当てられている!?
【Unicodeのアキレス腱 その2】
歴史的な理由から文字化けの原因が改善できずに残っている場所があります。昔から使われているISO/IEC 646各国語版という文字コードがあります。このISO/IEC 646各国語版では、一部の文字を国によって置換できる(入れ替えが可能)と定められました。
例えば、ISO/IEC 646の「\」(バックスラッシュ)と「~」(チルダ)の文字について、日本語版では「\」(円記号)と「 ̄」(オーバーライン)とに置き換えています。なおISO/IEC 646の日本語版は、日本ではASCIIコードという通称で呼ばれていたこともありますが、厳密には異なるものです(『文字符号の歴史 -- アジア編』 101ページ)。
特に、「\」が「\」に置き換えられていることに起因する問題について、「YEN SIGN問題」と呼ぶことがあります。この問題のため、「\」が 環境によっては「\」で表示されたり「\」に置き換えられて表示されたりします。
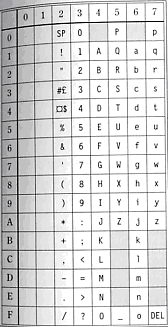 図4 ISO/IEC 646各国語版の文字コード表(『文字コード超研究』261〜262ページから引用)
図4 ISO/IEC 646各国語版の文字コード表(『文字コード超研究』261〜262ページから引用)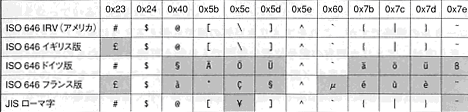 図5 各国の変更点(『文字コード超研究』261〜262ページから引用)
図5 各国の変更点(『文字コード超研究』261〜262ページから引用)ISO/IEC 646の問題をプログラムから確かめる
このISO/IEC 646はシフトJISなどの文字エンコーディングにも継承されています。この問題を確認するために、ISO/IEC 646の範囲をファイルに出力する簡単なサンプル、ListIso646.javaを作成しました。この例では、シフトJISとしてListIso646.txtという名前のファイルを出力します。
このプログラムの実行結果のListIso646.txtをWindows付属のメモ帳で開いてみると、この問題を体験できます。メモ帳が利用するフォントを切り替えると、なんと、文字が別のものに変わります。
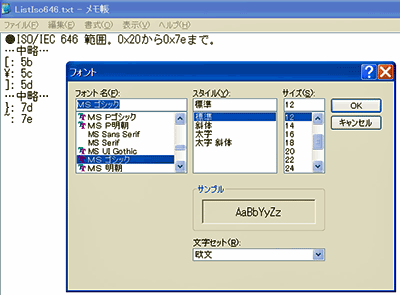 図6 ISO 646範囲をMSゴシック フォントで開くと
図6 ISO 646範囲をMSゴシック フォントで開くと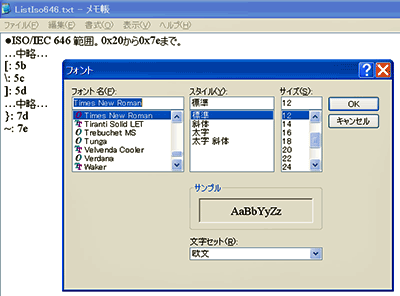 図7 ISO 646範囲をTimes New Roman フォントで開くと
図7 ISO 646範囲をTimes New Roman フォントで開くと「\」は、Java言語ではエスケープ記号として用いられ、Windowsではディレクトリの区切り文字に割り当てられています。重要な意味合いで利用される文字が文字化けするのだから、かなり厄介です。残念なことに、この問題は多くのコンピュータ環境で現在も克服できていません。
OSや携帯電話ごとに存在する機種依存文字 OSや携帯電話ごとに存在する機種依存文字
文字エンコーディングは、どのような文字(符号化文字集合)をどのような数値(文字符号化方式)で表すのか、というのが基本です。ところが、歴史的な背景から、厳密には異なる文字エンコーディングであるものを、あたかも同じ文字エンコーディングとして扱っている場合があり、問題を引き起こす場合があります。
代表的な例であるシフトJIS(Shift_JIS)に関連するものを見て行きましょう。シフトJISは、現時点でIANAでは、下記のように記載があります。
Name: シフトJIS (preferred MIME name)
MIBenum: 17
Source: This charset is an extension of csHalfWidthKatakana by
adding graphic characters in JIS X 0208. The CCS's are
JIS X0201:1997 and JIS X0208:1997. The
complete definition is shown in Appendix 1 of JIS
X0208:1997.
This charset can be used for the top-level media type "text".
Alias: MS_Kanji
Alias: csShiftJIS
『文字コード超研究』403ページにも、下記のように記載があります。
| 種別 | 正式名称 | 略称 |
|---|---|---|
| 文字集合名 | JIS X 0201 ローマ字(2/0はSP、15/15はNULL) | 半角英数字 |
| 文字集合名 | JIS X 0201 カタカナ(2/0はSP、15/15はNULL) | 半角カナ |
| 文字集合名 | JIS X 0208 漢字 | JIS基本漢字 |
| エンコーディングスキーム | JIS X 0201の8ビット構造 | JIS 8 |
| エンコーディングスキーム | JIS X 0208をGLに呼び出したコード | JIS 漢字コード |
| 表2 『文字コード超研究』 403ページより引用 | ||
シフトJISで利用可能な漢字および記号は、JIS X 0208で定められた文字だけのはずなのです。ところが、例えば日本でよく使われているMicrosoft Windowsシリーズでは、シフトJISを拡張したものを利用しています。これは、IANAではWindows-31Jとして登録されています。『CJKV日中韓越情報処理』 600ページに、下記の記載があります。
Microsoft日本語 (Windows-31J)
この文字集合は、JIS X 0208-1990に NEC漢字の13区、IBM専用漢字と非漢字の集合を足したものである。
Windows-31Jで追加されている部分は、以下の3つに分類されます。
| 通称 | コード範囲 | 区 | 説明 | |
|---|---|---|---|---|
| 1 | NEC特殊文字 | 0x8740-879c | 13区 | ?(○1)などが入っていることで有名 |
| 2 | NEC選定IBM拡張文字 | 0xed40-eefc | 89-92区 | ※ほとんど重複符号化(重複符号化については後述) |
| 3 | IBM拡張文字 | 0xfa40-fc4b | 115-119区 | 小文字のローマ数字や漢字など。 |
| 表3 Windows-31Jで追加されている部分 | ||||
このWindows-31Jで追加された部分の文字をシフトJISとして非Windows-31Jエンコーディング環境に渡すと、受け取った側で表示できない、あるいは別の文字が表示されるという状況が発生します。
これを解決するための「正しい」対応方法は、基本的に下記のいずれかです。
- シフトJISエンコーディングとしてデータを渡すからには、シフトJISの符号化文字集合以外の文字は渡さない
- Windows-31Jエンコーディングとしてデータを渡したいのだから、シフトJISと偽らずに、正しくWindows-31Jエンコーディングであることを相手に伝える
- 送付したい文字を含む符号化文字集合を持った文字エンコーディング(多くの場合、UTF-8)を選択する
しかし、これが歴史的な経緯などにより、「正しい」選択肢以外の対応方法が多く採用されているのが現状です。
これと類似した事象は、携帯電話やそのほかの日本語OSなどにも存在します。携帯電話メールで相手から送られた絵文字が読めなかったり、あるいは異なる絵に変わっていたりした経験をお持ちではないですか? それら現象の一部は符号化文字集合へ文字を独自追加したことによるものなのです。また、これら独自追加された文字のことを、機種依存文字などと呼ぶこともあります。
重複符号化【Unicodeのアキレス腱 その3】
:DB入出力でよくある問題
Unicodeには、同じ文字であるのに複数の文字コードが与えられている文字が存在します。これは重複符号化と呼ばれます。これも歴史的な事情などによるのですが、それが文字化けを引き起こす場合があります。
Javaの世界で、この重複符号化によるトラブルをよく見掛けるものの1つとして、OracleなどのDB入出力が挙げられます。Oracleにデータを格納して再び取り出そうとすると、「¬」(ノット記号)が「?」へと化けてしまう現象などが、これに該当します。
Oralce Technology Network(OTN)のサイトにある、NLS環境におけるキャラクタの整合性の問題のページなどに、この現象に関する情報の記載があります。このリンクから、影響のある文字に関する記載を引用します。
| Unicode | Java | ORACL | MSFT | Character Name |
|---|---|---|---|---|
| 00A2 | 8191 | 8148 | - | セント記号(¢) |
| 00A3 | 8192 | 8148 | - | ポンド記号(£) |
| 00AC | 81CA | 8148 | - | ノット記号(¬) |
| 2016 | 8161 | 8148 | - | 二重縦線(‖) |
| 2212 | 817C | 8148 | - | マイナス記号(−) |
| 301C | 8160 | 8160 | ? | 波線(〜) |
| 309B | 814A | 814A | ? | 濁点(゛) |
| 309C | 814B | 814B | ? | 半濁点(゜) |
| FF06 | 8195 | 8195 | X | アンド記号(&) |
| FF9E | DE | DE | ? | 半角の濁点 |
| FF9F | DF | DF | ? | 半角の半濁点 |
| 表4 | ||||
これらの文字はUnicode上で重複符号化されているうえに、JavaとOracleとで対応する文字コードが異なるために問題が顕在化するのです。Unicodeにも意外な弱点があるものですね。
注意!
重複符号化に類似した問題として合成文字の正規化の話題がありますが、現時点では、あまり問題として顕在化しない傾向にあると考え、この記事では説明を省きました。
対象となる環境が指定された文字エンコーディングに対応していない場合
指定された文字エンコーディングに対象となる環境が対応していなければ、それを適切に処理できません。アプリケーションの実装によっては、対応していない文字エンコーディングの場合には、その文字エンコーディングをあきらめて別のエンコーディングで無理やり動作するものがあります。その場合に文字化けが発生する場合があります。なお、前述のように、Java APIではサポートしていない文字エンコーディングを与えると、例外が発生します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。