GoogleのMapReduceアルゴリズムをJavaで理解する:いま再注目の分散処理技術(前編)(2/2 ページ)
■分散処理のMapタスクを実行する「MapTask」クラス
前述のとおり、MapReduceアルゴリズムでは、MapタスクとReduceタスクという2つのタスクに処理を分けて実行します。ここでは、Mapタスクに対応するMapTaskクラスを用意します。このプログラムは単純で、次のように、与えられた文字列を先頭から読み込んで、keyが文字、valueが1であるEntryオブジェクトを生成して、listへ追加するものです。
public class MapTask { |
 図4 MapTaskが生成する「MapEntry」クラスのLinkedListの例
図4 MapTaskが生成する「MapEntry」クラスのLinkedListの例■まとめ処理のReduceタスクを実行する「ReduceTask」クラス
次に、Reduceタスクに対応するReduceTaskクラスを用意します。こちらのプログラムも単純です。与えられたReduceInputは、同じkeyを持つMapEntryの要素のリストをlistとして持っています。この個数を単純にカウントして、その結果をMapReduceCharCounterクラスのstaticなメソッドであるemit()へ渡して結果を保存します。
public class ReduceTask { |
MapTaskクラスも、ReduceTaskクラスも非常に単純なプログラムであるという点に注目しておいてください。ユーザーはこの2つのクラスの処理を変更することにより、さまざまな処理を実現できます。
■Reduceタスクで使われる「ReduceInput」クラス
次に、ReduceTaskクラスのexecute()メソッドのパラメータとして使われているReduceInputクラスについて説明します。すでに説明したように、「同じkeyを持つMapEntryの要素のリストを持つ」ので、プログラムは下記のようになります。
import java.util.LinkedList; |
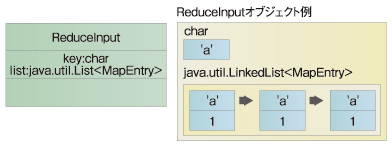 図5 ReduceInputのクラス図とReduceInputオブジェクトの例
図5 ReduceInputのクラス図とReduceInputオブジェクトの例■ReduceInputオブジェクトを生成するファクトリクラス「ReduceInputListFactory」
ReduceInputクラスのオブジェクトは、MapTaskクラスが生成したList<MapEntry>オブジェクトの情報から生成します。この生成処理をする専用のファクトリクラスを次のように用意します。
createInstance()メソッドへ「MapTaskクラスが生成したList<MapEntry>オブジェクト」をlistとして渡すと、List<ReduceInput>オブジェクトが生成されて返ってきます。ただし、listはMapEntryオブジェクトについてソートされている必要があります。
import java.util.LinkedList; |
ここで、MapEntryオブジェクトの値を{keyの値,valueの値}と表現することにします。MapTaskクラスが生成したList<MapEntry>オブジェクトには、{a,1}{a,1}{a,1}{b,1}{b,1}{c,1}といった値がリストの要素として含まれています。
最初にファクトリクラスが返すList<ReduceInput>オブジェクトをインスタンスとして用意します。次に、MapEntry型変数currentとReduceInput型変数riはnullとしておきます。listに含まれるMapEntryオブジェクトの各要素eについて、次の処理を適用します。
- currentと一致しない場合は、新しいReduceInputオブジェクトを生成してriへ参照値を代入し、e.keyをri.keyへ代入。この新しく生成したReduceInputオブジェクトはinstanceへ追加
- riのlistへeを追加
MapEntryオブジェクトについてソートされているので、この処理も簡単に実現できます。
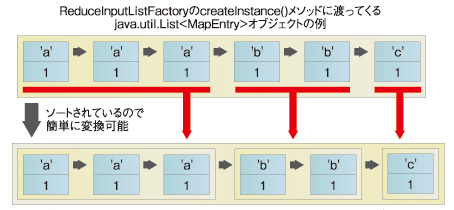 図6 createInstance()メソッドに渡されるオブジェクトから生成されるオブジェクト
図6 createInstance()メソッドに渡されるオブジェクトから生成されるオブジェクト■charの数を数える「MapReduceCharCounter」クラス
最後にMapReduceCharCounterクラスですが、下記のようになります。通常のMapReduceアルゴリズムでは、MapTaskからReduceTaskへデータを渡すときにはファイルを使うのですが、ここでは単純化のために、オブジェクトをそのまま使うことにしました。そのため、ReduceInputListFactoryクラスのcreateInstance()メソッドでmap.listを渡しています。
ただし、ここで渡されているmap.listに含まれる要素はソートされている必要がある点に注意してください。このソートをするために、java.util.Collectionsクラスのsort()メソッドを使っています。sort()メソッドでは、MapEntryクラスに実装されているComparable<MapEntry>インターフェイスを使ってmap.listの要素をソートします。
import java.util.List; |
MapReduceアルゴリズムを使う利点とは?
MapReduceCharCounterAppを実行すると、SimpleCharCounterと同じ実行結果になります。結果は同じですが、その過程に大きな違いがあります。
MapReduceアルゴリズムを使わないSimpleCharCounterの方が単純なプログラムなのですが、順番に処理をする必要があるため、プログラムの分割ができません。計算しなければならないデータが大量にある場合には、1プロセスで計算することになるので、時間がかかります。
一方のMapReduceCharCounterAppでは、MapTaskとReduceTaskに分割されているので、大量のデータを処理するに当たって複数のプロセスで計算をさせることができます。
サンプルでは、ReduceTaskオブジェクトは1つしか生成していませんが、ReduceInputListFactoryを使って得られたList<ReduceInput>オブジェクトの各要素に対してReduceTaskオブジェクトのexecuteメソッドを並行で動作できる点に注目してください。並行して動作させることができますから、ファイルを通せば分散処理も可能であることは、すぐに想像がつくはずです。
■MapReduceアルゴリズムは非常にシンプル
また、MapTaskへの入力データも分割して渡すことができます。その場合は、ReduceTaskではもともとの入力データの部分集合に対する結果が出力されます。この部分集合の結果に対して、結果を集計するプログラムが必要になりますが、それもMapReduceアルゴリズムで実装できますから、そういった処理を組み合わせることにより、巨大なデータに対しても最終的な結果を得ることができます。
MapReduceのアルゴリズムについては、Googleでは並行処理をする機能、耐障害性の実現、なども含まれているので、今回紹介した部分だけで成功しているというわけではありませんが、個人的には、このアルゴリズムは非常にシンプルで、並行処理に向いているという点が高く評価されていると考えています。
■「KISS principle」を心掛けよう
最近の技術は、シンプルなものがユーザーや開発者に受け入れられて普及しているように思えます。
例えば、OMG(Object Management Group、オブジェクト指向技術のための標準化団体)によるCORBA(Common Object Request Broker Architecture)よりも、「XML-RPC Home Page」で紹介されているXML-RPCの方がよく使われて普及しています。XML-RPCよりも複雑な仕様であるSOAPは、なかなか普及していません。EJBにしても、重量なEJB 2は見直されて、軽量なEJB 3となり、ずいぶんシンプルになりました(参考「“誰もが書けるEJB”を実現する「EJB 3.0」」)。
シンプルといっても程度があるので、あまりにシンプルにし過ぎてもいけませんが、複雑になりがちなソフトウェアを開発するに当たっては、できるだけシンプルなものを目指す、というのは必要です。昔から「KISS principle」というのがあり、いまさらいうことでもありませんが、常に心掛けたいものです。
Apache HadoopとJava関連の分散処理技術
さて、Javaの世界でMapReduceといえば、Apache Hadoopがあります。これは、JavaによるMapReduceアルゴリズム実装です。こういったソフトウェアを利用すれば、誰でも大規模分散処理を実行できるようになります。
もちろん、問題領域がMapReduceアルゴリズムを使うと解決しやすいものでなければ有効ではありませんが、ちょっとした工夫をするだけで、これまでは難しいと考えられていた分散処理が簡単に実現できる可能性が出てきました。利用者がMapTaskクラスとReduceTaskクラスに相当するシンプルなプログラムだけを作成すればいいのですから、その点からすると、画期的です。
後編は、そのApache Hadoopや、前述のCORBAやXML-RPC、SOAPを含めたJava関連の分散処理技術についてお話ししたいと思います。お楽しみに。
筆者プロフィール
株式会社ガリレオ
小山博史(こやま ひろし)
情報家電、コンピュータと教育の研究に従事する傍ら、オープンソースソフトウェア、Java技術の普及のための活動を行っている。長野県の地域コミュニティである、SSS(G)やbugs(J)の活動へも参加している。
著書に「基礎Java」(インプレス)、共著に「Javaコレクションフレームワーク」(ソフトバンククリエイティブ)、そのほかに雑誌執筆多数。
関連記事
- スキルアップのための分散オブジェクト入門
分散オブジェクト技術はシステム・インテグレーションを行うエンジニアにとって重要な基礎知識。本連載では分散オブジェクト技術の目的から、個々の分散オブジェクト技術についてわかりやすく解説します - いまなぜCORBAなの?
CORBAは「難しい」「仕事に関係ない」「古い」と思っているJavaエンジニアの皆さん。実はEJBの登場でCORBAの役割が再びクローズアップされてきているのです - HORBと遊ぼう
HORBは、日本で開発された分散オブジェクト環境だ。使いやすさを中心テーマに開発されたHORBを使い、楽しく遊びながらJavaによる分散オブジェクト環境を学んでみよう - 次世代を予感させるグリッドコンピューティング
安藤幸央のランダウン(7) 地球外知性探索のSETI@Homeなどで知られるグリッドコンピューティング。今、商用化や標準化など、さまざまな試みに発展している - コレクションフレームワークを拡張するCollections
[連載]現場に生かすJakarta Project(7) CommonsにはJavaのコレクションフレームワークの拡張版ともいえるクラスが用意されている。このクラスの活用を紹介しよう - Javaでコンパイラの基礎を理解する
コンパイラを意識したコーディングをすると、パフォーマンスが向上し、プログラミング力も向上します。Javaを通してその仕組みを理解しましょう
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。