64bitファイルシステム XFSの実装:Linuxファイルシステム技術解説(7)(1/3 ページ)
XFSは、巨大ストレージでの利用を視野に入れた64bitファイルシステムである。膨大な領域を効率的に利用するため、XFSにはさまざまな仕組みが組み込まれている。(編集局)
XFSの歴史
XFSはSilicon Graphics(以下SGI:編注)が開発したジャーナリングファイルシステムである。XFSの開発が開始された当時、SGIはすでにEFS(Extent File System)というファイルシステムを持っていた。SGIがXFSで目指したものは、次世代の拡張性を考慮した64bitファイルシステムを新規開発することだった。
編注:1994年当時はSilicon Graphics, Inc.。1999年にSGIに社名変更。日本法人もそれに合わせて、日本シリコングラフィックスから日本SGIに社名を変更した。
http://www.sgi.co.jp/newsroom/press_releases/1999/Apr/sgi.html
http://www.sgi.co.jp/newsroom/press_releases/1999/Apr/sgijapan.html
XFSは、1994年後半にリリースされたIRIX 5.3(IRIX 5.3 with XFS)に初めて搭載された。1996年にIRIX 6.2がリリースされると、全SGIシステムに標準でインストールされるようになった。1999年前半にはLinuxへ移植され、GPL(GNU General Public License)の下でオープンソースとして公開された。
最初のLinux用XFSであるXFS 1.0 for Linuxは、カーネル2.4.2用のパッチとして提供された。その後、新しいカーネルが出るたびに対応パッチがリリースされ、2.4.21以降は標準カーネルにマージされることになった。以降のバージョンは、パッチを当てなくてもカーネルをコンパイルするときのオプション設定で利用可能となる(設定については後述)。
XFS for Linuxの最新のパッケージやパッチは、http://oss.sgi.com/projects/xfs/download.htmlで入手できる。
XFSの特徴
XFS開発の背景には、今後Tbytesオーダーのディスクが主流となったときに、32bitファイルシステムでは限界があるという認識がある。32bitファイルシステムでは40億個のブロックしか作れないため、ブロックサイズを8kbytesとすると32Tbytesまでしか扱えない。
開発チームは当初からこの問題を考慮し、64bitファイルシステムやアロケーショングループという手法を採用することで巨大なファイルシステムを扱うことを可能にした。また、サイズの大きなファイルは書き込み/読み込み領域を確保したり、ディスク上の空き領域を検索するのに時間がかかるといった問題がある。XFSでは、遅延アロケーションやB+-Treeによってこれに対処している。
■64bitファイルシステム
64bitファイルシステムであるXFSは、理論上最大900万Tbytesのファイル、最大1800Tbytesのパーティションをハンドリングできる。Linuxで広く使われているext2が最大で2Gbytesのファイルまでしか扱えない点を補っている。
■アロケーショングループ
巨大なファイルシステムを効率よく処理するために、XFSはブロックデバイスを「アロケーショングループ」(注)と呼ぶ領域に分割する。アロケーショングループは、iノードと空き領域をグループ化して管理する。FFS(FastFile System)のシリンダグループに似ているが、アロケーショングループはスケーラビリティと並列入出力の効率に重点を置いている。
注:アロケーショングループは比較的大きく、約0.5〜4Gbytesものサイズがある。
アロケーショングループを用いる理由として、空き領域の管理とiノードの割り当てを並行して行えることが挙げられる。SGIが初期に用いていたEFSでは、書き込みなどを行う処理は1つのプロセスが占有するシングルスレッドとして動作していた。そのため、多数のプロセスが動作するような巨大なファイルシステムでは、この部分がボトルネックとなる。
XFSでは、各アロケーショングループを独立したエンティティとして扱うため、カーネルは複数のアロケーショングループに同時にアクセスできる。言い換えると、1つのファイルに対して、複数のプロセスからアクセス可能になる(図1)。
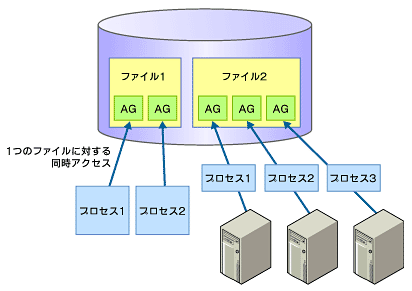 図1 アロケーショングループ(AG)による同時アクセス
図1 アロケーショングループ(AG)による同時アクセスこれは、データベースなどのトランザクション処理が効率的に行えることを意味する。また、複数のホスト上にある複数のプロセスから同時読み込みが行えるため、ストリーミング配信の分散システムなどで利用することもできる。
■遅延アロケーション
「遅延アロケーション」は、新しいデータ用のスペースを確保する際、そのデータを実際にディスクに書き込む直前まで、データの格納に使用するファイルシステム・ブロックの決定を引き延ばす方式である。
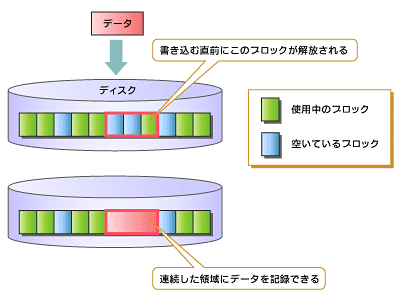 図2 遅延アロケーションの概念
図2 遅延アロケーションの概念空き領域の探索をひたすら行うよりも、図2のようにアロケーションを遅らせた方が効率的にディスクの空き領域を確保できる。例えば、大量の新しいデータを1つのファイルに追加する場合、その時点では連続した領域が確保できなくても、連続した領域が確保されるまで遅延させることにより、連続した1つの領域に割り当てることが可能になる(注)。これにより、不連続な複数の領域に書き込まれてフラグメンテーションが発生するのを低減でき、書き込みパフォーマンスが向上する。
注:このときは、確保した領域に別のプロセスからの書き込みは生じないようになっている。つまり、そこからデータが削除されることはあっても、追加されることはない。
また、生存期間の短いファイルは、UNIXシステムではよく発生する。このようなファイルは、ディスクに書き込まれることなくファイルキャッシュから消去される。遅延アロケーションは、このようなファイルによって生じるメタ・データのアップデート回数とフラグメンテーションを減らすことができる。
遅延アロケーションのほかの利点は、ランダムに書き込みが行われるが、ホールのないようなファイルは隣接して割り当てられることである。書き込みを行ったすべてのファイルがメモリにバッファされるなら、それらをディスクに書き込むときに隣接した領域に割り当てられるのだ。
これらの方法により、ファイルシステムのパフォーマンスを最適化する形でフリースペースを割り当てる。ただし、遅延アロケーションを行うと、データがメモリに滞在する時間が長くなるため、クラッシュなどに弱いという問題がある。この点については、ジャーナリングやRAIDなどとの組み合わせによって対処可能である。
■B+-Tree
XFSは、さまざまなところでB+-Treeを使用している(注)。例えば、空き領域の高速な探索や動的iノードの管理である。また、前述のアロケーショングループでもB+-Treeが使用されている。
注:B+-Treeのアルゴリズムについては第2回を参照。
アロケーショングループは、B+-Treeを2つ使用して空き領域の範囲などの重要データとiノードの追跡を行う。1つには空き領域の範囲がサイズ順に格納され、もう1つには領域がブロックデバイス上の開始物理位置の順に格納される。空き領域を素早く見つけることは、書き込みパフォーマンスを向上させる。
■Direct I/O
一般的に、何度も参照されるファイル、特にサイズの小さいファイルは、ページキャッシュにファイルのコピーを置くことでファイルアクセスを高速化できる。しかし、ストリーミングデータなど、非常に大きなファイルをキャッシュに入れてしまうと、ほかのデータをキャッシュから追い出してしまうことがある。従って、このようなファイルにキャッシュを使うのは好ましくない。
また、大きなファイルを転送する場合、キャッシュを通すとプロセッサのオーバーヘッドが非常に高く、I/Oハードウェアがデータを移動させる方が高速な場合がある。
Direct I/Oは、プログラムがファイルの読み書きをする際、キャッシュを介さずにユーザープログラムのバッファとディスク間を直接データが移動する仕組みである。これにより、キャッシュにデータをコピーするオーバーヘッドを回避し、データ移動の高速化を図っている。また、キャッシュ内のほかのデータが追い出されることによって発生するキャッシュミスの頻度も削減できる。
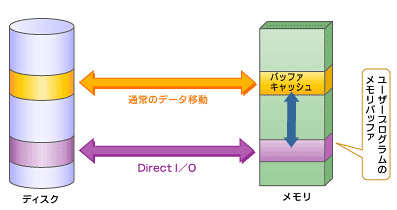 図3 Direct I/O
図3 Direct I/OXFSは、Direct I/Oをサポートしている。ファイルシステム内でI/Oのロックを取得し、Direct I/Oを使うプロセスのページキャッシュを安全に無効化する方法を取っている。
■XFSのアーキテクチャ
XFSのアーキテクチャは典型的なファイルシステムと似ているが、トランザクションマネージャとボリュームマネージャが特徴的である(図4)。
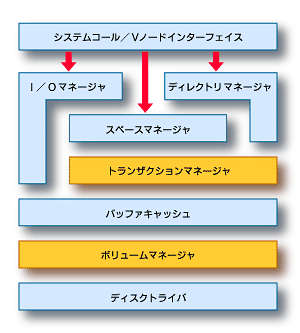 図4 XFSのアーキテクチャ
図4 XFSのアーキテクチャまた、すべてのUNIXファイルインターフェイスをサポートする、完全なPOSIXおよびXPG4(注)準拠のファイルシステムである。
注:X/Open Portability Guide。UNIXの標準化を推進しているThe Open Guideが発行している手引書。
XFSはモジュール化されており、各モジュールはファイルシステムの機能に対して責任を負う。
| モジュール | 機能 |
|---|---|
| スペースマネージャ | ファイルシステムの空き領域、iノードの割り当て、個々のファイル領域の管理 |
| I/Oマネージャ | ファイル入出力要求に応え、スペースマネージャと協調しながらファイルのための領域を獲得し、保つ |
| ディレクトリマネージャ | XFSの名前空間を実装 |
| バッファキャッシュ | 下の層であるボリュームマネージャからたびたびアクセスされるブロックの内容をキャッシュする |
| トランザクションマネージャ | 変更されたすべてのメタ・データをディスクの別の場所に記録する。この記録領域の分割は、ボリュームマネージャによって管理される |
| ボリュームマネージャ | XFSとその下のディスクデバイス間のレイヤとして存在する。ボリュームマネージャは、ストライピング、連結およびミラーリングをサポートする。ストライピングは入出力パフォーマンスの向上、連結は巨大なファイルシステムの構築、ミラーリングはシステムの信頼性の向上に役立つ |
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。