シングル・サインオンはメタディレクトリからXMLへ:ディレクトリ統合(4)
ディレクトリの普及とディレクトリ管理の難しさ
連載第3回『「並列」と「直列」から「統合型」の認証サーバへ』では、シングル・サインオンの実現方法についていくつかのパターンをご紹介しました。
認証を行うシステムにとってLDAPに代表されるディレクトリはユーザーID格納庫であり、スキーマやパスワード格納方法の互換性がなければ、やむを得ず複数のディレクトリサーバを使用しなくてはならない場合もあることをご説明しました。
最終回となる今回は、再びディレクトリに話題を戻して、現在企業が抱えているディレクトリの問題と、それに対するソリューション、将来の展望についてお話しします。
バラバラのユーザーIDが引き起こしている問題点とは?
企業システムの中にいろいろなディレクトリが存在しています。その中にはLDAPやActive Directoryのような典型的なディレクトリシステムもあります。Lotus Domino、 Microsoft Exchangeのようなメッセージ・コラボレーションシステム上には社員のe-mailアドレスが格納されています。社員マスタデータがメインフレーム上のデータベースやERPの人事システムの中にある企業もまだまだあります。
これらの複数のディレクトリに格納されている社員データはシステムを利用するという観点から見るとユーザーIDデータとして考えることができます。現在、これらのデータは別々のシステム上に保管され、個別に管理されているというのが実情です。メインフレームの一極集中化からクライアント/サーバ型処理や、マルチベンダの組み合わせのシステムに移行していく段階で、IDの管理はよくいえば分散化、悪くいえばバラバラになってしまいました。
具体的な問題点には以下のようなものが挙げられます。
エンドユーザーにとっての問題点
- 個々のID管理体系に対してユーザーIDやパスワードが別々になってしまうためにIDやパスワードを複数覚えておかなくてはならない
- 上記に付随して、覚え切れないパスワードなどを付せんに記入して参照したりすることによるセキュリティー情報の漏えい
管理者にとっての問題点
- エンドユーザーのパスワード忘れによる権限リボークの可能性が高くなり、パスワード回復(リセット)依頼によるヘルプデスク業務の増大
- アカウント管理の手間が増大(例:新入社員が入社すると複数のシステムに対してオペレータが登録操作しなければならない)
- アカウント管理を手動で行っているために、登録を申請してから実際に使えるようになるまで時間がかかる
- 管理が行き届かないために、不要アカウントがシステムに残りセキュリティーホールになる
- ディレクトリを保持するシステム資源の(悪い意味での)冗長性
結果的に、セキュリティレベルの低下と管理コストの増大、使い勝手の悪化が発生しています(図1)。
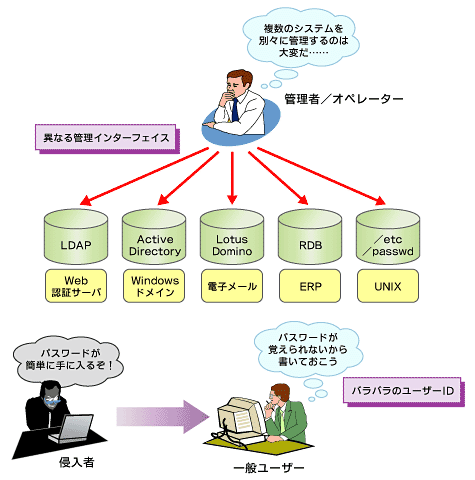 図1 バラバラのユーザーIDの問題点
図1 バラバラのユーザーIDの問題点ディレクトリ連携のアプローチ
メタディレクトリ/ディレクトリ同期型
第3回で説明したとおり、LDAPという標準化技術を使っていてもスキーマの互換性の問題が発生したり、そもそもLDAPサーバ以外のディレクトリやデータベースにアカウント、ユーザー、社員情報が入っていることもあります。
理想的には、1つのディレクトリに全データを統合し、すべての認証サーバやアプリケーションでそれを参照すればよいのですが、現状では物理的に1つのディレクトリに統合することは非常に困難であるといえます。
このような問題に対して、解決策として登場したのがメタディレクトリと呼ばれる技術や製品です。
メタディレクトリは、異なるディレクトリやデータベースに接続するコネクタと、ディレクトリやデータベース上にある属性値のフォーマットを必要があれば変換しコピーする機能を持っています。
メタディレクトリの製品としては、下記のような製品があります。
IBM : IBM Directory Integrator
100% Pure Javaで作られている製品。IBM Directory Serverを必要とせず 単独で動作する。
コネクタとしては、LDAP、Active Directory、Lotus Domino、MQ Series、JDBC などに対応する。また、ファイルや、HTTP、FTPなどディレクトリとは異なるプロトコルもディレクトリと同様に扱うことが可能。
Sun: Sun ONE MetaDirectory
Sun ONE Directory Serverのプラグインとして実行されるメタディレクトリ製品。同期するデータは一旦Sun ONE Directoryを経由する。
ダイレクトコネクタとインダイレクト(間接)コネクタが用意されていて、ダイレクトコネクタとしては、LDAPとOracleのようなデータベースをサポートしている。インダイレクトコネクタとしてはFile、,NT Domain、Active Directoryなどの接続をサポートしている。
Novell: Novell DirXML
Novell eDirectoryのプラグインとして実行されるメタディレクトリ製品。同期するデータは一旦Novell eDirectoryを経由する。
ドライバとして標準でActive Directory、Exchange、Lotus Notes、Netscape Directory Serverの接続をサポートしている。
Microsoft: Microsoft Metadirectory Service(MMS)
Windows2000上で稼働するメタディレクトリ製品。本稿で後述するプロビジョニングの考え方を導入しており、連携先のディレクトリにエージェントを導入する仕組みとなっている。Windows NT、Active Directory、Novell NDS、iPlanet Directory Server、Lotus Dominoなどに対するエージェントを標準で持っている。
ここではIBM Directory Integratorという製品の実装を例に説明します。
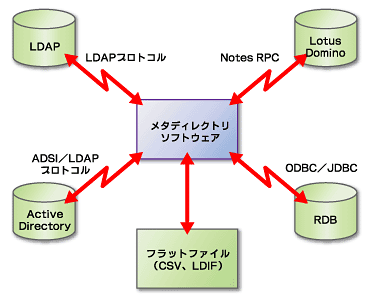 図2 メタディレクトリはさまざまなディレクトリに対するインターフェイスを持つ
図2 メタディレクトリはさまざまなディレクトリに対するインターフェイスを持つ上図(図2)のようにメタディレクトリソフトウェアは、さまざまなディレクトリ/データベースに接続するインターフェイスを持ちます(接続できるディレクトリ/データベースの種類は製品によって異なります)。
スキーマ、属性のマッピング
メタディレクトリはディレクトリ/データベースに接続してデータを取り出すわけですが、取り出したデータの形式(ディレクトリの世界ではこの形式のことをスキーマと呼んでいます)はそれぞれのディレクトリによって異なる可能性があります。社員番号は文字列として入力されていることもありますし、場合によっては数値型で入っていることもあります。また、データを取り出すときのフィールド名も問題になります。例えば、メールアドレスはe-mailというフィールドに入っていたりmailaddressというフィールドに入っていたりと異なる可能性があります。
メタディレクトリソフトウェアはマッピングテーブル(製品によっては変換テーブルと呼ぶ場合もあります)を定義できるようになっていて、異なるデータ形式であってもデータを渡せるようになっています。このマッピングテーブルを通して複数のディレクトリをつなぐと、あたかも1つの仮想的なディレクトリの裏側に実体のあるディレクトリがあるように見えます。「メタディレクトリ」の「メタ」とは仮想的に1つのディレクトリに見せているということに由来しています。
下図(図3)の例では、人事データ上の社員番号がu+番号という形式でLDAPのuidにマップされています。また、Suzuki Ichirohという名前が苗字と名前で分解され、それぞれcnとsnというLDAPの属性にマップされています。
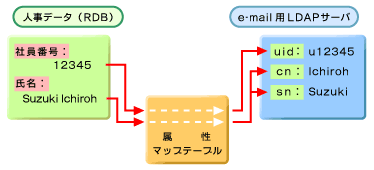 図3 変更の自動検知、取り込み
図3 変更の自動検知、取り込み2つ以上のディレクトリの内容を同期するには、ディレクトリの更新を検知して、更新のあったデータを取り込む必要があります。LDAP V3に準拠したサーバは更新が発生すると、その情報をイベントとしてクライアントに送信することができます。メタディレクトリソフトウェアは、この更新イベントを受信して更新の発生を知ることができます。
LDAP V3およびActive DirectoryではChangeLogという変更情報を記録することができます。これには変更情報が順番に書かれていくので、この情報を順番に取得すれば整合性を損なわずに更新情報を取得することが可能です。
メタディレクトリソフトウェアの中には、自分自身の中に独自のディレクトリを持ち、それを変更状況の比較対照のマスタとして使用するものもあります。つまり、接続相手のディレクトリと自分の中にあるディレクトリの情報を比較して違いがあれば変更があったと判断するものです。このとき、タイマを使って定期的にディレクトリに接続して情報を取得します。この方法は、LDAPやActive Directory以外の変更情報を検知するのが難しい場合の解決方法となります。ただしこの方法は、接続するディレクトリのデータが多くなるとパフォーマンスが悪くなるという欠点があるので、注意して採用する必要があります(図4)。
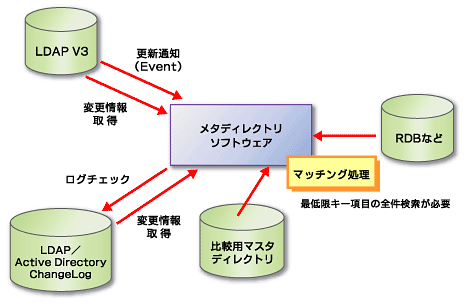 図4 更新検知方法
図4 更新検知方法複数のディレクトリから取り出したデータを結合する
一般的なメタディレクトリソフトウェアでは、データのマッピングは1対1、つまりあるディレクトリが持つ属性ともう1つ別のディレクトリが持つ属性に関して行われます。これに加えIBM Directory Integratorでは、複数のディレクトリから取り出したデータをマージして1つのディレクトリに入れることができます。単にデータ/アカウント情報を同期するだけでなく、さまざまなディレクトリから情報を集めてきて、あるユーザーの情報カタログを作成することも実現可能です。下図は、人事システムが作成するCSVファイルを読み込んで、ファイルの中にあるキー属性を基にActive DirectoryとRDBMSから属性を読み込んでLDAPにエントリを作る流れを示しています(図5)。
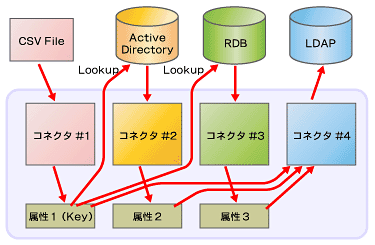 図5 複数のデータソースからデータを取得し、集めたデータで更新する
図5 複数のデータソースからデータを取得し、集めたデータで更新するメタディレクトリから統合ID管理へ
メタディレクトリは複数のディレクトリのデータを同期することで、管理にかかるコストを軽減し、ユーザーが使うIDとパスワードの組み合わせをシンプルにすることができます。しかしながらメタディレクトリで解決できるのは、比較的小規模で管理の要件が単純な場合に限定されるでしょう。なぜなら、メタディレクトリはデータの同期に主眼を置いており、アカウントを管理するという観点で見ると機能的に十分ではないからです。
いくつかのメタディレクトリ製品では、GUIのコンソールでメタディレクトリに接続された複数のディレクトリシステムを統合的に管理できるようになっていますが、それはディレクトリ上のユーザーIDやグループの作成、変更、削除ができるというシンプルなものが多いです。
ユーザーを管理するという面に着目すると、ユーザーアカウントのライフサイクルマネジメント、つまりアカウントの作成依頼を受けて作成し、要求があればアカウント情報を変更し、アカウントが不要になったら失効するという機能が必要です。しかし、一般的なメタディレクトリ製品でここまでカバーするのは追加で開発が必要になってしまいます。
Tivoli Identity Managerに代表される統合ユーザー管理ソフトウェアは、メタディレクトリ的なデータ同期機能を持ち、さらにユーザーIDのライフタイム管理機能を持っています。
(注:2003年3月7日現在、Tivoli Identity Manager V4.4は日本では発表されておりません。)
プロビジョニングとポリシーベースのID管理
プロビジョニング(Provisioning)という概念は最近出てきたものです。用語の解釈についてはいろいろな考え方があるのですが、ここではアカウントやアカウント属性の管理ライフサイクル(セットアップし、変更し、失効する)を自動化することと考えることにします。
プロビジョニングの管理対象をユーザーIDと考えると、企業で必要なのは、ユーザーIDを発行し、それを使う人の役割に応じて、必要なシステムに配布し、場合によってはそのIDに対するアクセス権限を設定することです。
いったん発行したIDに対しては、役割の変更があればその変更を自動的に反映する必要があります。また退社する人や長期にわたってシステムを使わない場合にはIDを失効したり、セキュリティ上の理由から一時的に無効にする必要もあるでしょう。
ID管理のライフサイクルの流れは以下のようにとらえることができます(図6)。
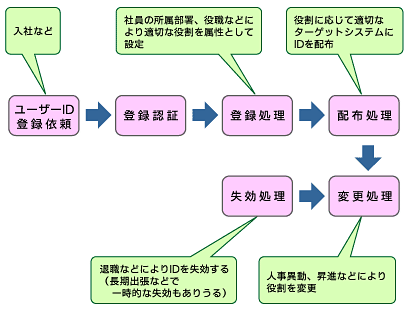 図6 ID管理のライフサイクル
図6 ID管理のライフサイクルユーザーの役割に応じて、適切なシステムに対する権限を与えることをロールベースのID管理もしくはポリシーベースのユーザー管理といいます。ユーザーIDのプロビジョニングを実現し、管理コストを削減するためには、ポリシーベースのユーザー管理が有効です。
Tivoli Identity Managerではユーザー情報はIdentity Managerが内部に持つ管理ディレクトリで一括管理されます。この管理情報は実際の企業組織の組織図を模したGUIで管理することが可能です。ポリシー情報のデータベースには、組織(グループとも表現できます)とその組織のシステム上の役割がマップされたものが格納されています。ユーザー情報ディレクトリとポリシーデータベースを基にIdentity ManagerはIDの管理を自動化します。
例えば、人事異動が発生した場合は、管理者はGUI上でユーザーオブジェクトを異動先の組織に入れる操作をします。このとき、承認が必要な場合には、複数の管理者(承認者)の間で承認ワークフローを実行する機能も持っています。Tivoli Identity Managerは自動的に組織の変更情報と、あらかじめ設定されていたポリシーを基に、管理対象のシステム/ディレクトリにユーザーIDやエントリを作成/変更/削除し、適切なアクセス権限を設定します。
Tivoli Identity Managerでは一般的なメタディレクトリソリューションとは異なり、管理対象のシステム/ディレクトリにエージェントモジュールを導入します。Identity ManagerとエージェントはSSLで暗号化されたHTTPで通信します。管理対象のシステムやディレクトリなどがバージョンアップした場合でも、エージェントの入れ直しのみで対応ができるため、Identity Managerのサーバ側の変更が必要ないのがメリットです。また、UNIXなどのOSに対してもアカウント管理コマンドをローカルで発行できるので管理対象に含めることができます。
また、Tivoli Identity Managerはエンドユーザーに対し、以下のような機能を提供します。
- エンドユーザーによるWeb経由のパスワードの変更。変更情報はIdentity Managerのエージェント経由で管理対象のシステム/ディレクトリに反映される。あらかじめ設定しておいたパスワードポリシー(使用文字の制限など)を適用することも可能
- パスワードを忘れてしまった場合の復旧処理として「合言葉」を事前に設定しておき、合言葉によるパスワードの再発行
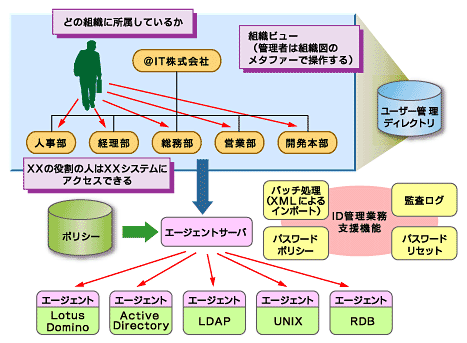 図7 ポリシーベースのID管理概要(Tivoli Identity Managerの例)
図7 ポリシーベースのID管理概要(Tivoli Identity Managerの例)ポリシーベースの管理機能(図7)は非常に注目されており、マイクロソフトもメタディレクトリソリューションであるMMSにプロビジョニングを実現するエージェント機能を追加するといわれていますし、Netegrity社のIdentity Minderもプロビジョニングを実現する製品です。
メタディレクトリと、プロビジョニング、どちらのアプローチがよいのでしょうか? 前にも触れたとおり、管理対象の規模に依存すると思いますが、場合によってはメタディレクトリとプロビジョニングを両方採用するのが妥当な場合もあるでしょう。プロビジョニング型の製品はIDを扱うことに主体を置いているので、データを操作したりするのには向いていません。
例えば、 上でメタディレクトリ製品として紹介したTivoli Identity Managerのようなプロビジョニング型の製品では、複数のデータソースから属性を集めてきて、ディレクトリ更新用のデータにするような処理はできません。つまり、データを加工する必要があるところにだけ、メタディレクトリ型の製品を適用し、全体はプロビジョニング型の製品で管理するというアプローチも有効であるといえます。
XMLベースで統合ID管理する時代へ
WebサービスではXMLを積極活用しようとしていますが、ID管理の分野でもXMLベースで企業対企業、企業対組織のID情報の交換を標準化しようという動きが出てきています。Webサービスを使ううえで、IDの管理は非常に重要なので、これは自然の流れです。
標準化団体のOASISでは、PSTC(Provisioning Service Technical Committee)という部会が、ID管理を含んだプロビジョニングシステムの標準化を進めています。OASIS PSTCではXRPM(eXtensible Resource Provisioning Management)やADP(Active Digital Profile)といった標準規格をベースにしています。このような標準化に対する作業は現在途上にありますが、企業間の安全なID管理、ID情報交換を考えるとこれらの標準化動向に注目していく必要があるでしょう。
連載を終えて
ディレクトリ統合の連載はいかがでしたでしょうか? 企業システムを統合して管理することの意味、その仕組みや方向性をご理解いただければ幸いです。
ご愛読ありがとうございました
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。