特集CrusoeはノートPCに革新をもたらすのか?2.Crusoeの秘密を解くデジタルアドバンテージ/Massa POP Izumida |
|

Crusoeは、WindowsをOSに採用する軽量なノートPC向けの「TM5400」と、Web端末やモバイル クライアント向けの「TM3200」の2種類をラインアップする(TM3200は、発表当初、TM3120と呼ばれていたもの)。さらに、TransmetaのPC EXPO2000に関するニュースリリースによれば、TM5400の後継としてTM5600を開発しているという。TM5400とTM3200は、1次キャッシュの容量、2次キャッシュ内蔵の有無、メモリ インターフェイス、LongRunのサポートの有無などが異なるが、128bitsのVLIW構造とコードモーフィングを採用する点は同じだ。
| TM5400 | TM3200 | |
| 動作クロック | 500MHz/700MHz | 300MHz/400MHz |
| 製造プロセス | 0.18μm | 0.22μm |
| 命令長 | 128bits(4演算)/64bits(2演算) | 128bits(4演算)/64bits(2演算) |
| 汎用レジスタ | 32bitX64本/シャドウ:48本 | 32bitX64本/シャドウ:48本 |
| 浮動小数点レジスタ | 80bitX32本/シャドウ:16本 | 80bitX32本/シャドウ:16本 |
| 1次キャッシュ | 128Kbytes | 96Kbytes |
| 2次キャッシュ | 256Kbytes同梱 | 外部 |
| 内蔵RAM | 命令用8Kbytes/データ用8Kbytes | 命令用8Kbytes/データ用4Kbytes |
| 演算ユニット | ALUX2、ロード/ストア、分岐、浮動小数点/マルチメディア | ALUX2、ロード/ストア、分岐、浮動小数点/マルチメディア |
| LongRun対応 | あり | なし |
| メイン メモリ | DDR SDRAM | SDRAM |
| アップグレード メモリ | SDRAM | − |
| ノースブリッジ | 同梱 | 同梱 |
| パッケージ | 474ピンBGA | 474ピンBGA |
| Fab | IBM | IBM |
| ダイ サイズ | 73平方ミリ | 77平方ミリ |
| TM5400とTM3200の違い | ||
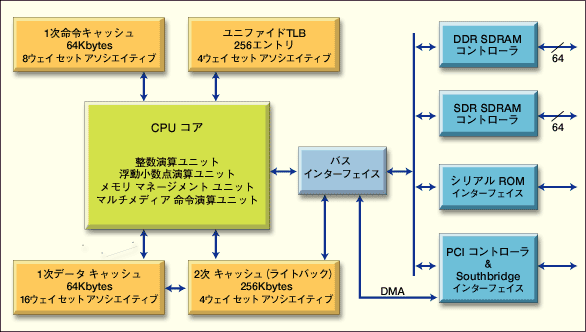 |
| TM5400のブロック図 |
| TM5400では、ノースブリッジを内蔵しており、メモリ インターフェイスとしてDDR SDRAMをサポートする。ノースブリッジを内蔵したことで、外部バスへのインターフェイスが大幅に減り、システム全体の低消費電力化に貢献している。 |
コードモーフィングやLongRunについては、ニュース解説「Crusoeはx86プロセッサの新境地を開くのか?」を参照していただきたい。
ところで、コードモーフィング ソフトウェアとVLIWの組み合わせという斬新なマイクロアーキテクチャを採用したCrusoeには、数々の疑問がある。そこで、Crusoeに関する疑問をプロセッサ アーキテクトのMassa POP Izumida氏に推測を含めてお答えいただいた。
![]() Crusoeのマイクロアーキテクチャを見て、プロセッサ
アーキテクトとしての感想をまずお聞かせください。
Crusoeのマイクロアーキテクチャを見て、プロセッサ
アーキテクトとしての感想をまずお聞かせください。
![]() x86とのコード互換性を持たせることを、x86とは異なるネイティブコードのマシンの上でソフトウェアにより実現するというのは、過去、いろいろな人が考えた実現方法ではないかと思う。x86は、x86たるゆえんの複雑な命令自体がマイクロコードで実現された一種のファームウェアであった。その複雑さをハードウェアでなくソフトウェアで吸収しようとするのは、ある意味自然な考えだろう。実際、以前DECがAlphaプロセッサで試みた「FX!32」のように、Crusoeとはやり方が異なるものの、ソフトウェアによるx86互換性の実現は行われてきている。実は、このようなソフトウェアを使ったx86互換のアプローチは、FX!32以前にもいろいろと試みられている。しかし、こうしたソフトウェアによる互換性の実現は、ネイティブなハードウェアによるx86プロセッサをコスト
パフォーマンスで越えることができなかった。
x86とのコード互換性を持たせることを、x86とは異なるネイティブコードのマシンの上でソフトウェアにより実現するというのは、過去、いろいろな人が考えた実現方法ではないかと思う。x86は、x86たるゆえんの複雑な命令自体がマイクロコードで実現された一種のファームウェアであった。その複雑さをハードウェアでなくソフトウェアで吸収しようとするのは、ある意味自然な考えだろう。実際、以前DECがAlphaプロセッサで試みた「FX!32」のように、Crusoeとはやり方が異なるものの、ソフトウェアによるx86互換性の実現は行われてきている。実は、このようなソフトウェアを使ったx86互換のアプローチは、FX!32以前にもいろいろと試みられている。しかし、こうしたソフトウェアによる互換性の実現は、ネイティブなハードウェアによるx86プロセッサをコスト
パフォーマンスで越えることができなかった。
その点は、現状のCrusoeにおいても同様で、最先端のx86プロセッサを越えるような性能は実現できていない。しかし、x86プロセッサとの対抗軸に、消費電力といった性能とは相反する異なった指標を持ち出すことで、自分の土俵を築いた点が立派といえるだろう。性能面で最先端のx86プロセッサを越えられなくても、消費電力が圧倒的に小さければ、そこに用途があるはずだという着眼点を誉めるべきかもしれない。
![]() 第1弾の製品が出ても、次々と性能の向上が実現できなければ成功は望めないと思います。Crusoeのマイクロアーキテクチャを見て、性能向上は容易だと思われますか?
第1弾の製品が出ても、次々と性能の向上が実現できなければ成功は望めないと思います。Crusoeのマイクロアーキテクチャを見て、性能向上は容易だと思われますか?
![]() いわゆるスーパースカラのx86プロセッサでは、ハードウェアでx86命令を複数のオペレーションに分解し、分解した細かなオペレーションについてスケジューリングを施して実行していくのが定石であった。この点Crusoeでは、スーパースカラのx86がハードウェアで行っていた細かなオペレーションへの分解とその後のスケジューリングまでをソフトウェアで行う必要があり、ソフトウェアの負担は非常に重く、ハードウェアの負担は相対的に軽くなっている。
いわゆるスーパースカラのx86プロセッサでは、ハードウェアでx86命令を複数のオペレーションに分解し、分解した細かなオペレーションについてスケジューリングを施して実行していくのが定石であった。この点Crusoeでは、スーパースカラのx86がハードウェアで行っていた細かなオペレーションへの分解とその後のスケジューリングまでをソフトウェアで行う必要があり、ソフトウェアの負担は非常に重く、ハードウェアの負担は相対的に軽くなっている。
ハードウェアの負担が相対的に軽いということは、ハードウェア的な性能(周波数に代表される)を向上していくうえではよい特性である。比較的小さな設計チームでも性能を向上させていく作業が可能だろう。しかし、性能向上は設計だけでなく、製造プロセスまでも含めた総力戦であり、各社が使えるリソースにはそれぞれの事情があるので、性能向上が容易だといっても、常にリードできるとは限らない。過去、x86互換でインテルと張り合った会社は、AMDを除き、よいアイディアがあったとしても、圧倒的なインテルの物量作戦に対抗して製品を出し続けることができなくて脱落している。その点で、性能向上作業の負担が相対的に軽いことは、大事なポイントではある。
![]() Pentium
IIIやAthlonといった現在のx86プロセッサに比べて、Crusoeは実行ユニットの数が少ないように思えますが、この点が性能面での欠点にはならないのでしょうか?
Pentium
IIIやAthlonといった現在のx86プロセッサに比べて、Crusoeは実行ユニットの数が少ないように思えますが、この点が性能面での欠点にはならないのでしょうか?
![]() ALU(整数論理演算ユニット)が2個あれば、1個のロード/ストア
ユニット、1個の分岐と釣り合う。むしろ、ALUだけをこれ以上増やしても、アンバランスになるだけだ。ALUの数を増加させるには、まずロード/ストア ユニットの増強を行う必要がある。ただ、ロード/ストア
ユニットを複数実装するのは、ハードウェアが非常に大きくなるので、現時点の選択としては適当でないといえるだろう。浮動小数演算ユニットおよびマルチメディア命令ユニットについても同様だ。
ALU(整数論理演算ユニット)が2個あれば、1個のロード/ストア
ユニット、1個の分岐と釣り合う。むしろ、ALUだけをこれ以上増やしても、アンバランスになるだけだ。ALUの数を増加させるには、まずロード/ストア ユニットの増強を行う必要がある。ただ、ロード/ストア
ユニットを複数実装するのは、ハードウェアが非常に大きくなるので、現時点の選択としては適当でないといえるだろう。浮動小数演算ユニットおよびマルチメディア命令ユニットについても同様だ。
![]() Crusoeは、ノースブリッジをプロセッサ
ダイに同梱していますが、ダイ サイズが大きくなり、製造面で不利になるのではないでしょうか?
Crusoeは、ノースブリッジをプロセッサ
ダイに同梱していますが、ダイ サイズが大きくなり、製造面で不利になるのではないでしょうか?
![]() むしろ、Crusoeのような構造を持つCPUにとって、ノースブリッジを搭載することは必然ともいえる。もし、ノースブリッジが別チップになっていれば、高速で動く外部バス*1は電力消費を増大させ、Crusoeシステムの低消費電力化を妨げるだろう。そこで、プロセッサとノースブリッジを1チップに統合し、低速なPCIバスと不可欠のDRAMバスだけを外へ出すというのは技術的に当然ともいえるアプローチだ。また、コードモーフィング
ソフトウェアが必要になるので、Crusoe専用のノースブリッジが必須である。Pentium用やPentium III用といったものは使いにくい。どうせ専用のノースブリッジが必要になるのならば、CPUに集積したほうがよい。マルチプロセッサ用のサーバ向けCPUではないのだから、別チップにする必然性はないだろう。
むしろ、Crusoeのような構造を持つCPUにとって、ノースブリッジを搭載することは必然ともいえる。もし、ノースブリッジが別チップになっていれば、高速で動く外部バス*1は電力消費を増大させ、Crusoeシステムの低消費電力化を妨げるだろう。そこで、プロセッサとノースブリッジを1チップに統合し、低速なPCIバスと不可欠のDRAMバスだけを外へ出すというのは技術的に当然ともいえるアプローチだ。また、コードモーフィング
ソフトウェアが必要になるので、Crusoe専用のノースブリッジが必須である。Pentium用やPentium III用といったものは使いにくい。どうせ専用のノースブリッジが必要になるのならば、CPUに集積したほうがよい。マルチプロセッサ用のサーバ向けCPUではないのだから、別チップにする必然性はないだろう。
さらに消費電力の低減を実現するならば、チップ パッケージの端子数の制限もあるが、さらにサウスブリッジやグラフィクス、I/Oまで専用のものをプロセッサに集積するべきだが、そこまではできなかったのだろう。将来的には、こうした1チップPCへ向かう可能性もあるのではないかと思う。
![]() コードモーフィング
ソフトウェアを使うことによる性能低下の影響をどのように考えますか?
コードモーフィング
ソフトウェアを使うことによる性能低下の影響をどのように考えますか?
![]() 当然、ネイティブのVLIWコードから見れば、実行すべきデータ操作に加えて、コードモーフィングも行う必要があるので、余分なオーバヘッドは必ずある、というべきだろう。しかし、ユーザーはコードモーフィングを通じてしかCrusoeを操れず、ネイティブなコードの実行速度というのはユーザーからは直接見えないのだから、性能低下を直接認識することはできないだろう。コードモーフィングの結果は、ユーザーから操作できないメイン
メモリの一部に割り付けられたキャッシュに保存される。このため、繰り返しの多いソフトウェアほど、コードモーフィングのオーバヘッドの占める割合が低下する。逆にどのルーチンも1回だけしか実行しないようなプログラムは、オーバヘッドの割合が多くなるから、間接的には、このようなケースを比べてオーバヘッドを推測できるだろう。とはいえ、やはりCrusoeは、コードモーフィング
ソフトウェアと一体化したプロセッサであり、それによる性能低下を議論するのはあまり意味のないことではないかと思う。
当然、ネイティブのVLIWコードから見れば、実行すべきデータ操作に加えて、コードモーフィングも行う必要があるので、余分なオーバヘッドは必ずある、というべきだろう。しかし、ユーザーはコードモーフィングを通じてしかCrusoeを操れず、ネイティブなコードの実行速度というのはユーザーからは直接見えないのだから、性能低下を直接認識することはできないだろう。コードモーフィングの結果は、ユーザーから操作できないメイン
メモリの一部に割り付けられたキャッシュに保存される。このため、繰り返しの多いソフトウェアほど、コードモーフィングのオーバヘッドの占める割合が低下する。逆にどのルーチンも1回だけしか実行しないようなプログラムは、オーバヘッドの割合が多くなるから、間接的には、このようなケースを比べてオーバヘッドを推測できるだろう。とはいえ、やはりCrusoeは、コードモーフィング
ソフトウェアと一体化したプロセッサであり、それによる性能低下を議論するのはあまり意味のないことではないかと思う。
![]() コードモーフィングの結果をキャッシュするということですが、これはサブルーチン単位なのでしょうか、それとも命令単位なのでしょうか?
コードモーフィングの結果をキャッシュするということですが、これはサブルーチン単位なのでしょうか、それとも命令単位なのでしょうか?
![]() Transmeta社のCEO(最高経営責任者)であるデビット
ディッツェル(Devid Ditzel)氏の説明を聞いたかぎりでは、x86命令がモーフィング後のネイティブ命令と一意に対応するということはないようだ。x86命令は、いったんバラバラなオペレーションに分解され、前後の命令列から発生したほかのオペレーションと混ぜられたうえでスケジューリングされるので、同じx86命令コードが前後の命令列によって異なる表現になるということもありえる。また、サブルーチン単位という表現にも問題はある。コードモーフィングでは、たとえば「Microsoft
Word」というx86のプログラムを静的に変換して、ネイティブなVLIWのコードからなる「Microsoft Word」のプログラムには変換できない。つまり、巨視的なプログラムの構造までは立ち入らないということである。あくまで実行時にデコードされる命令列を解析、変換してキャッシュするだけなので、サブルーチンといったプログラムの意味的構造を示す用語をこの文脈で使うのは適当でないと思う。その命令列がサブルーチンの一部か、全部か関係なしに、ひとつかみ(数十個命令)を固まりとして解析してスケジューリングしていく、と考えたほうがよいだろう。
Transmeta社のCEO(最高経営責任者)であるデビット
ディッツェル(Devid Ditzel)氏の説明を聞いたかぎりでは、x86命令がモーフィング後のネイティブ命令と一意に対応するということはないようだ。x86命令は、いったんバラバラなオペレーションに分解され、前後の命令列から発生したほかのオペレーションと混ぜられたうえでスケジューリングされるので、同じx86命令コードが前後の命令列によって異なる表現になるということもありえる。また、サブルーチン単位という表現にも問題はある。コードモーフィングでは、たとえば「Microsoft
Word」というx86のプログラムを静的に変換して、ネイティブなVLIWのコードからなる「Microsoft Word」のプログラムには変換できない。つまり、巨視的なプログラムの構造までは立ち入らないということである。あくまで実行時にデコードされる命令列を解析、変換してキャッシュするだけなので、サブルーチンといったプログラムの意味的構造を示す用語をこの文脈で使うのは適当でないと思う。その命令列がサブルーチンの一部か、全部か関係なしに、ひとつかみ(数十個命令)を固まりとして解析してスケジューリングしていく、と考えたほうがよいだろう。
![]() 基本的にイン
オーダーで実行しているようですが、レジスタの依存関係の解決はどのように行っているのでしょうか。また、アウト オブ オーダーに比べて効率が悪いのではないかと思いますが、そのようなことはないのでしょうか?
基本的にイン
オーダーで実行しているようですが、レジスタの依存関係の解決はどのように行っているのでしょうか。また、アウト オブ オーダーに比べて効率が悪いのではないかと思いますが、そのようなことはないのでしょうか?
![]() アウト オブ オーダーのほうが効率よいというのは大間違いだ。依存関係がバラバラなイン
オーダーよりは確かに効率がよいとはいえるが、アウト オブ オーダーは依存関係の辻褄が合わなくならないように、いろいろ注意して小細工をする必要がある。一方、あらかじめ依存関係が解決済みのイン
オーダーで出来るならば小細工もいらず、淡々と実行し続けるだけなので、それに越したことはない。一般にVLIWの場合、こういった依存関係の解決はソフトウェア(Crusoeの場合、コードモーフィング)にまかされているから、実行するときにはすでに順に実行するだけの状態になっているはずだ。
アウト オブ オーダーのほうが効率よいというのは大間違いだ。依存関係がバラバラなイン
オーダーよりは確かに効率がよいとはいえるが、アウト オブ オーダーは依存関係の辻褄が合わなくならないように、いろいろ注意して小細工をする必要がある。一方、あらかじめ依存関係が解決済みのイン
オーダーで出来るならば小細工もいらず、淡々と実行し続けるだけなので、それに越したことはない。一般にVLIWの場合、こういった依存関係の解決はソフトウェア(Crusoeの場合、コードモーフィング)にまかされているから、実行するときにはすでに順に実行するだけの状態になっているはずだ。
![]() 分岐予測はどのレベルで行っているのでしょうか?
分岐予測はどのレベルで行っているのでしょうか?
![]() コードモーフィング ソフトウェアは、確定していない命令ブロックの実行も投機的にスケジュールするようなので、ハードウェアは投機が失敗した場合のリカバリの手段を持っているようだ。とすれば、いわゆる分岐予測にあたる機能はコードモーフィング
ソフトウェアが行っていると考えるべきだろう。ただし、どの程度高度な予測をしているのかは不明だ。まさか決め打ちということはないだろうが。
コードモーフィング ソフトウェアは、確定していない命令ブロックの実行も投機的にスケジュールするようなので、ハードウェアは投機が失敗した場合のリカバリの手段を持っているようだ。とすれば、いわゆる分岐予測にあたる機能はコードモーフィング
ソフトウェアが行っていると考えるべきだろう。ただし、どの程度高度な予測をしているのかは不明だ。まさか決め打ちということはないだろうが。
![]() 実行ユニットを変更すると、コードモーフィング
ソフトウェアを大幅に変更する必要があり、むしろ開発が大変になるのではないでしょうか?
実行ユニットを変更すると、コードモーフィング
ソフトウェアを大幅に変更する必要があり、むしろ開発が大変になるのではないでしょうか?
![]() これはあくまで推測だが、フロント側の解析、分解部分の変更はほとんど不要で、バックエンド側のスケジューリングとコード生成部分は手直しが必要になるのだと思う。簡単と言い切るほどではないが、それほど大変ではないのではないかと予想している。
これはあくまで推測だが、フロント側の解析、分解部分の変更はほとんど不要で、バックエンド側のスケジューリングとコード生成部分は手直しが必要になるのだと思う。簡単と言い切るほどではないが、それほど大変ではないのではないかと予想している。
![]() インテルのSpeedStepでは、一度プロセッサをスリープモードに移行してから、動作電圧と動作クロックの変更を行っているようですが、Crusoeが採用するLongRunではどのように、動作電圧の変更を行っているのでしょうか?
命令の実行中にも動的に行えるのでしょうか?
インテルのSpeedStepでは、一度プロセッサをスリープモードに移行してから、動作電圧と動作クロックの変更を行っているようですが、Crusoeが採用するLongRunではどのように、動作電圧の変更を行っているのでしょうか?
命令の実行中にも動的に行えるのでしょうか?
![]() 切り替えには、1ステップ20マイクロ秒ほど必要と公表しているので、CPU自体は一度、待機状態になっているようだ。
切り替えには、1ステップ20マイクロ秒ほど必要と公表しているので、CPU自体は一度、待機状態になっているようだ。
![]() 半導体技術の一般論として、動作電圧と動作クロックの組み合わせは自由に選択できるものなのでしょうか?
半導体技術の一般論として、動作電圧と動作クロックの組み合わせは自由に選択できるものなのでしょうか?
![]() 種々の物理的要因に制限されるが、制限内なら自由に選択できる。通常、動作クロックを横軸に、動作電圧を縦軸にとって、正常に動作が行える範囲を調べた図を「シュムープロット」と呼び、動作電圧可変の半導体でなくても、普通はデータを取っているから、これ見れば選択できる範囲がひと目で分かる。通常、どこの半導体会社も学会発表にはシュムープロットを見せるが、製品には付属しない。これは、異なる動作電圧とクロックの組み合わせについて、電気的特性を保証するのが面倒だからだ。そこで普通の半導体では、電源電圧をある範囲に固定して、最大動作クロックを定義しているのである。一般に電源電圧が下がれば、動作可能な周波数の上限も下がる。電源電圧の上限は、製造プロセスに依存しており、微細なプロセスほど許容できる電圧は低い。電源電圧がトランジスタのしきい値電圧以下になれば、動作しないのは自明であるが、それ以前の電圧で動作しなくなることが多い。周波数の上限は、そのチップのクリティカルパスの遅延によって定まるが、電圧条件により、表面化するクリティカルパスが異なる場合があるので、一意には決まらない。下限は回路の形式による(プロセッサの動作クロックについては、頭脳放談「第2回
1GHz! 世界を支配するクロックなるモノ」を参照のこと)。
種々の物理的要因に制限されるが、制限内なら自由に選択できる。通常、動作クロックを横軸に、動作電圧を縦軸にとって、正常に動作が行える範囲を調べた図を「シュムープロット」と呼び、動作電圧可変の半導体でなくても、普通はデータを取っているから、これ見れば選択できる範囲がひと目で分かる。通常、どこの半導体会社も学会発表にはシュムープロットを見せるが、製品には付属しない。これは、異なる動作電圧とクロックの組み合わせについて、電気的特性を保証するのが面倒だからだ。そこで普通の半導体では、電源電圧をある範囲に固定して、最大動作クロックを定義しているのである。一般に電源電圧が下がれば、動作可能な周波数の上限も下がる。電源電圧の上限は、製造プロセスに依存しており、微細なプロセスほど許容できる電圧は低い。電源電圧がトランジスタのしきい値電圧以下になれば、動作しないのは自明であるが、それ以前の電圧で動作しなくなることが多い。周波数の上限は、そのチップのクリティカルパスの遅延によって定まるが、電圧条件により、表面化するクリティカルパスが異なる場合があるので、一意には決まらない。下限は回路の形式による(プロセッサの動作クロックについては、頭脳放談「第2回
1GHz! 世界を支配するクロックなるモノ」を参照のこと)。
![]() LongRunでは、どのように必要とされる性能を把握しているのでしょうか?
LongRunでは、どのように必要とされる性能を把握しているのでしょうか?
![]() どうやらコードモーフィング
ソフトウェアは、OSなどが管理している省電力モードの起動頻度や期間などを、たまに(20ミリ秒単位で)覗き見しているという。そうして、CPUが停止している時間が多いようだと判断すれば、動作クロックを落としたり、逆であれば速くしたりして、その結果を再調査し、フィードバックをかけて適正な動作クロックを把握しているようだ。
どうやらコードモーフィング
ソフトウェアは、OSなどが管理している省電力モードの起動頻度や期間などを、たまに(20ミリ秒単位で)覗き見しているという。そうして、CPUが停止している時間が多いようだと判断すれば、動作クロックを落としたり、逆であれば速くしたりして、その結果を再調査し、フィードバックをかけて適正な動作クロックを把握しているようだ。
![]() SpeedStepやAMDのPowerNow!テクノロジなど、動作クロックと動作電圧の両方を変更する省電力技術が最近目立ちますが、このほかに省電力技術として有望なものはないのでしょうか?
SpeedStepやAMDのPowerNow!テクノロジなど、動作クロックと動作電圧の両方を変更する省電力技術が最近目立ちますが、このほかに省電力技術として有望なものはないのでしょうか?
![]() 研究レベルでは、非同期回路設計技術が注目されている。現存のほとんどのデバイスは同期回路設計であり、かつ非同期回路設計に適した商用ツールなどは現れていないので、応用はまだしにくいが、非同期回路は同期回路にくらべ数分の1から数パーセントくらいに消費電力が減るといわれている。また、SOI(Silicon
On Insulator:絶縁層上シリコン薄膜)*1も、人により意見の差があるが、うまくいけば消費電力が格段に下がる技術である。専門的になるが、これによりジャンクション容量がなくなる(ペリフェリ容量は残る)ので、省電力にもなり、高速化も期待できるというわけだ。
研究レベルでは、非同期回路設計技術が注目されている。現存のほとんどのデバイスは同期回路設計であり、かつ非同期回路設計に適した商用ツールなどは現れていないので、応用はまだしにくいが、非同期回路は同期回路にくらべ数分の1から数パーセントくらいに消費電力が減るといわれている。また、SOI(Silicon
On Insulator:絶縁層上シリコン薄膜)*1も、人により意見の差があるが、うまくいけば消費電力が格段に下がる技術である。専門的になるが、これによりジャンクション容量がなくなる(ペリフェリ容量は残る)ので、省電力にもなり、高速化も期待できるというわけだ。![]()
| *1 シリコン層とトランジスタ層の間に酸化絶縁層を設けたシリコンウエハーの総称。SOIを使用することで、電流がトランジスタから別のトランジスタへ移動するときに、シリコン層が電流の一部を吸収するのを防ぐことで、その結果、チップの動作に必要とされる電流容量を下げることが可能になる。 |
| 関連記事(PC Insider内) | |
| Crusoeはx86プロセッサの新境地を開くのか? | |
| 頭脳放談「第2回 1GHz! 世界を支配するクロックなるモノ」 | |
| 関連リンク | |
| テクノロジーショーケース:シリコン・オン・インシュレーター | |
| INDEX | ||
| [特集]CrusoeはノートPCに革新をもたらすのか? | ||
| コラム:PC EXPO2000で披露されたCrusoe搭載ノートPC | ||
| 1.Crusoe成功の秘密 | ||
| 2.Crusoeの秘密を解く | ||
| 「PC Insiderの特集」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





