|
特集 5. 大容量化するメイン・メモリを支える技術(2) |
|

大容量のメイン・メモリは障害発生のもと?
では実際にIAサーバのメモリ障害対策は、1bit訂正/2bit検出のECCで十分なのだろうか? 結論からいえば、次第に十分とはいえなくなりつつある。その理由の1つは、IAサーバに求められるメモリ容量の増加だ。前述のように、ミッドレンジからエンタープライズのIAサーバにもなると、最近では数十G〜数百Gbytesものメイン・メモリを搭載可能だが、そのときのメモリ・チップの数は膨大になる(例えば512Mbitsのメモリ・チップで256Gbytesを実装するには、データの分だけで512個も必要)。すると、たとえメモリ・チップ1個あたりの不良発生率が極小でも、チップ数が非常に多いとメモリ・サブシステム全体での不良率は無視できない大きさになりかねない。
通常、DIMMに搭載されるメモリ・チップは、1個で4/8/16bitのデータを1回で保存するため、メモリ・チップが1個故障すると一気に4〜16bitのデータが失われてしまう。これでは1bit訂正/2bit検出のECCはまったく役に立たない。このままでは大規模なデータウェアハウスなど、より重要かつクリティカルな用途ほど、致命的なメモリの障害が発生しやすいことになってしまう。
メモリ・チップ1個あたりの容量が大きくなればチップ数は減るものの、今度は別の問題が生じる。それは、メモリ・チップ(DRAMチップ)内の記憶素子(メモリ・セル)の集積度が高まることで、DRAMチップに生じるさまざまなエラーが多bitに及ぶ可能性が高まるからだ。一例としてはDRAMチップのソフト・エラー*3が挙げられる。
| *3 現在のDRAMチップのソフト・エラーとは、宇宙空間から大気圏を突き抜けて地上に降り注ぐ宇宙線がメモリ・チップに衝突して、メモリ・セルのデータ保持状態(1か0か)を変化させてしまう、というものだ。DRAMのメモリ・セルは、そこに蓄積される電荷量で2値情報を保持するため、宇宙線が衝突するときのエネルギーで電荷が失われることは、データの損失を意味する。 |
メモリ・チップの集積度が高まるほど、1bit分の記憶素子のサイズは小さくなり、1回の宇宙線の衝突でその影響を受ける記憶素子の数も増えることになる。その影響の度合いは宇宙線が持つエネルギー次第だが、もし複数のbitにエラーが生じた場合、それは1データ内での多bitエラーである可能性は高く、1bit訂正/2bit検出のECCが役に立たない可能性も高まる。原理的には、これは全セグメントのIAサーバに影響する問題といえる。
普及の始まった多bitエラー対策技術
こうした多bitエラーの対策の1つとして、最近のIAサーバでは、ECCのbit数を増やしている。多いのは、従来は72bit(データ64bit+ECC 8bit)だった単位データ・サイズを、2倍の144bit(データ128bit+ECC 16bit)に延長することでECCのbit数を2倍に増やす、という方法だ(実際には、16bitのうち一部をECC、残りを予備のデータ格納用bitとして利用する、という手法もある)。128bitのデータに対してECCを16bit用意すると、最大4bitまでのエラーを訂正できる。
単位データ・サイズが144bitの場合、データとECCそれぞれのbit数の比率は従来と同じ8:1なので、わざわざ144bit幅のDIMMを特別に用意しなくても、汎用の72bit ECC DIMMを2枚セットで使えばデータ128bit+ECC 16bitは実現できる。つまり、従来の72bit DIMMに対応するメモリ・バスを2系統用意し、並列にアクセスすれば144bit幅が得られるわけだ。16bit ECCの実装は、従来はミッドレンジの一部とエンタープライズに限られていたが、2002年にはワークグループでも実装が始まっている。
そのほかの多bitエラー対策としては、下図のようにデータ64bit+ECC 8bitを、1bitずつDRAM 1チップに格納していくことでチップの故障に耐える、という手法がある。これはIBMが開発したメモリ・エラー検出/訂正技術「Chipkill」に含まれる主要な技術の1つだ。
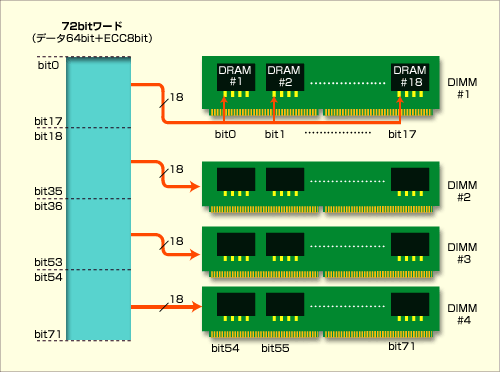 |
| Chipkillに含まれるエラー検出/訂正技術 |
| データ64bit+ECC 8bitを各DRAMチップに1bitずつ分散させると、たとえ1チップ故障しても、それは1bit分のエラーでしかない。この図のように4bitデータのDRAMチップの場合、異なるアドレスに格納された4個のデータにおいて、それぞれ1bitずつエラーが生じることに帰結できるからだ。これなら、従来のデータ64bit+ECC 8bitでも訂正可能だ。ただし、メモリの増設は4枚単位でしなければならず、使い勝手が悪くなりかねない。 |
IBM以外のサーバ・メーカーも多bitエラーの検出/訂正技術を開発して自社製品に実装しており、現在は4bit程度のエラー訂正機能がIAサーバに普及し始めたところだ。それでも、IAサーバを選択するポイントの1つであることは間違いない。各社の実装方法は微妙に異なっていて、効果も少しずつ違っているので、選定時には仕様をよく確認したい(使用できるメモリ・チップの種類が制限されていることもある)。
そのほかにも、さらに高度なメモリ・エラー対策技術がIAサーバ向けに開発済みまたは開発中である。「高度」とは、メモリ・モジュール単位のエラー対策や、サーバを稼働中にメモリ・モジュールを交換して正常な状態に戻す、といったものだ。
| 名称 | 概要 | 効果 |
| ホットスペア | 搭載している全メモリ・モジュールのうち一部をスペア(予備の部品)として予約しておく。もし、あるメモリ・モジュールで訂正可能なエラーが発生したら、そのデータをすべてスペアにコピーし、以後のアクセスをスペアに切り替える | エラーの発生したメモリ・モジュールを使い続けないで、正常なスペアのメモリ・モジュールを利用できる。スペアへのコピーや切り替えは動的に行われるため、サーバの処理は継続される |
| 二重化(ミラーリング) | 2つのメモリ・バンクに対して常に同一データを書き込んでおく。一方のバンクで訂正不可能なエラーが発生したら、以後のアクセスをもう一方のバンクだけに切り替える | ホットスペアと効果は同様だが、冗長度が高いため、訂正不可能なメモリ・モジュールのエラーにも対応できる |
| RAID | RAID 3のように、パリティ情報を予備のメモリ・モジュールに格納することで、1枚のメモリ・モジュールでエラーが生じても、パリティ情報からデータを復元できる | ミラーリングと効果は同様だが、メモリ容量の利用効率に優れる |
| ホットスワップ | IAサーバを稼働させたまま、メモリ・モジュールを取り外して新しいものと交換できる。二重化(ミラーリング)やRAIDと組み合わせて利用される | メモリ・モジュール交換時にサービスを停止せずに済む |
| より高度なメモリ・エラー対策 | ||
| 一見すると、ディスク・サブシステム向けの耐障害性向上技術に見える。ハードディスクよりメモリ・モジュールの不良率はずっと低いはずだが、非常に多数のメモリ・モジュールを装着したり、より高度な可用性が必要だったりするなら、こうした技術が必要になってくるだろう。 | ||
これらの技術を実装するのは、まだコストがかかるので、しばらくはエンタープライズ(ハイエンド)に限定されるだろう。差別化のポイントとして重要なのは、こうしたエラー対策を実現する場合でもメモリ・モジュールは業界標準に沿った汎用品で済むことだ。さもないと、どんなにエラー対策が充実していても、装着すべきメモリ・モジュールが特殊なために高価になりがちで、また流用もまったく効かなくなって管理の負担になるからだ。
メモリの性能向上:DDR SDRAMの採用とインターリーブの一般化
IAサーバの場合、メイン・メモリの性能は、プロセッサがアプリケーションを実行するときの処理速度だけではなく、I/Oデバイスとメイン・メモリとの間のデータ転送速度、つまりI/Oデバイスのスループットにも影響を及ぼす。最近ではプロセッサの高速化に伴い、メイン・メモリがシステム性能のボトルネックになりつつある。動作クロックがGHzクラスのプロセッサでは、メイン・メモリのアクセスで100クロック以上も処理が止まってしまうという。そのため、キャッシュ・メモリの容量も増える傾向にあるが、メイン・メモリに関しても性能を向上させる技術が投入されている。
それはDDR SDRAMの採用だ。従来はPC100/PC133 SDRAM DIMMがIAサーバの主流だったが、2002年からはメーカーから一斉にPC1600 DDR SDRAM DIMM対応チップセットが発表され、普及が始まっている。これにより最大転送速度は800M〜1066Mbytes/sから1600Mbytes/sに向上している。
もう1つは、容量の増加や耐障害性の向上と同様の手法、すなわち複数のメモリ・バス(メモリ・バンク)を設け、両方同時にアクセスすることで帯域幅を倍増させる、というものだ。この技術をメモリ・インターリーブ(Memory Interleave)などと呼ぶ。
 |
| メモリ・インターリーブの仕組み |
| これは2ウェイ・インターリーブの例だ。2系統のメモリ・バス(2つのメモリ・バンク)に対して、図のように連続データを交互に割り振っておく。例えばプロセッサがデータ#1、#2、#3…という具合に連続してアクセスする場合、メモリ・コントローラは2つのバンクを同時にアクセスすることで1.6Gbytes/s×2=3.2Gbytes/sという速度でプロセッサにデータを転送できる。1バンク時に比べて2倍の速度を実現できるわけだ。 |
もちろん、上図で#1→#3→#5といった具合に、連続しないアドレスをアクセスしていく場合、転送速度は1バンクだけのレベルに近づいてしまう。もっとも、IAサーバではデータの局所性が比較的高く、プロセッサもI/Oデバイスも連続データをメモリと転送する機会が多いため、インターリーブの効果は現れやすいようだ。
ウェイ数が増えるほどインターリーブによる最大転送速度は向上する(限度はあるが)。しかし、1回の増設で単位となるメモリ・モジュールの枚数も増えるので注意が必要だ。例えば、4ウェイだと4枚単位でメモリ・モジュールを増設しなければならず、使い勝手が悪くなる。
メモリ・インターリーブはIAサーバではメジャーな技術で、以前から実装されている。2002年のIAサーバでは、ワークグループなら1〜2ウェイ、ミッドレンジ以上は2〜4ウェイ以上のインターリーブを実装することになるだろう。
2002年は、「3. 多様なIAサーバ向けプロセッサを把握する(2)」で述べたように、IAサーバのプロセッサはIntel Xeon/Xeon MPやMcKinleyに移行する。それに伴い、チップセットが変更になり、メモリ・サブシステムも大きな影響を受けることになる。メモリ・サブシステムは、サーバ全体の性能や可用性も左右するので、その動向にはプロセッサと同様、注目していく必要があるだろう。
次のページからは、拡張バス/スロットについて解説していく。
| 関連リンク | |
| Chipkillの技術情報資料 |
|
| 「System Insiderの特集」 |
- Intelと互換プロセッサとの戦いの歴史を振り返る (2017/6/28)
Intelのx86が誕生して約40年たつという。x86プロセッサは、互換プロセッサとの戦いでもあった。その歴史を簡単に振り返ってみよう - 第204回 人工知能がFPGAに恋する理由 (2017/5/25)
最近、人工知能(AI)のアクセラレータとしてFPGAを活用する動きがある。なぜCPUやGPUに加えて、FPGAが人工知能に活用されるのだろうか。その理由は? - IoT実用化への号砲は鳴った (2017/4/27)
スタートの号砲が鳴ったようだ。多くのベンダーからIoTを使った実証実験の発表が相次いでいる。あと半年もすれば、実用化へのゴールも見えてくるのだろうか? - スパコンの新しい潮流は人工知能にあり? (2017/3/29)
スパコン関連の発表が続いている。多くが「人工知能」をターゲットにしているようだ。人工知能向けのスパコンとはどのようなものなのか、最近の発表から見ていこう
|
|





