[運用]
|
|
POPFileで迷惑メールを分類する
以上のようなアプリケーション付属の迷惑メール分類システム以外に、独立した迷惑メールの分類システム(アプリケーション)もある。本稿で取り上げるPOPFileもその1つである。
 |
| POPFileの配布サイト |
| POPFileはフリーで配布されている、メールの自動分類システムである。これはPOPFileの日本語版ドキュメンテーション・プロジェクトのサイト。日本語関連ドキュメントが参照できる。 |
POPFileは、プロキシ型(代理型)の迷惑メールの分類システムである。メール・サーバとメール・クライアントの間に入り(中継し)、メール・サーバから送られてくるメール・データの内容を判断して、例えば迷惑メールなら件名に「spam」という文字列やメール・ヘッダを追加する、というふうに機能する。メール・クライアントは、この文字列を見るだけで、簡単に迷惑メールであると判断できるわけだ。
実際には、迷惑メールの分類にしか使えないものというわけではないのだが、一般的には迷惑メールの分類に使われることが多いし、こういう用途では非常に優れた性能を発揮する。使い方にもよるが、一般的な迷惑メールの分類作業ならば99%以上の精度で迷惑メールをより分けることができるだろう。本記事ではこのPOPFileを取り上げ、迷惑メールの分類のために利用する方法を紹介する。
POPFileが先のWindowsメールやOutlookの迷惑メール・フィルタと違うところは、最初にトレーニング作業を必要とするところにある。そのため導入初期には手間がかかるが、数十通から数百通の迷惑メールを「学習させる」と、以後はほぼ自動で迷惑メールを判定することができる。それでもときどきは判定を間違うことがあるが(特に新しいパターンの迷惑メールに遭遇したときなど)、その場合も手動で正しく分類し直してやれば、以後は正しく分類してくれる。
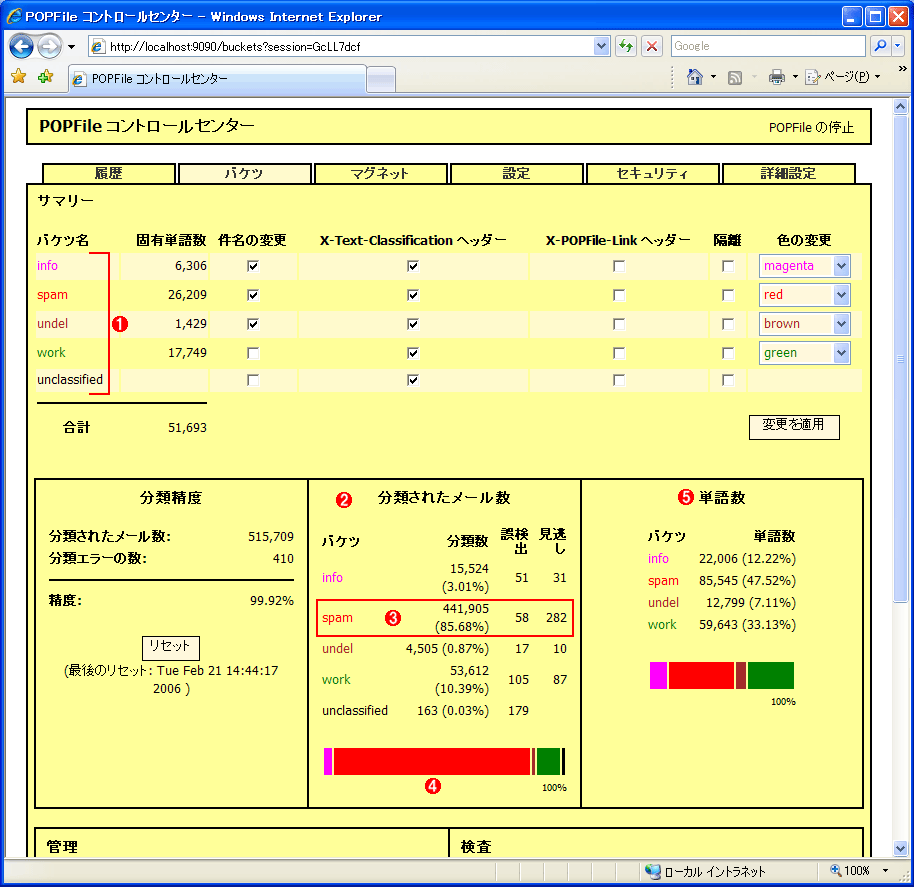
以下は、かなり使い込んだPOPFileの例である。99.9%の精度で、正しくメールを分類できていることが分かるだろう。日本語だけでなく、英語やそのほかの言語の迷惑メールでも、ほぼ間違いなく分類できている。
 |
|||||||||||||||
| 迷惑メールを分類するPOPFile | |||||||||||||||
| POPFileは、メールの本文やヘッダに含まれる文字列を単語に分解し、「バケツ(bucket)」に分類する機能を持つ。Outlookなどの「迷惑メール・フィルタ」と違い、スパム・メールを抽出するだけの機能を持っているわけではない。単語ごとにどのバケツに属する確率が高いかを調べ、さらにそれらを総合して、メールがどのバケツに最もふさわしいかを判断し、分類する。バケツの数や種類、どのメールをどのバケツに分類するかは、最初にユーザーがトレーニングさせる必要がある。この例では、分類精度は99.92%となっている。 | |||||||||||||||
|
POPFileの仕組み
POPFileは「ベイズ理論」を用いた、メールの分類フィルタ・システムである。ベイズ理論の詳細は省略するが、簡単にいうと、メール文中に現れる単語の発生確率に基づいて、どのような分野(POPFileでは「バケツ」という)に属するメールであるかを推定するシステムである。まず、迷惑メールに含まれる単語と通常メールに含まれる単語を調べ、それぞれの単語が属するメールの種類とその発生確率を辞書に登録しておく(トレーニングという)。次に、受信したメールを単語に分解し、それぞれの単語がどのバケツに属する可能性が高いかを辞書に基づいて判断する。その結果、最も近いバケツをそのメールの分類先とする。
例えば「出会い」「儲かる」などという単語は迷惑メールに含まれることが多いので、迷惑メールであると判断する。逆に「企画書」「スケジュール」などという単語は通常のメールに出現することが多いので、非迷惑メールであると判断する。どちらにも属するような単語やほとんど使われることがないような単語の場合は、判定の基準としては重視せず、そのほかの単語を重視して判定する、といった具合である。複数の単語のバケツごとの存在確率を総合して判定し、最終的にどのバケツが最もふさわしいかを決め、振り分ける。
 |
| POPFileの動作原理 |
| メールの本文やヘッダなどを単語に分解し、それをベイズ理論(ベイジアン・フィルタ)に基づいていくつかのバケツに振り分けている。メール中の単語ごとに、それがどのバケツに含まれる確率が高いかを辞書を参照して計算し、それらの結果から総合的に判断してメールを分類する。このときに使用される単語辞書は、最初にユーザーがトレーニングして学習させる。ただし判定不能な場合は(どのバケツとも一致度が低い場合は)、unclassifiedというデフォルトのバケツに分類する。 |
POPFileの分類精度を上げるためには、最初に十分なトレーニングが必要である。しかし一度トレーニングを行っておけば、非常に高い分類精度が得られる。これに対してWindowsメールの迷惑メール・フィルタはユーザーが学習させる必要はなく、初心者には便利だが、分類精度は高くない。どちらの方がユーザーにとって望ましいかは、ユーザーのスキルなどにもよるだろうが、大ざっぱにいうと、初心者には迷惑メール・フィルタ、トレーニングをしてでも精度を求める上級者にはPOPFileが向いているといえるだろう。
POPFileの利用形態
POPFileはメール・サーバとメール・クライアントの間に入ってその通信内容を変更するいわゆるプロキシ型(代理応答型)のネットワーク・アプリケーションである。メール・クライアントが発行したPOP3やIMAPなどのメール・プロトコルを解釈し、メール・サーバからの応答にメールの分類結果の情報を付加するという機能を持つ。図にすると次のような形態で利用する。
 |
| POPFileとメール・クライアントの関係 |
| 通常のメール・クライアントは、メール・サーバに対してPOP3プロトコルでアクセスするが、POPFileは、そのPOP3アクセス経路の途中に割り込む形で導入、運用される。メール・クライアントがPOPFileにPOP3プロトコルでアクセスすると、今度はPOPFileが実際のメール・サーバにPOP3でアクセスを中継する。そして中継の段階でメールの内容を調査し、該当するバケツを決定後、そのバケツに関する情報をメールのヘッダ部分(件名や特殊ヘッダなど)に追加して、メール・クライアントへ渡す。これにより、メール・クライアントでは、POPFileで分類/加工されたメールを受け取ることになる。 |
メール・クライアントから見れば、POPFileがメール・サーバのように見える。メール・サーバから見れば、POPFileが通常のメール・クライアントのように見える。
このような原理のため、POPFileはユーザーごとに動作させる必要があるし(分類の基準はユーザーごとに異なるため)、サーバ上で自動的に分類させるといった用途にも、(一般的には)使えない(不可能ではないが、最初に学習させる手順などが簡単ではない)。本稿では、一般のユーザー環境でPOPFileを利用する方法を紹介する。
| INDEX | ||
| [運用]POPFileで構築する迷惑メール・フィルタ | ||
| POPFileを導入して迷惑メールを分類する(前編) | ||
| 1.迷惑メールとその対策 | ||
| 2.迷惑メールの分類をサポートするPOPFile | ||
| 3.POPFileのインストール(1)―入手と機能の選択 | ||
| 4.POPFileのインストール(2)―初期バケツの作成 | ||
| 5.POPFileのインストール(3)―メール・アカウントの設定 | ||
| 6.POPFileの管理画面 | ||
| POPFileのトレーニングとメーラの設定(後編) | ||
| 1.POPFileのトレーニング(1) | ||
| 2.POPFileのトレーニング(2) | ||
| 3.メーラによるメールの分類 | ||
| 4.設定のカスタマイズと使いこなし | ||
| 運用 |
- Azure Web Appsの中を「コンソール」や「シェル」でのぞいてみる (2017/7/27)
AzureのWeb Appsはどのような仕組みで動いているのか、オンプレミスのWindows OSと何が違うのか、などをちょっと探訪してみよう - Azure Storage ExplorerでStorageを手軽に操作する (2017/7/24)
エクスプローラのような感覚でAzure Storageにアクセスできる無償ツール「Azure Storage Explorer」。いざというときに使えるよう、事前にセットアップしておこう - Win 10でキーボード配列が誤認識された場合の対処 (2017/7/21)
キーボード配列が異なる言語に誤認識された場合の対処方法を紹介。英語キーボードが日本語配列として認識された場合などは、正しいキー配列に設定し直そう - Azure Web AppsでWordPressをインストールしてみる (2017/7/20)
これまでのIaaSに続き、Azureの大きな特徴といえるPaaSサービス、Azure App Serviceを試してみた! まずはWordPressをインストールしてみる
|
|
注目のテーマ





